I Bet You Did Not Mean That: Testing Semantic Importance via Betting

0

Sign in to get full access
Overview
- This paper proposes a novel approach for testing the semantic importance of language model outputs using a betting game.
- The authors introduce a "Semantic Importance Betting" (SIB) task, where human evaluators bet on the semantic importance of model-generated text.
- The SIB task aims to better assess the semantic significance of language model outputs compared to existing evaluation metrics.
- The authors conduct experiments on several language models and datasets to demonstrate the utility of the SIB approach.
Plain English Explanation
The paper presents a new way to evaluate the semantic importance of text generated by AI language models. Instead of just looking at standard metrics like how fluent or grammatically correct the text is, the authors introduce a "betting game" approach.
In this betting game, human participants are shown some text generated by a language model and are asked to "bet" on how semantically important or meaningful that text is. The higher they bet, the more they think the text is conveying an important idea or concept.
The key idea is that this betting game can provide a better sense of the semantic significance of the model's outputs, beyond just how well-written the text is. The authors argue this is an important complement to existing language model evaluation methods.
Through experiments on different language models and datasets, the paper demonstrates how the betting game approach can yield insights that other evaluation metrics miss. For example, the betting game may reveal that a language model is generating fluent but semantically unimportant text, which could guide future model development.
Technical Explanation
The paper introduces a new framework called "Semantic Importance Betting" (SIB) for evaluating the semantic significance of language model outputs. In the SIB task, human evaluators are shown a piece of text generated by a language model and asked to bet on how semantically important they think that text is.
The key innovation is that the betting stakes scale with the evaluators' judgments of semantic importance. Evaluators can bet higher amounts if they believe the text contains highly meaningful content, or lower amounts if they judge the text to be less semantically significant. This betting game provides a richer signal about the semantic value of the model's outputs compared to standard evaluations.
The authors conduct experiments on several language models (including GPT-2, InstructGPT, and BART) and datasets. They find that the SIB task can identify cases where models generate fluent but semantically unimportant text, which existing metrics may miss. The betting game also provides insights into how evaluators perceive the meaning and significance of model-generated content.
Critical Analysis
The paper presents a compelling new framework for evaluating language models that goes beyond traditional metrics. The SIB approach seems well-designed to capture nuanced judgments of semantic importance that can complement existing evaluation methods like BLEU or perplexity.
However, the paper does not deeply explore potential limitations or caveats of the SIB task. For example, the reliance on human evaluators introduces subjectivity that could vary across individuals or contexts. It's also unclear how well the betting game incentives actually align with true semantic importance judgments.
Additionally, the paper could have provided more analysis and discussion around the specific insights gleaned from the SIB experiments. While the results suggest the approach can uncover meaningful differences between models, the implications for model development and deployment are not fully fleshed out.
Overall, this is an interesting and novel contribution to language model evaluation. But further research is needed to understand the strengths, weaknesses, and optimal application of the semantic importance betting framework.
Conclusion
This paper introduces a new approach called "Semantic Importance Betting" (SIB) for evaluating the semantic significance of text generated by language models. The SIB task asks human evaluators to bet on how important they consider the meaning and content of a given model output.
The betting game framework provides a richer signal about semantic value compared to standard evaluation metrics. Through experiments, the authors demonstrate how SIB can uncover cases where language models produce fluent but semantically unimportant text, which other methods may miss.
While the SIB approach shows promise, the paper also highlights the need for further research to fully understand its strengths, limitations, and implications for improving language model development and deployment. Nonetheless, this work represents an innovative step towards more nuanced evaluation of AI language systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
I Bet You Did Not Mean That: Testing Semantic Importance via Betting
Jacopo Teneggi, Jeremias Sulam
Recent works have extended notions of feature importance to semantic concepts that are inherently interpretable to the users interacting with a black-box predictive model. Yet, precise statistical guarantees, such as false positive rate and false discovery rate control, are needed to communicate findings transparently and to avoid unintended consequences in real-world scenarios. In this paper, we formalize the global (i.e., over a population) and local (i.e., for a sample) statistical importance of semantic concepts for the predictions of opaque models by means of conditional independence, which allows for rigorous testing. We use recent ideas of sequential kernelized independence testing (SKIT) to induce a rank of importance across concepts, and showcase the effectiveness and flexibility of our framework on synthetic datasets as well as on image classification tasks using several and diverse vision-language models.
Read more10/8/2024
✨
0
Confident Feature Ranking
Bitya Neuhof, Yuval Benjamini
Machine learning models are widely applied in various fields. Stakeholders often use post-hoc feature importance methods to better understand the input features' contribution to the models' predictions. The interpretation of the importance values provided by these methods is frequently based on the relative order of the features (their ranking) rather than the importance values themselves. Since the order may be unstable, we present a framework for quantifying the uncertainty in global importance values. We propose a novel method for the post-hoc interpretation of feature importance values that is based on the framework and pairwise comparisons of the feature importance values. This method produces simultaneous confidence intervals for the features' ranks, which include the ``true'' (infinite sample) ranks with high probability, and enables the selection of the set of the top-k important features.
Read more4/19/2024

0
Towards White Box Deep Learning
Maciej Satkiewicz
This paper introduces semantic features as a candidate conceptual framework for white-box neural networks. The proof of concept model is well-motivated, inherently interpretable, has low parameter-count and achieves almost human-level adversarial test metrics - with no adversarial training! These results and the general nature of the approach warrant further research on semantic features. The code is available at https://github.com/314-Foundation/white-box-nn
Read more4/16/2024
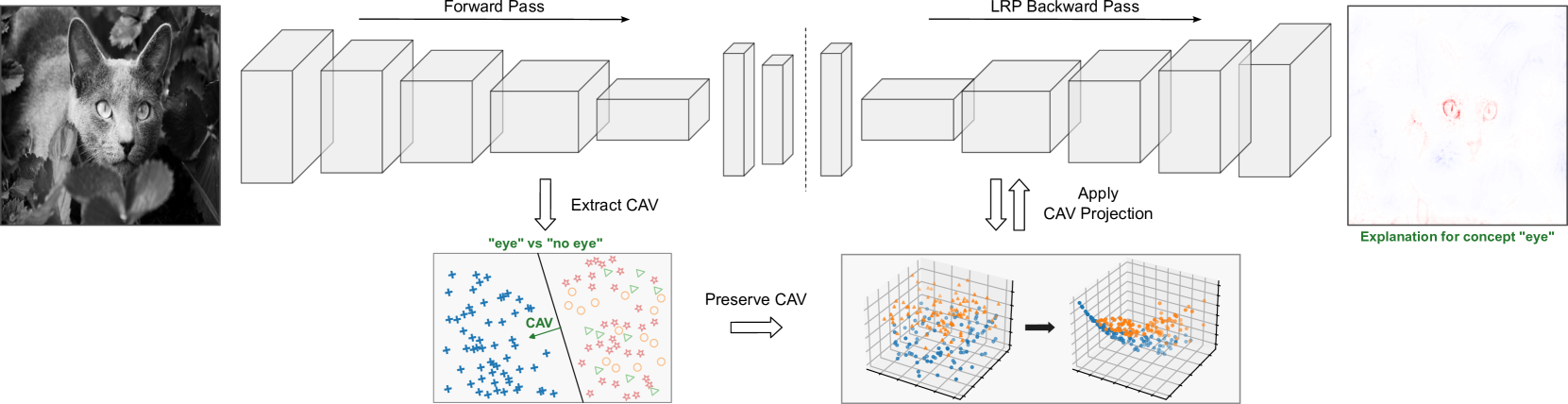
0
Locally Testing Model Detections for Semantic Global Concepts
Franz Motzkus, Georgii Mikriukov, Christian Hellert, Ute Schmid
Ensuring the quality of black-box Deep Neural Networks (DNNs) has become ever more significant, especially in safety-critical domains such as automated driving. While global concept encodings generally enable a user to test a model for a specific concept, linking global concept encodings to the local processing of single network inputs reveals their strengths and limitations. Our proposed framework global-to-local Concept Attribution (glCA) uses approaches from local (why a specific prediction originates) and global (how a model works generally) eXplainable Artificial Intelligence (xAI) to test DNNs for a predefined semantical concept locally. The approach allows for conditioning local, post-hoc explanations on predefined semantic concepts encoded as linear directions in the model's latent space. Pixel-exact scoring concerning the global concept usage assists the tester in further understanding the model processing of single data points for the selected concept. Our approach has the advantage of fully covering the model-internal encoding of the semantic concept and allowing the localization of relevant concept-related information. The results show major differences in the local perception and usage of individual global concept encodings and demand for further investigations regarding obtaining thorough semantic concept encodings.
Read more5/30/2024