Unified Multi-Modal Image Synthesis for Missing Modality Imputation

0
🖼️
Sign in to get full access
Overview
- Medical images from different modalities (e.g., MRI, CT) provide complementary information that can aid in disease screening and diagnosis.
- However, incomplete multi-modal images due to limited scanning time, image corruption, or different imaging protocols can limit the usefulness of multi-modal data for clinical applications.
- To address this issue, the paper proposes a novel method for synthesizing missing modalities from available modalities using a generative adversarial architecture.
Plain English Explanation
Medical images from different imaging techniques, like MRI and CT scans, can provide complementary information that helps doctors better understand and diagnose diseases. However, sometimes these multi-modal images are incomplete, with some of the imaging data missing. This can happen due to time constraints during the scan, problems with the imaging equipment, or differences in how the images were taken.
The researchers in this paper have developed a new way to "fill in the gaps" and generate the missing imaging data. Their method uses a type of artificial intelligence called a generative adversarial network (GAN) to create the missing imaging data based on the available information. The key innovations in their approach are:
-
Exploiting Both Commonality and Discrepancy: The generator in their GAN model is designed to capture both the shared features across imaging modalities (commonality) as well as the unique features of each modality (discrepancy). This helps ensure the generated images are anatomically consistent and also have realistic details.
-
Dynamic Feature Unification: Their model can handle a varying number of available modalities by intelligently combining the information from the provided modalities. This makes the model more robust to randomly missing modalities.
By addressing these challenges, the researchers' method is able to effectively synthesize missing modalities from incomplete multi-modal medical image data. This could be very useful for improving the diagnostic capabilities of medical imaging in cases where complete multi-modal data is not available.
Technical Explanation
The proposed method uses a generative adversarial network (GAN) architecture to synthesize missing modalities from any combination of available modalities. The key technical innovations are:
-
Commonality- and Discrepancy-Sensitive Encoder: The generator in the GAN model is designed with a specialized encoder that can capture both the modality-invariant commonalities and the modality-specific discrepancies in the input data. This allows the generator to produce images with consistent anatomy and realistic modality-specific details.
-
Dynamic Feature Unification Module: This module integrates information from a varying number of available modalities, enabling the network to be robust to random missing modalities. It performs both hard integration (concatenation) and soft integration (attention-based fusion) to ensure effective feature combination while avoiding information loss.
The proposed method is evaluated on two public multi-modal MRI datasets and demonstrates superior performance compared to previous approaches for multi-modal image synthesis and missing modality imputation.
Critical Analysis
The paper presents a technically sound approach to the important problem of synthesizing missing modalities in multi-modal medical imaging. The key strengths are the innovative encoder design and the dynamic feature unification module, which together enable the model to effectively leverage both shared and unique information across modalities.
However, the paper does not discuss potential limitations or caveats of the proposed method. For example, it is unclear how the model would perform on more diverse or complex medical imaging datasets beyond the two evaluated. Additionally, the paper does not address potential ethical concerns around the use of synthetic medical data, such as potential risks of misdiagnosis or overreliance on the generated images.
Further research could explore the robustness and generalizability of the method, as well as investigate safeguards and best practices for the clinical deployment of such multi-modal synthesis techniques.
Conclusion
This paper presents a novel unified approach for synthesizing missing modalities in multi-modal medical imaging. By capturing both commonalities and discrepancies across modalities, and dynamically integrating information from available modalities, the proposed method can effectively generate high-quality synthetic images to supplement incomplete multi-modal data.
This work addresses an important practical challenge in medical imaging and could potentially improve disease screening and diagnosis by enabling more comprehensive utilization of multi-modal data, even when some modalities are missing. Further research is needed to fully understand the capabilities and limitations of this approach, but it represents a promising step towards more robust and reliable multi-modal medical imaging analysis.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🖼️
0
Unified Multi-Modal Image Synthesis for Missing Modality Imputation
Yue Zhang, Chengtao Peng, Qiuli Wang, Dan Song, Kaiyan Li, S. Kevin Zhou
Multi-modal medical images provide complementary soft-tissue characteristics that aid in the screening and diagnosis of diseases. However, limited scanning time, image corruption and various imaging protocols often result in incomplete multi-modal images, thus limiting the usage of multi-modal data for clinical purposes. To address this issue, in this paper, we propose a novel unified multi-modal image synthesis method for missing modality imputation. Our method overall takes a generative adversarial architecture, which aims to synthesize missing modalities from any combination of available ones with a single model. To this end, we specifically design a Commonality- and Discrepancy-Sensitive Encoder for the generator to exploit both modality-invariant and specific information contained in input modalities. The incorporation of both types of information facilitates the generation of images with consistent anatomy and realistic details of the desired distribution. Besides, we propose a Dynamic Feature Unification Module to integrate information from a varying number of available modalities, which enables the network to be robust to random missing modalities. The module performs both hard integration and soft integration, ensuring the effectiveness of feature combination while avoiding information loss. Verified on two public multi-modal magnetic resonance datasets, the proposed method is effective in handling various synthesis tasks and shows superior performance compared to previous methods.
Read more7/10/2024
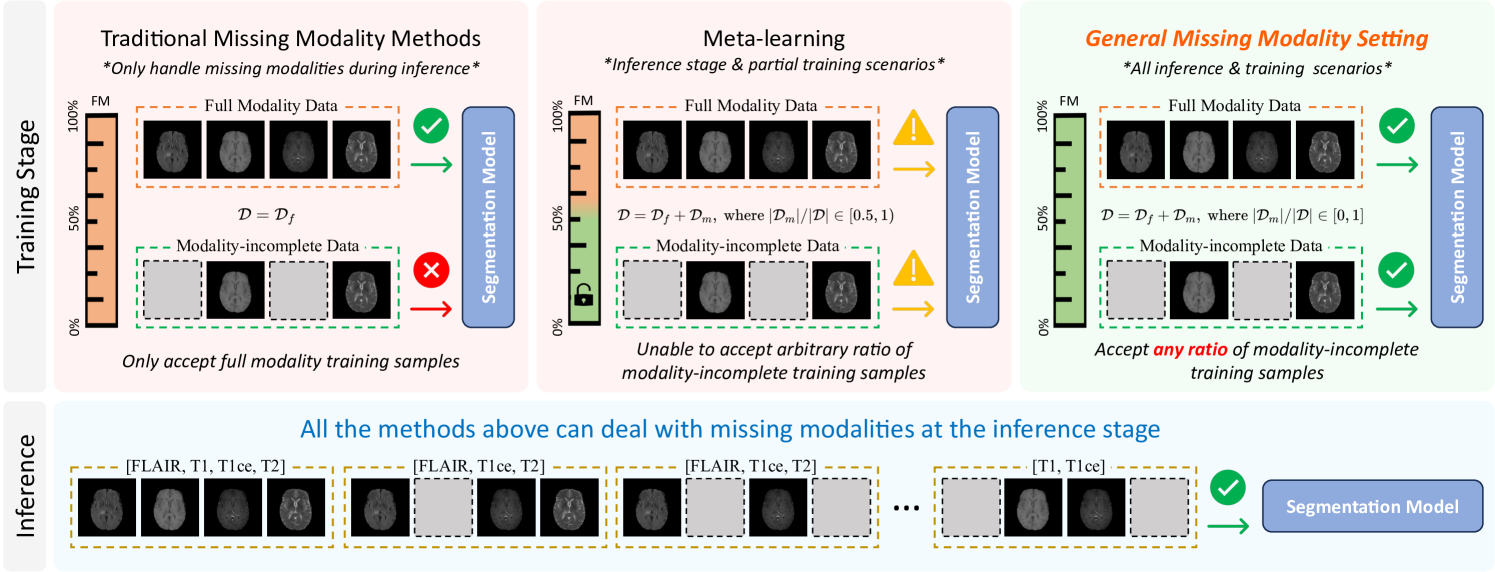
0
Dealing with All-stage Missing Modality: Towards A Universal Model with Robust Reconstruction and Personalization
Yunpeng Zhao, Cheng Chen, Qing You Pang, Quanzheng Li, Carol Tang, Beng-Ti Ang, Yueming Jin
Addressing missing modalities presents a critical challenge in multimodal learning. Current approaches focus on developing models that can handle modality-incomplete inputs during inference, assuming that the full set of modalities are available for all the data during training. This reliance on full-modality data for training limits the use of abundant modality-incomplete samples that are often encountered in practical settings. In this paper, we propose a robust universal model with modality reconstruction and model personalization, which can effectively tackle the missing modality at both training and testing stages. Our method leverages a multimodal masked autoencoder to reconstruct the missing modality and masked patches simultaneously, incorporating an innovative distribution approximation mechanism to fully utilize both modality-complete and modality-incomplete data. The reconstructed modalities then contributes to our designed data-model co-distillation scheme to guide the model learning in the presence of missing modalities. Moreover, we propose a CLIP-driven hyper-network to personalize partial model parameters, enabling the model to adapt to each distinct missing modality scenario. Our method has been extensively validated on two brain tumor segmentation benchmarks. Experimental results demonstrate the promising performance of our method, which consistently exceeds previous state-of-the-art approaches under the all-stage missing modality settings with different missing ratios. Code will be available.
Read more6/5/2024

0
Robust Semi-supervised Multimodal Medical Image Segmentation via Cross Modality Collaboration
Xiaogen Zhou, Yiyou Sun, Min Deng, Winnie Chiu Wing Chu, Qi Dou
Multimodal learning leverages complementary information derived from different modalities, thereby enhancing performance in medical image segmentation. However, prevailing multimodal learning methods heavily rely on extensive well-annotated data from various modalities to achieve accurate segmentation performance. This dependence often poses a challenge in clinical settings due to limited availability of such data. Moreover, the inherent anatomical misalignment between different imaging modalities further complicates the endeavor to enhance segmentation performance. To address this problem, we propose a novel semi-supervised multimodal segmentation framework that is robust to scarce labeled data and misaligned modalities. Our framework employs a novel cross modality collaboration strategy to distill modality-independent knowledge, which is inherently associated with each modality, and integrates this information into a unified fusion layer for feature amalgamation. With a channel-wise semantic consistency loss, our framework ensures alignment of modality-independent information from a feature-wise perspective across modalities, thereby fortifying it against misalignments in multimodal scenarios. Furthermore, our framework effectively integrates contrastive consistent learning to regulate anatomical structures, facilitating anatomical-wise prediction alignment on unlabeled data in semi-supervised segmentation tasks. Our method achieves competitive performance compared to other multimodal methods across three tasks: cardiac, abdominal multi-organ, and thyroid-associated orbitopathy segmentations. It also demonstrates outstanding robustness in scenarios involving scarce labeled data and misaligned modalities.
Read more9/5/2024
0
Missing Modality Prediction for Unpaired Multimodal Learning via Joint Embedding of Unimodal Models
Donggeun Kim, Taesup Kim
Multimodal learning typically relies on the assumption that all modalities are fully available during both the training and inference phases. However, in real-world scenarios, consistently acquiring complete multimodal data presents significant challenges due to various factors. This often leads to the issue of missing modalities, where data for certain modalities are absent, posing considerable obstacles not only for the availability of multimodal pretrained models but also for their fine-tuning and the preservation of robustness in downstream tasks. To address these challenges, we propose a novel framework integrating parameter-efficient fine-tuning of unimodal pretrained models with a self-supervised joint-embedding learning method. This framework enables the model to predict the embedding of a missing modality in the representation space during inference. Our method effectively predicts the missing embedding through prompt tuning, leveraging information from available modalities. We evaluate our approach on several multimodal benchmark datasets and demonstrate its effectiveness and robustness across various scenarios of missing modalities.
Read more7/18/2024