HyperMM : Robust Multimodal Learning with Varying-sized Inputs

0
Sign in to get full access
Overview
- Presents HyperMM, a robust multimodal learning approach that can handle varying-sized inputs across modalities
- Addresses the challenge of missing modalities during training and inference
- Proposes a hypernetwork-based architecture to learn modality-specific feature representations and their interactions
Plain English Explanation
HyperMM is a new machine learning technique that can work with data from multiple sources, even when some of the data is missing. In many real-world applications, we have to deal with data from different modalities (like text, images, and audio) that can vary in size and completeness. HyperMM is designed to handle these challenges.
The key idea behind HyperMM is to use a hypernetwork - a neural network that can generate the weights of another neural network. This allows HyperMM to learn modality-specific feature representations and how they interact, even when some modalities are missing during training or inference.
By using this hypernetwork approach, HyperMM can be more robust to missing data compared to traditional multimodal learning methods. This makes it a promising technique for applications where data from different sources needs to be combined, like in healthcare, finance, or multimedia analysis.
Technical Explanation
HyperMM uses a hypernetwork-based architecture to learn modality-specific feature representations and their interactions. The hypernetwork takes in the available modalities and generates the weights of a modality-specific feature extractor network for each modality. This allows the model to adapt its feature extraction to the specific characteristics of each modality, even when some modalities are missing.
The interaction between the modalities is captured by another network that takes the modality-specific features and produces the final prediction. By using the hypernetwork to generate the weights of this interaction network, HyperMM can learn how the modalities relate to each other and leverage their complementary information, even in the presence of missing modalities.
The authors evaluate HyperMM on several multimodal benchmarks and show that it outperforms existing methods in terms of accuracy and robustness to missing modalities. The hypernetwork-based approach allows HyperMM to adapt to the available data and learn effective feature representations and interactions, making it a promising solution for real-world multimodal learning challenges.
Critical Analysis
The paper provides a thorough evaluation of HyperMM on several multimodal datasets, demonstrating its advantages over existing approaches. However, the authors acknowledge that the hypernetwork-based architecture adds some computational complexity compared to simpler multimodal fusion methods.
Additionally, the paper does not address how HyperMM would scale to larger and more diverse multimodal datasets, or how it would handle more than just missing modalities, such as noisy or incomplete data within a modality. Further research could explore these aspects to better understand the practical limitations and potential extensions of the HyperMM approach.
Conclusion
HyperMM presents a novel hypernetwork-based solution for robust multimodal learning in the presence of varying-sized and missing inputs. By adapting the feature extraction and modality interaction to the available data, HyperMM can outperform traditional multimodal methods and offers a promising direction for addressing real-world multimodal learning challenges. The insights from this research could inspire further developments in flexible and adaptive multimodal learning systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
HyperMM : Robust Multimodal Learning with Varying-sized Inputs
Hava Chaptoukaev, Vincenzo Marcian'o, Francesco Galati, Maria A. Zuluaga
Combining multiple modalities carrying complementary information through multimodal learning (MML) has shown considerable benefits for diagnosing multiple pathologies. However, the robustness of multimodal models to missing modalities is often overlooked. Most works assume modality completeness in the input data, while in clinical practice, it is common to have incomplete modalities. Existing solutions that address this issue rely on modality imputation strategies before using supervised learning models. These strategies, however, are complex, computationally costly and can strongly impact subsequent prediction models. Hence, they should be used with parsimony in sensitive applications such as healthcare. We propose HyperMM, an end-to-end framework designed for learning with varying-sized inputs. Specifically, we focus on the task of supervised MML with missing imaging modalities without using imputation before training. We introduce a novel strategy for training a universal feature extractor using a conditional hypernetwork, and propose a permutation-invariant neural network that can handle inputs of varying dimensions to process the extracted features, in a two-phase task-agnostic framework. We experimentally demonstrate the advantages of our method in two tasks: Alzheimer's disease detection and breast cancer classification. We demonstrate that our strategy is robust to high rates of missing data and that its flexibility allows it to handle varying-sized datasets beyond the scenario of missing modalities.
Read more7/31/2024

0
Modality Invariant Multimodal Learning to Handle Missing Modalities: A Single-Branch Approach
Muhammad Saad Saeed, Shah Nawaz, Muhammad Zaigham Zaheer, Muhammad Haris Khan, Karthik Nandakumar, Muhammad Haroon Yousaf, Hassan Sajjad, Tom De Schepper, Markus Schedl
Multimodal networks have demonstrated remarkable performance improvements over their unimodal counterparts. Existing multimodal networks are designed in a multi-branch fashion that, due to the reliance on fusion strategies, exhibit deteriorated performance if one or more modalities are missing. In this work, we propose a modality invariant multimodal learning method, which is less susceptible to the impact of missing modalities. It consists of a single-branch network sharing weights across multiple modalities to learn inter-modality representations to maximize performance as well as robustness to missing modalities. Extensive experiments are performed on four challenging datasets including textual-visual (UPMC Food-101, Hateful Memes, Ferramenta) and audio-visual modalities (VoxCeleb1). Our proposed method achieves superior performance when all modalities are present as well as in the case of missing modalities during training or testing compared to the existing state-of-the-art methods.
Read more8/15/2024
0
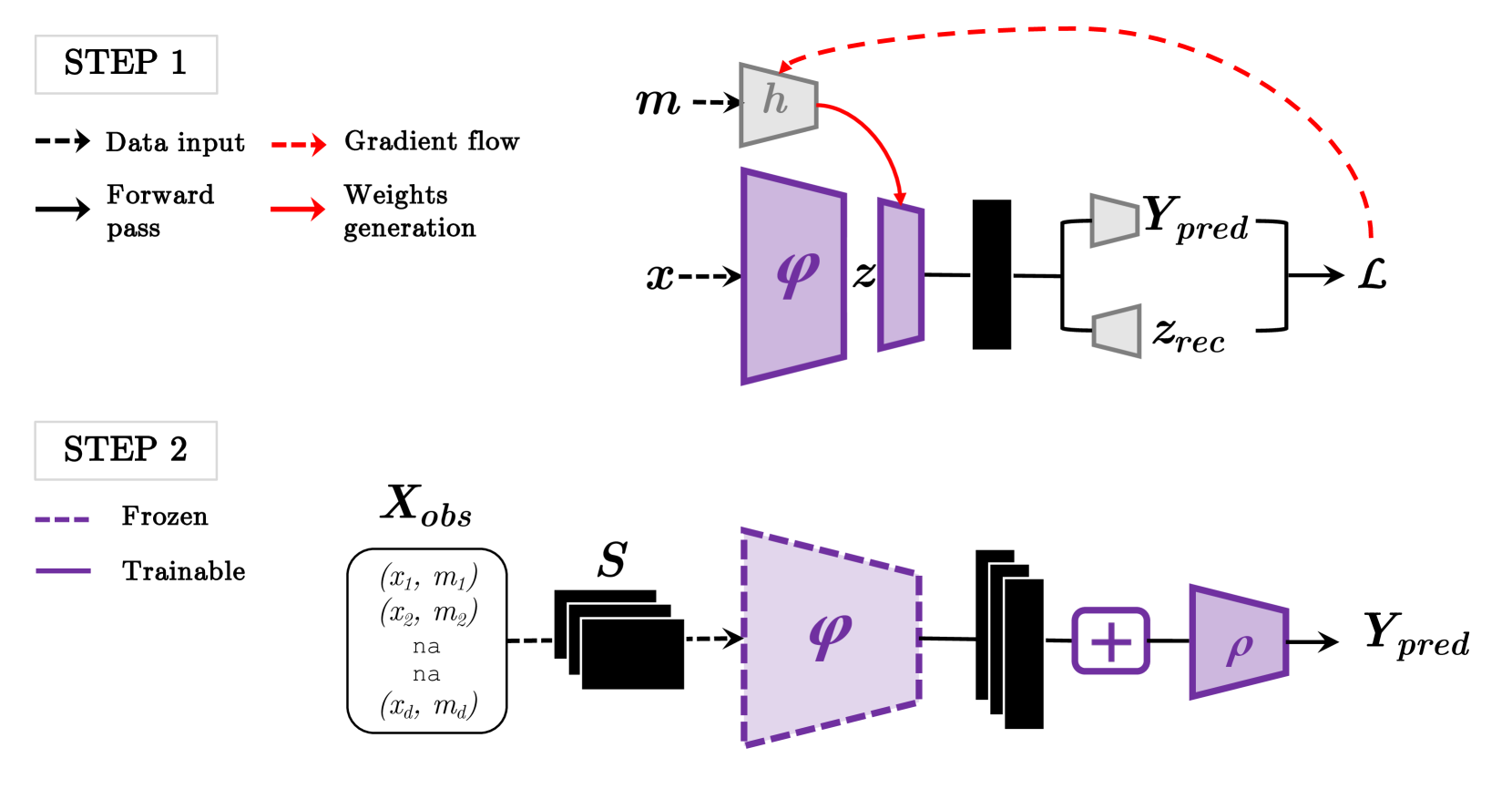
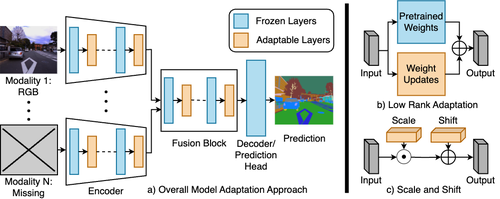
Robust Multimodal Learning with Missing Modalities via Parameter-Efficient Adaptation
Md Kaykobad Reza, Ashley Prater-Bennette, M. Salman Asif
Multimodal learning seeks to utilize data from multiple sources to improve the overall performance of downstream tasks. It is desirable for redundancies in the data to make multimodal systems robust to missing or corrupted observations in some correlated modalities. However, we observe that the performance of several existing multimodal networks significantly deteriorates if one or multiple modalities are absent at test time. To enable robustness to missing modalities, we propose a simple and parameter-efficient adaptation procedure for pretrained multimodal networks. In particular, we exploit modulation of intermediate features to compensate for the missing modalities. We demonstrate that such adaptation can partially bridge performance drop due to missing modalities and outperform independent, dedicated networks trained for the available modality combinations in some cases. The proposed adaptation requires extremely small number of parameters (e.g., fewer than 1% of the total parameters) and applicable to a wide range of modality combinations and tasks. We conduct a series of experiments to highlight the missing modality robustness of our proposed method on five different multimodal tasks across seven datasets. Our proposed method demonstrates versatility across various tasks and datasets, and outperforms existing methods for robust multimodal learning with missing modalities.
Read more7/30/2024
0
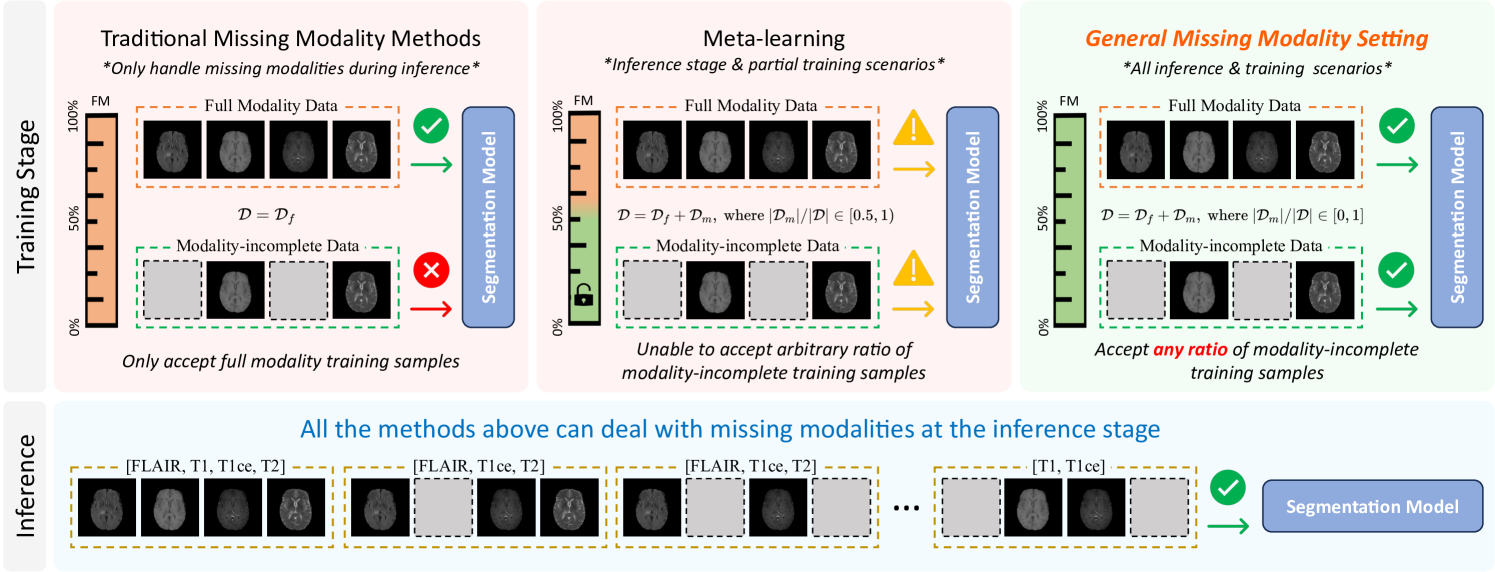
Dealing with All-stage Missing Modality: Towards A Universal Model with Robust Reconstruction and Personalization
Yunpeng Zhao, Cheng Chen, Qing You Pang, Quanzheng Li, Carol Tang, Beng-Ti Ang, Yueming Jin
Addressing missing modalities presents a critical challenge in multimodal learning. Current approaches focus on developing models that can handle modality-incomplete inputs during inference, assuming that the full set of modalities are available for all the data during training. This reliance on full-modality data for training limits the use of abundant modality-incomplete samples that are often encountered in practical settings. In this paper, we propose a robust universal model with modality reconstruction and model personalization, which can effectively tackle the missing modality at both training and testing stages. Our method leverages a multimodal masked autoencoder to reconstruct the missing modality and masked patches simultaneously, incorporating an innovative distribution approximation mechanism to fully utilize both modality-complete and modality-incomplete data. The reconstructed modalities then contributes to our designed data-model co-distillation scheme to guide the model learning in the presence of missing modalities. Moreover, we propose a CLIP-driven hyper-network to personalize partial model parameters, enabling the model to adapt to each distinct missing modality scenario. Our method has been extensively validated on two brain tumor segmentation benchmarks. Experimental results demonstrate the promising performance of our method, which consistently exceeds previous state-of-the-art approaches under the all-stage missing modality settings with different missing ratios. Code will be available.
Read more6/5/2024