Hypothesis Search: Inductive Reasoning with Language Models

0
💬
Sign in to get full access
Overview
- This paper explores ways to improve the inductive reasoning capabilities of large language models (LLMs)
- Inductive reasoning is the ability to identify underlying principles from a few examples and apply them to novel scenarios
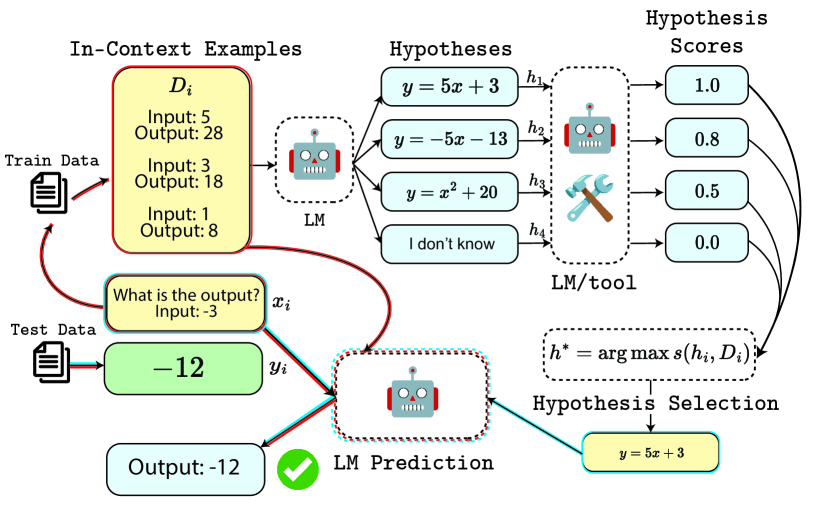
- The authors propose a pipeline where LLMs generate multiple levels of abstract hypotheses, which are then implemented as concrete Python programs and verified on examples
- This approach is evaluated on several inductive reasoning benchmarks, including the Abstraction and Reasoning Corpus (ARC)
Plain English Explanation
Humans have a remarkable ability to identify underlying patterns from just a few examples and then apply those insights to completely new situations. This capacity for inductive reasoning is a core part of how we solve problems and make sense of the world around us.
Recent work has explored whether large language models (LLMs) can also learn rules and generalize from limited data, often by directly prompting them with inductive reasoning tasks. While this approach works well for simple problems, it struggles on more complex challenges like the Abstraction and Reasoning Corpus (ARC).
In this paper, the authors propose a new technique to enhance the inductive reasoning abilities of LLMs. The key idea is to have the model generate multiple levels of abstract hypotheses about the problem, which are then translated into concrete computer programs. These programs can be tested on the observed examples and then applied to new scenarios.
To make this process more efficient, the authors experiment with steps to filter the hypothesis space, either by asking the LLM to summarize its ideas or by having human annotators select the most promising candidates. When evaluated on ARC and other benchmarks, this approach outperforms the direct prompting baseline, showing the benefits of both the abstract hypothesis generation and the concrete program representations.
Technical Explanation
The core of this work is a pipeline to improve the inductive reasoning capabilities of LLMs. It involves three main steps:
-
Abstract Hypothesis Generation: The LLM is prompted to propose multiple hypotheses about the underlying patterns or rules in the given inductive reasoning problem, expressed in natural language.
-
Concrete Program Representation: These natural language hypotheses are then implemented as concrete Python programs that can be executed on the observed examples.
-
Hypothesis Filtering: To reduce the search space, the authors experiment with two approaches to filter the set of hypotheses: either asking the LLM to summarize its ideas into a smaller set, or having human annotators select the most promising candidates.
This pipeline is evaluated on several inductive reasoning benchmarks, including the Abstraction and Reasoning Corpus (ARC), its 1D variant 1D-ARC, the String Transformation dataset SyGuS, and a List Transformation dataset.
On a 100-problem subset of ARC, the authors' automated pipeline using LLM-generated summaries achieves 30% accuracy, outperforming the direct prompting baseline (17%). When incorporating minimal human input to select from the LLM's candidates, performance is further boosted to 33%.
The authors' ablation studies demonstrate that both the abstract hypothesis generation and the concrete program representations contribute to the improved inductive reasoning capabilities.
Critical Analysis
The authors present a thoughtful approach to enhancing the inductive reasoning abilities of LLMs, which is an important and challenging problem in the field of artificial general intelligence.
One key limitation is that the proposed pipeline still struggles to achieve high performance on complex benchmarks like ARC, suggesting there is more work to be done to fully capture human-level inductive reasoning. The authors acknowledge this and encourage further research into more sophisticated hypothesis generation and filtering mechanisms.
Additionally, the reliance on human-annotated data for the hypothesis filtering step raises questions about the scalability and automation of the approach. Exploring ways to further reduce the need for human input would be an important direction for future work.
That said, the authors' core insight - combining abstract reasoning with concrete program representations - is a promising direction that could inspire new approaches to inductive logic programming and other areas of AI. Continued research in this area has the potential to bring us closer to artificial systems that can rival human-level inductive reasoning capabilities.
Conclusion
This paper presents a novel pipeline to enhance the inductive reasoning abilities of large language models. By prompting the models to generate multiple levels of abstract hypotheses and then implementing them as concrete programs, the authors demonstrate improved performance on a range of inductive reasoning benchmarks.
While there is still room for improvement, especially on more complex tasks, this work represents an important step forward in the quest to develop AI systems with human-like reasoning capabilities. The insights on combining abstract and concrete representations could inspire new directions in areas like program synthesis and deductive-inductive-abductive learning. As the field of AI continues to evolve, research like this will be crucial in pushing the boundaries of what's possible and bringing us closer to artificial general intelligence.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
0
Hypothesis Search: Inductive Reasoning with Language Models
Ruocheng Wang, Eric Zelikman, Gabriel Poesia, Yewen Pu, Nick Haber, Noah D. Goodman
Inductive reasoning is a core problem-solving capacity: humans can identify underlying principles from a few examples, which robustly generalize to novel scenarios. Recent work evaluates large language models (LLMs) on inductive reasoning tasks by directly prompting them yielding in context learning. This works well for straightforward inductive tasks but performs poorly on complex tasks such as the Abstraction and Reasoning Corpus (ARC). In this work, we propose to improve the inductive reasoning ability of LLMs by generating explicit hypotheses at multiple levels of abstraction: we prompt the LLM to propose multiple abstract hypotheses about the problem, in natural language, then implement the natural language hypotheses as concrete Python programs. These programs can be verified by running on observed examples and generalized to novel inputs. To reduce the hypothesis search space, we explore steps to filter the set of hypotheses to implement: we either ask the LLM to summarize them into a smaller set of hypotheses or ask human annotators to select a subset. We verify our pipeline's effectiveness on the ARC visual inductive reasoning benchmark, its variant 1D-ARC, string transformation dataset SyGuS, and list transformation dataset List Functions. On a random 100-problem subset of ARC, our automated pipeline using LLM summaries achieves 30% accuracy, outperforming the direct prompting baseline (accuracy of 17%). With the minimal human input of selecting from LLM-generated candidates, performance is boosted to 33%. Our ablations show that both abstract hypothesis generation and concrete program representations benefit LLMs on inductive reasoning tasks.
Read more6/3/2024
🧪
0
Phenomenal Yet Puzzling: Testing Inductive Reasoning Capabilities of Language Models with Hypothesis Refinement
Linlu Qiu, Liwei Jiang, Ximing Lu, Melanie Sclar, Valentina Pyatkin, Chandra Bhagavatula, Bailin Wang, Yoon Kim, Yejin Choi, Nouha Dziri, Xiang Ren
The ability to derive underlying principles from a handful of observations and then generalize to novel situations -- known as inductive reasoning -- is central to human intelligence. Prior work suggests that language models (LMs) often fall short on inductive reasoning, despite achieving impressive success on research benchmarks. In this work, we conduct a systematic study of the inductive reasoning capabilities of LMs through iterative hypothesis refinement, a technique that more closely mirrors the human inductive process than standard input-output prompting. Iterative hypothesis refinement employs a three-step process: proposing, selecting, and refining hypotheses in the form of textual rules. By examining the intermediate rules, we observe that LMs are phenomenal hypothesis proposers (i.e., generating candidate rules), and when coupled with a (task-specific) symbolic interpreter that is able to systematically filter the proposed set of rules, this hybrid approach achieves strong results across inductive reasoning benchmarks that require inducing causal relations, language-like instructions, and symbolic concepts. However, they also behave as puzzling inductive reasoners, showing notable performance gaps between rule induction (i.e., identifying plausible rules) and rule application (i.e., applying proposed rules to instances), suggesting that LMs are proposing hypotheses without being able to actually apply the rules. Through empirical and human analyses, we further reveal several discrepancies between the inductive reasoning processes of LMs and humans, shedding light on both the potentials and limitations of using LMs in inductive reasoning tasks.
Read more5/24/2024
0
An Incomplete Loop: Deductive, Inductive, and Abductive Learning in Large Language Models
Emmy Liu, Graham Neubig, Jacob Andreas
Modern language models (LMs) can learn to perform new tasks in different ways: in instruction following, the target task is described explicitly in natural language; in few-shot prompting, the task is specified implicitly with a small number of examples; in instruction inference, LMs are presented with in-context examples and are then prompted to generate a natural language task description before making predictions. Each of these procedures may be thought of as invoking a different form of reasoning: instruction following involves deductive reasoning, few-shot prompting involves inductive reasoning, and instruction inference involves abductive reasoning. How do these different capabilities relate? Across four LMs (from the gpt and llama families) and two learning problems (involving arithmetic functions and machine translation) we find a strong dissociation between the different types of reasoning: LMs can sometimes learn effectively from few-shot prompts even when they are unable to explain their own prediction rules; conversely, they sometimes infer useful task descriptions while completely failing to learn from human-generated descriptions of the same task. Our results highlight the non-systematic nature of reasoning even in some of today's largest LMs, and underscore the fact that very different learning mechanisms may be invoked by seemingly similar prompting procedures.
Read more8/30/2024

0
Inductive or Deductive? Rethinking the Fundamental Reasoning Abilities of LLMs
Kewei Cheng, Jingfeng Yang, Haoming Jiang, Zhengyang Wang, Binxuan Huang, Ruirui Li, Shiyang Li, Zheng Li, Yifan Gao, Xian Li, Bing Yin, Yizhou Sun
Reasoning encompasses two typical types: deductive reasoning and inductive reasoning. Despite extensive research into the reasoning capabilities of Large Language Models (LLMs), most studies have failed to rigorously differentiate between inductive and deductive reasoning, leading to a blending of the two. This raises an essential question: In LLM reasoning, which poses a greater challenge - deductive or inductive reasoning? While the deductive reasoning capabilities of LLMs, (i.e. their capacity to follow instructions in reasoning tasks), have received considerable attention, their abilities in true inductive reasoning remain largely unexplored. To investigate into the true inductive reasoning capabilities of LLMs, we propose a novel framework, SolverLearner. This framework enables LLMs to learn the underlying function (i.e., $y = f_w(x)$), that maps input data points $(x)$ to their corresponding output values $(y)$, using only in-context examples. By focusing on inductive reasoning and separating it from LLM-based deductive reasoning, we can isolate and investigate inductive reasoning of LLMs in its pure form via SolverLearner. Our observations reveal that LLMs demonstrate remarkable inductive reasoning capabilities through SolverLearner, achieving near-perfect performance with ACC of 1 in most cases. Surprisingly, despite their strong inductive reasoning abilities, LLMs tend to relatively lack deductive reasoning capabilities, particularly in tasks involving ``counterfactual'' reasoning.
Read more8/9/2024