Robust Multimodal Learning with Missing Modalities via Parameter-Efficient Adaptation

0
Sign in to get full access
Overview
- This paper presents a method for robust multimodal learning when some modalities are missing during inference.
- The proposed approach uses parameter-efficient adaptation to adapt a pre-trained multimodal model to handle missing modalities, without the need to retrain the entire model.
- Experiments on several multimodal benchmarks show the effectiveness of the proposed method in maintaining high performance even when some modalities are unavailable.
Plain English Explanation
In machine learning, multimodal learning refers to the process of using multiple types of data, such as images, text, and audio, to make predictions or draw insights. This can be a powerful approach, as different modalities can provide complementary information.
However, in real-world applications, it's common for some of these data sources to be unavailable or missing during the inference (or prediction) stage. The Robust Multimodal Learning with Missing Modalities via Parameter-Efficient Adaptation paper proposes a method to address this challenge.
The key idea is to use parameter-efficient adaptation, which means that instead of retraining the entire multimodal model from scratch, the researchers adapt a pre-trained model to handle missing modalities. This is more efficient and requires fewer computational resources.
The proposed method works by identifying the critical parameters in the pre-trained model that are most sensitive to the missing modalities, and then adjusting only those parameters to maintain high performance even when some modalities are unavailable. This allows the model to adapt to the new, incomplete data without having to be retrained from the ground up.
The researchers evaluate their approach on several multimodal benchmarks and demonstrate its effectiveness in maintaining high accuracy even when some modalities are missing during inference. This is an important advancement, as it makes multimodal learning more robust and practical for real-world applications where data availability can be inconsistent.
Technical Explanation
The paper proposes a parameter-efficient adaptation approach to enable robust multimodal learning when some modalities are missing during inference.
The key components of the proposed method are:
-
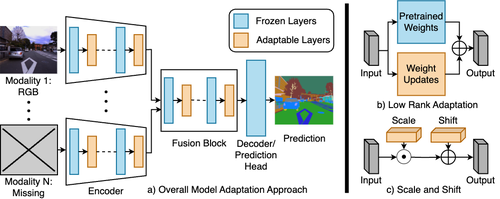
Modality-Specific Adaptation Layers: The authors introduce modality-specific adaptation layers that are added to the pre-trained multimodal model. These layers are designed to be lightweight and can be efficiently trained to adapt the model to handle missing modalities.
-
Modality Importance Estimation: The researchers develop a technique to estimate the importance of each modality in the pre-trained model. This allows them to identify the critical parameters that are most sensitive to the missing modalities, which are then targeted for adaptation.
-
Adaptation Optimization: The modality-specific adaptation layers are trained using an optimization process that minimizes the loss on the downstream task while preserving the knowledge from the pre-trained model as much as possible.
The authors evaluate their approach on several multimodal benchmarks, including emotion recognition, visual question answering, and video retrieval tasks. The results show that the proposed method can maintain high performance even when some modalities are missing during inference, outperforming alternative techniques that require retraining the entire model or using imputation methods to fill in the missing data.
Critical Analysis
The Robust Multimodal Learning with Missing Modalities via Parameter-Efficient Adaptation paper presents a compelling solution to a common challenge in multimodal learning. The key strengths of the proposed approach are its efficiency and its ability to maintain high performance even when some modalities are unavailable during inference.
One potential limitation of the method is that it relies on the availability of a pre-trained multimodal model. In some cases, such a model may not be accessible, and the researchers would need to train the initial model from scratch before applying their adaptation technique. Additionally, the effectiveness of the approach may depend on the quality and robustness of the pre-trained model, as well as the specific characteristics of the downstream task and dataset.
Furthermore, the paper does not extensively explore the
Overall, the Robust Multimodal Learning with Missing Modalities via Parameter-Efficient Adaptation paper presents a valuable contribution to the field of multimodal learning, addressing an important practical challenge. The proposed technique offers a promising approach to making multimodal models more robust and adaptable in real-world applications.
Conclusion
The Robust Multimodal Learning with Missing Modalities via Parameter-Efficient Adaptation paper introduces a novel method for enabling robust multimodal learning when some modalities are missing during inference. By using parameter-efficient adaptation, the approach can maintain high performance without the need to retrain the entire model from scratch.
The key innovation is the use of modality-specific adaptation layers and a technique to estimate the importance of each modality, which allows the model to efficiently adapt to handle missing data. Experimental results on several multimodal benchmarks demonstrate the effectiveness of the proposed method, making it a valuable contribution to the field of multimodal learning.
While the paper presents a compelling solution, it also suggests opportunities for further research, such as exploring the limits of the approach when multiple modalities are missing or when the missing modalities change dynamically. Overall, this work represents an important step towards more robust and practical multimodal learning systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Robust Multimodal Learning with Missing Modalities via Parameter-Efficient Adaptation
Md Kaykobad Reza, Ashley Prater-Bennette, M. Salman Asif
Multimodal learning seeks to utilize data from multiple sources to improve the overall performance of downstream tasks. It is desirable for redundancies in the data to make multimodal systems robust to missing or corrupted observations in some correlated modalities. However, we observe that the performance of several existing multimodal networks significantly deteriorates if one or multiple modalities are absent at test time. To enable robustness to missing modalities, we propose a simple and parameter-efficient adaptation procedure for pretrained multimodal networks. In particular, we exploit modulation of intermediate features to compensate for the missing modalities. We demonstrate that such adaptation can partially bridge performance drop due to missing modalities and outperform independent, dedicated networks trained for the available modality combinations in some cases. The proposed adaptation requires extremely small number of parameters (e.g., fewer than 1% of the total parameters) and applicable to a wide range of modality combinations and tasks. We conduct a series of experiments to highlight the missing modality robustness of our proposed method on five different multimodal tasks across seven datasets. Our proposed method demonstrates versatility across various tasks and datasets, and outperforms existing methods for robust multimodal learning with missing modalities.
Read more7/30/2024
0
Missing Modality Prediction for Unpaired Multimodal Learning via Joint Embedding of Unimodal Models
Donggeun Kim, Taesup Kim
Multimodal learning typically relies on the assumption that all modalities are fully available during both the training and inference phases. However, in real-world scenarios, consistently acquiring complete multimodal data presents significant challenges due to various factors. This often leads to the issue of missing modalities, where data for certain modalities are absent, posing considerable obstacles not only for the availability of multimodal pretrained models but also for their fine-tuning and the preservation of robustness in downstream tasks. To address these challenges, we propose a novel framework integrating parameter-efficient fine-tuning of unimodal pretrained models with a self-supervised joint-embedding learning method. This framework enables the model to predict the embedding of a missing modality in the representation space during inference. Our method effectively predicts the missing embedding through prompt tuning, leveraging information from available modalities. We evaluate our approach on several multimodal benchmark datasets and demonstrate its effectiveness and robustness across various scenarios of missing modalities.
Read more7/18/2024

0
Modality Invariant Multimodal Learning to Handle Missing Modalities: A Single-Branch Approach
Muhammad Saad Saeed, Shah Nawaz, Muhammad Zaigham Zaheer, Muhammad Haris Khan, Karthik Nandakumar, Muhammad Haroon Yousaf, Hassan Sajjad, Tom De Schepper, Markus Schedl
Multimodal networks have demonstrated remarkable performance improvements over their unimodal counterparts. Existing multimodal networks are designed in a multi-branch fashion that, due to the reliance on fusion strategies, exhibit deteriorated performance if one or more modalities are missing. In this work, we propose a modality invariant multimodal learning method, which is less susceptible to the impact of missing modalities. It consists of a single-branch network sharing weights across multiple modalities to learn inter-modality representations to maximize performance as well as robustness to missing modalities. Extensive experiments are performed on four challenging datasets including textual-visual (UPMC Food-101, Hateful Memes, Ferramenta) and audio-visual modalities (VoxCeleb1). Our proposed method achieves superior performance when all modalities are present as well as in the case of missing modalities during training or testing compared to the existing state-of-the-art methods.
Read more8/15/2024
0
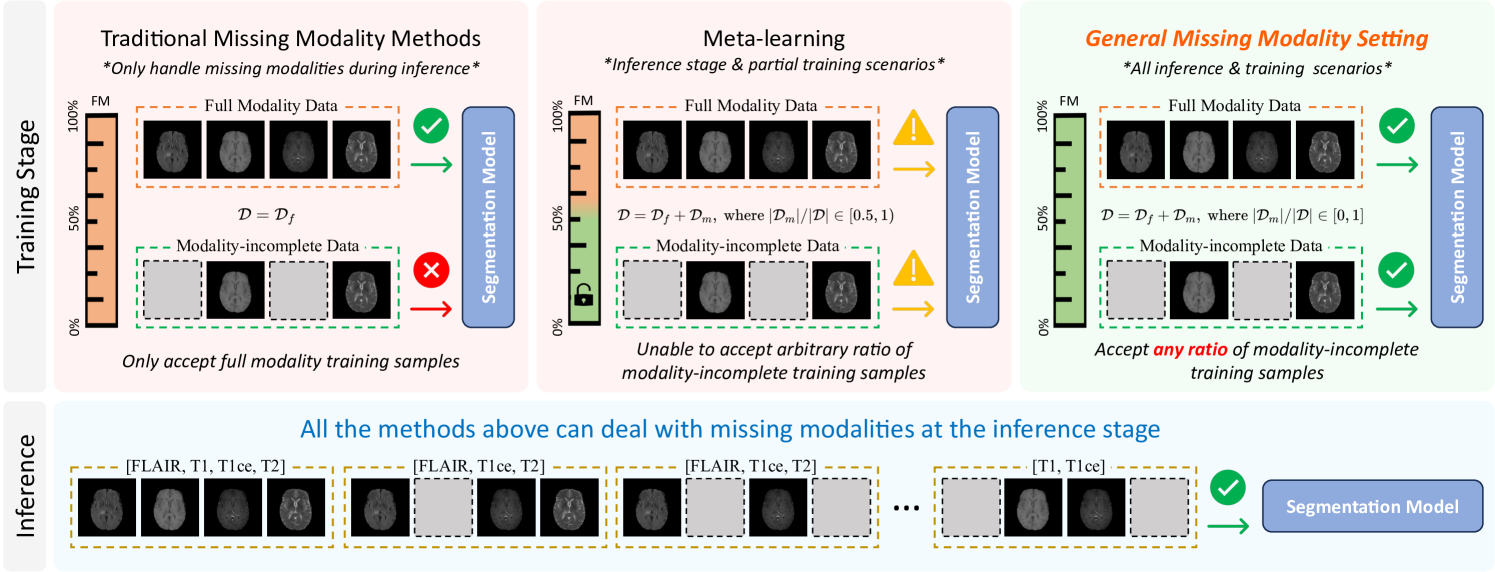
Dealing with All-stage Missing Modality: Towards A Universal Model with Robust Reconstruction and Personalization
Yunpeng Zhao, Cheng Chen, Qing You Pang, Quanzheng Li, Carol Tang, Beng-Ti Ang, Yueming Jin
Addressing missing modalities presents a critical challenge in multimodal learning. Current approaches focus on developing models that can handle modality-incomplete inputs during inference, assuming that the full set of modalities are available for all the data during training. This reliance on full-modality data for training limits the use of abundant modality-incomplete samples that are often encountered in practical settings. In this paper, we propose a robust universal model with modality reconstruction and model personalization, which can effectively tackle the missing modality at both training and testing stages. Our method leverages a multimodal masked autoencoder to reconstruct the missing modality and masked patches simultaneously, incorporating an innovative distribution approximation mechanism to fully utilize both modality-complete and modality-incomplete data. The reconstructed modalities then contributes to our designed data-model co-distillation scheme to guide the model learning in the presence of missing modalities. Moreover, we propose a CLIP-driven hyper-network to personalize partial model parameters, enabling the model to adapt to each distinct missing modality scenario. Our method has been extensively validated on two brain tumor segmentation benchmarks. Experimental results demonstrate the promising performance of our method, which consistently exceeds previous state-of-the-art approaches under the all-stage missing modality settings with different missing ratios. Code will be available.
Read more6/5/2024