HyKGE: A Hypothesis Knowledge Graph Enhanced Framework for Accurate and Reliable Medical LLMs Responses
2312.15883
0
0
Abstract
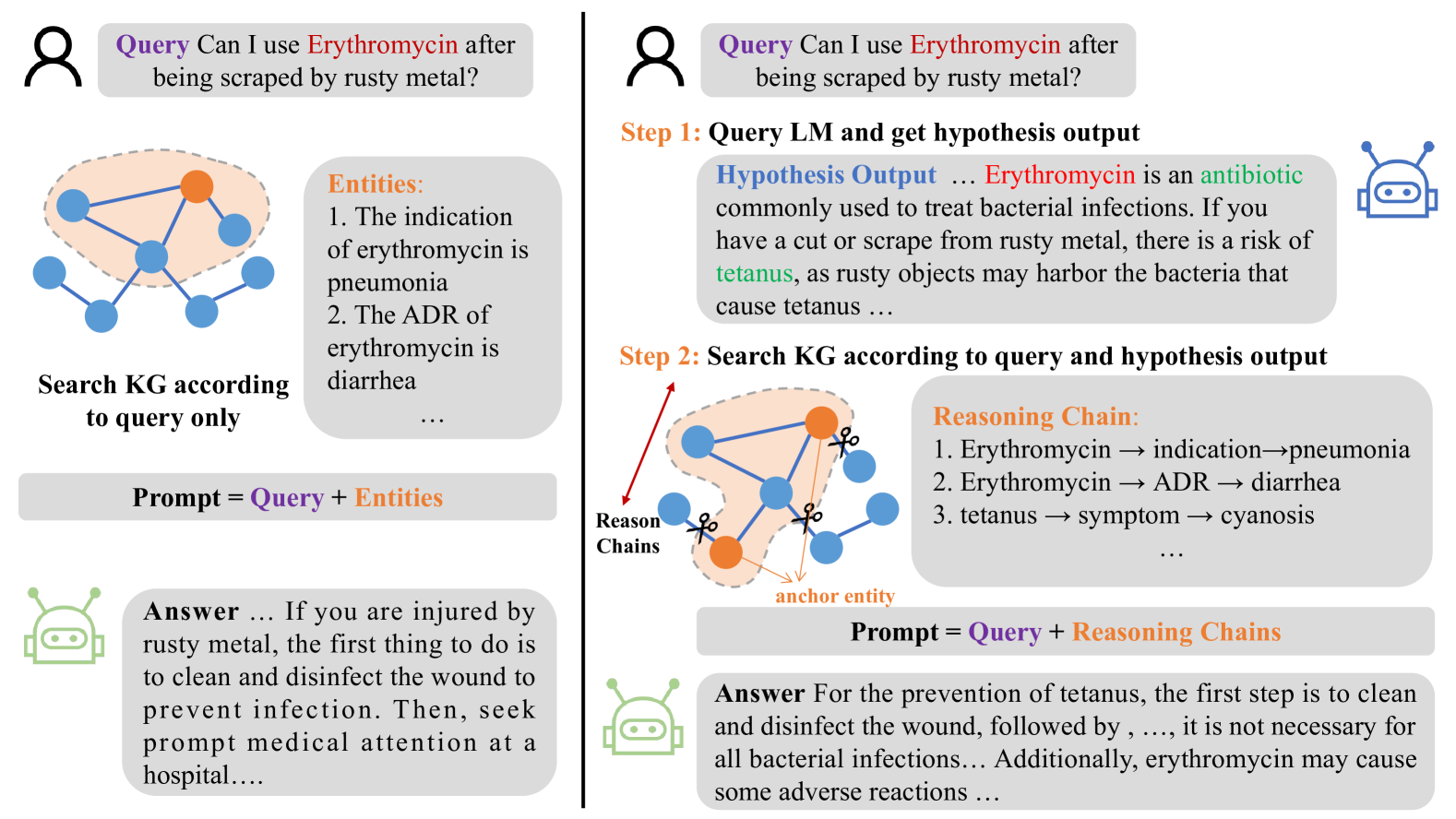
In this paper, we investigate the retrieval-augmented generation (RAG) based on Knowledge Graphs (KGs) to improve the accuracy and reliability of Large Language Models (LLMs). Recent approaches suffer from insufficient and repetitive knowledge retrieval, tedious and time-consuming query parsing, and monotonous knowledge utilization. To this end, we develop a Hypothesis Knowledge Graph Enhanced (HyKGE) framework, which leverages LLMs' powerful reasoning capacity to compensate for the incompleteness of user queries, optimizes the interaction process with LLMs, and provides diverse retrieved knowledge. Specifically, HyKGE explores the zero-shot capability and the rich knowledge of LLMs with Hypothesis Outputs to extend feasible exploration directions in the KGs, as well as the carefully curated prompt to enhance the density and efficiency of LLMs' responses. Furthermore, we introduce the HO Fragment Granularity-aware Rerank Module to filter out noise while ensuring the balance between diversity and relevance in retrieved knowledge. Experiments on two Chinese medical multiple-choice question datasets and one Chinese open-domain medical Q&A dataset with two LLM turbos demonstrate the superiority of HyKGE in terms of accuracy and explainability.
Create account to get full access
Overview
- The paper presents a hypothesis knowledge graph enhanced medical language model, called "Think and Retrieval", which aims to improve the performance of large language models in medical question-answering tasks.
- The key idea is to leverage a knowledge graph to guide the language model's reasoning and retrieval process, allowing it to better understand and respond to medical queries.
- The authors evaluate their approach on several medical question-answering benchmarks and demonstrate improved performance compared to existing language models.
Plain English Explanation
The paper describes a new approach to building better language models for medical question-answering. The core idea is to combine a large language model with a structured knowledge graph that captures medical concepts and their relationships. By using this knowledge graph to guide the language model's reasoning and retrieval process, the system can better understand and respond to medical questions.
The authors start by training a large language model on a broad corpus of medical text. They then create a knowledge graph that represents key medical concepts, diseases, treatments, and the connections between them. This knowledge graph acts as a kind of "map" that the language model can use to navigate the medical domain and find relevant information to answer questions.
When a user asks a medical question, the system first uses the language model to understand the query. It then leverages the knowledge graph to identify relevant concepts and retrieve pertinent information to formulate a response. This hybrid approach of language understanding and structured knowledge allows the system to provide more accurate and informative answers compared to a standalone language model.
The authors evaluate their "Think and Retrieval" system on several benchmark datasets for medical question-answering. They show that it outperforms other state-of-the-art language models, particularly on questions that require more complex reasoning or the integration of multiple pieces of information.
Technical Explanation
The paper introduces a novel architecture called "Think and Retrieval" that combines a large language model with a knowledge graph to enhance medical question-answering capabilities. The key components of the system are:
-
Pre-trained Language Model: The authors start with a large, pre-trained language model (e.g., BERT, GPT) that has been trained on a broad corpus of medical text. This provides the foundational language understanding and generation capabilities.
-
Hypothesis Knowledge Graph: The authors construct a knowledge graph that represents key medical concepts, diseases, treatments, and their relationships. This graph serves as a structured representation of medical knowledge that can be leveraged by the language model.
-
Knowledge-Guided Reasoning: When a user query is input, the language model first tries to understand the question. It then uses the knowledge graph to identify relevant concepts and retrieve pertinent information to formulate a response. This hybrid approach of language understanding and structured knowledge allows the system to provide more accurate and informative answers.
The authors evaluate their "Think and Retrieval" system on several benchmark datasets for medical question-answering, including MedQA, MedHop, and COVID-QA. They show that it outperforms other state-of-the-art language models, particularly on questions that require more complex reasoning or the integration of multiple pieces of information.
Critical Analysis
The paper presents a promising approach to enhancing large language models for medical question-answering tasks. The key strength of the "Think and Retrieval" system is its ability to leverage structured knowledge, represented in the form of a knowledge graph, to guide the language model's reasoning and retrieval process.
One potential limitation of the approach is the reliance on a manually-constructed knowledge graph. While the authors demonstrate the effectiveness of this graph, it may be challenging to scale and maintain such a resource, especially as medical knowledge rapidly evolves. An interesting area for future research could be to explore methods for automatically constructing and updating the knowledge graph from various data sources.
Additionally, the paper does not provide a detailed analysis of the types of questions or scenarios where the "Think and Retrieval" system excels compared to standalone language models. Further research could shed light on the specific capabilities and limitations of the proposed approach, as well as its potential to generalize to other domains beyond medicine.
Conclusion
The "Think and Retrieval" system presented in this paper represents a compelling approach to enhancing the performance of large language models on medical question-answering tasks. By leveraging a knowledge graph to guide the model's reasoning and retrieval process, the system can better understand and respond to complex medical queries.
The authors' evaluation results demonstrate the potential of this hybrid approach, which combines the language understanding capabilities of a large language model with the structured knowledge representation of a domain-specific knowledge graph. As language models continue to play an increasingly important role in various healthcare and medical applications, innovations like "Think and Retrieval" could have significant implications for improving the accuracy, reliability, and interpretability of these systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🛸
Biomedical knowledge graph-optimized prompt generation for large language models
Karthik Soman, Peter W Rose, John H Morris, Rabia E Akbas, Brett Smith, Braian Peetoom, Catalina Villouta-Reyes, Gabriel Cerono, Yongmei Shi, Angela Rizk-Jackson, Sharat Israni, Charlotte A Nelson, Sui Huang, Sergio E Baranzini
0
0
Large Language Models (LLMs) are being adopted at an unprecedented rate, yet still face challenges in knowledge-intensive domains like biomedicine. Solutions such as pre-training and domain-specific fine-tuning add substantial computational overhead, requiring further domain expertise. Here, we introduce a token-optimized and robust Knowledge Graph-based Retrieval Augmented Generation (KG-RAG) framework by leveraging a massive biomedical KG (SPOKE) with LLMs such as Llama-2-13b, GPT-3.5-Turbo and GPT-4, to generate meaningful biomedical text rooted in established knowledge. Compared to the existing RAG technique for Knowledge Graphs, the proposed method utilizes minimal graph schema for context extraction and uses embedding methods for context pruning. This optimization in context extraction results in more than 50% reduction in token consumption without compromising the accuracy, making a cost-effective and robust RAG implementation on proprietary LLMs. KG-RAG consistently enhanced the performance of LLMs across diverse biomedical prompts by generating responses rooted in established knowledge, accompanied by accurate provenance and statistical evidence (if available) to substantiate the claims. Further benchmarking on human curated datasets, such as biomedical true/false and multiple-choice questions (MCQ), showed a remarkable 71% boost in the performance of the Llama-2 model on the challenging MCQ dataset, demonstrating the framework's capacity to empower open-source models with fewer parameters for domain specific questions. Furthermore, KG-RAG enhanced the performance of proprietary GPT models, such as GPT-3.5 and GPT-4. In summary, the proposed framework combines explicit and implicit knowledge of KG and LLM in a token optimized fashion, thus enhancing the adaptability of general-purpose LLMs to tackle domain-specific questions in a cost-effective fashion.
5/15/2024

KG-RAG: Bridging the Gap Between Knowledge and Creativity
Diego Sanmartin
0
0
Ensuring factual accuracy while maintaining the creative capabilities of Large Language Model Agents (LMAs) poses significant challenges in the development of intelligent agent systems. LMAs face prevalent issues such as information hallucinations, catastrophic forgetting, and limitations in processing long contexts when dealing with knowledge-intensive tasks. This paper introduces a KG-RAG (Knowledge Graph-Retrieval Augmented Generation) pipeline, a novel framework designed to enhance the knowledge capabilities of LMAs by integrating structured Knowledge Graphs (KGs) with the functionalities of LLMs, thereby significantly reducing the reliance on the latent knowledge of LLMs. The KG-RAG pipeline constructs a KG from unstructured text and then performs information retrieval over the newly created graph to perform KGQA (Knowledge Graph Question Answering). The retrieval methodology leverages a novel algorithm called Chain of Explorations (CoE) which benefits from LLMs reasoning to explore nodes and relationships within the KG sequentially. Preliminary experiments on the ComplexWebQuestions dataset demonstrate notable improvements in the reduction of hallucinated content and suggest a promising path toward developing intelligent systems adept at handling knowledge-intensive tasks.
5/21/2024

Cross-Data Knowledge Graph Construction for LLM-enabled Educational Question-Answering System: A~Case~Study~at~HCMUT
Tuan Bui, Oanh Tran, Phuong Nguyen, Bao Ho, Long Nguyen, Thang Bui, Tho Quan
0
0
In today's rapidly evolving landscape of Artificial Intelligence, large language models (LLMs) have emerged as a vibrant research topic. LLMs find applications in various fields and contribute significantly. Despite their powerful language capabilities, similar to pre-trained language models (PLMs), LLMs still face challenges in remembering events, incorporating new information, and addressing domain-specific issues or hallucinations. To overcome these limitations, researchers have proposed Retrieval-Augmented Generation (RAG) techniques, some others have proposed the integration of LLMs with Knowledge Graphs (KGs) to provide factual context, thereby improving performance and delivering more accurate feedback to user queries. Education plays a crucial role in human development and progress. With the technology transformation, traditional education is being replaced by digital or blended education. Therefore, educational data in the digital environment is increasing day by day. Data in higher education institutions are diverse, comprising various sources such as unstructured/structured text, relational databases, web/app-based API access, etc. Constructing a Knowledge Graph from these cross-data sources is not a simple task. This article proposes a method for automatically constructing a Knowledge Graph from multiple data sources and discusses some initial applications (experimental trials) of KG in conjunction with LLMs for question-answering tasks.
4/16/2024
Enhancing Question Answering for Enterprise Knowledge Bases using Large Language Models
Feihu Jiang, Chuan Qin, Kaichun Yao, Chuyu Fang, Fuzhen Zhuang, Hengshu Zhu, Hui Xiong
0
0
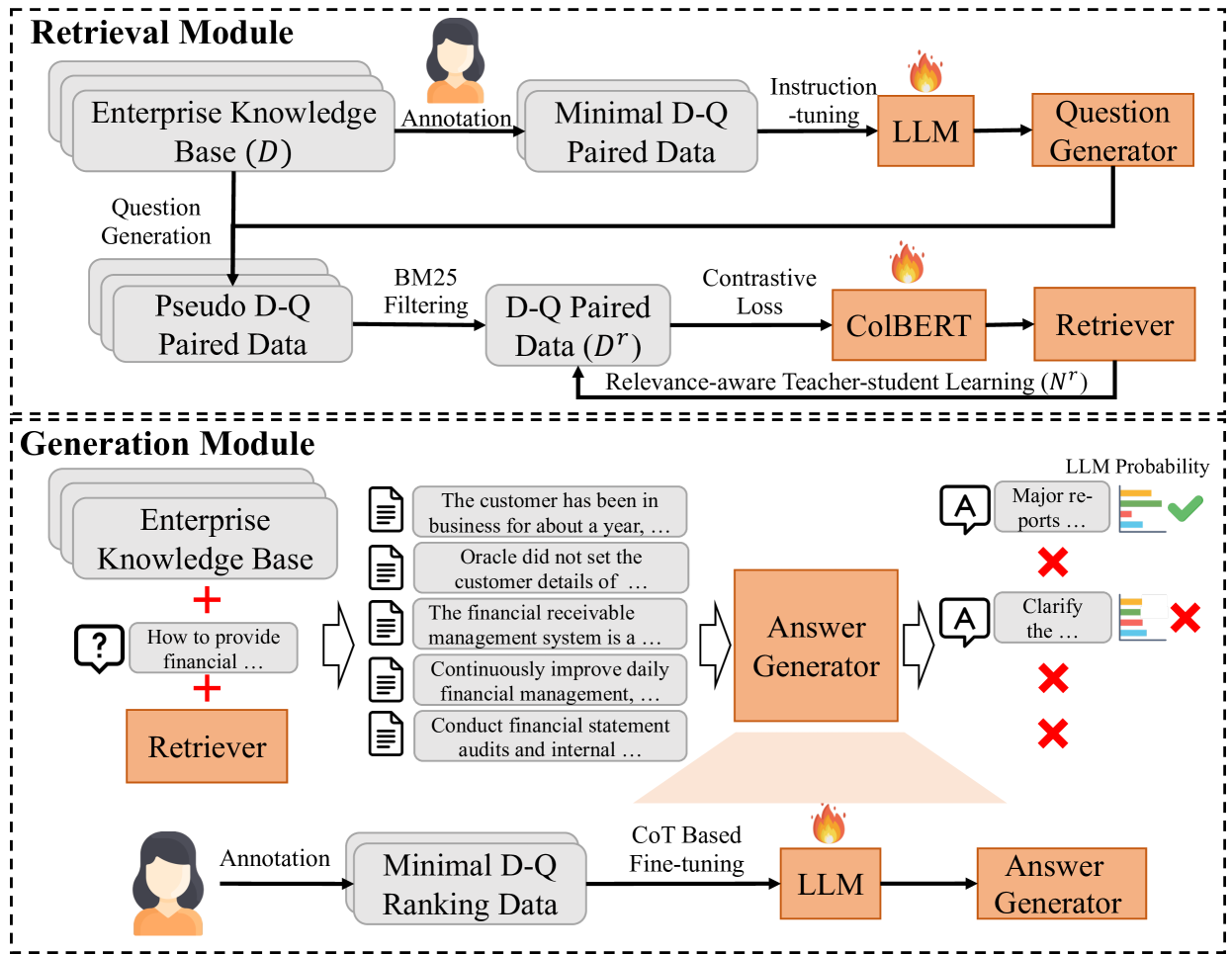
Efficient knowledge management plays a pivotal role in augmenting both the operational efficiency and the innovative capacity of businesses and organizations. By indexing knowledge through vectorization, a variety of knowledge retrieval methods have emerged, significantly enhancing the efficacy of knowledge management systems. Recently, the rapid advancements in generative natural language processing technologies paved the way for generating precise and coherent answers after retrieving relevant documents tailored to user queries. However, for enterprise knowledge bases, assembling extensive training data from scratch for knowledge retrieval and generation is a formidable challenge due to the privacy and security policies of private data, frequently entailing substantial costs. To address the challenge above, in this paper, we propose EKRG, a novel Retrieval-Generation framework based on large language models (LLMs), expertly designed to enable question-answering for Enterprise Knowledge bases with limited annotation costs. Specifically, for the retrieval process, we first introduce an instruction-tuning method using an LLM to generate sufficient document-question pairs for training a knowledge retriever. This method, through carefully designed instructions, efficiently generates diverse questions for enterprise knowledge bases, encompassing both fact-oriented and solution-oriented knowledge. Additionally, we develop a relevance-aware teacher-student learning strategy to further enhance the efficiency of the training process. For the generation process, we propose a novel chain of thought (CoT) based fine-tuning method to empower the LLM-based generator to adeptly respond to user questions using retrieved documents. Finally, extensive experiments on real-world datasets have demonstrated the effectiveness of our proposed framework.
4/23/2024