Identifying Crucial Objects in Blind and Low-Vision Individuals' Navigation

0

Sign in to get full access
Overview
- This research paper examines methods to identify crucial objects in the navigation of blind and low-vision individuals.
- The goal is to develop AI-powered assistive technologies that can better support these individuals in their everyday movements and activities.
- The research explores computer vision techniques to detect and recognize important environmental cues that are vital for safe and effective navigation.
Plain English Explanation
The paper focuses on a crucial challenge faced by people who are blind or have low vision: navigating the physical world. For those with visual impairments, simple tasks like walking down a street or finding one's way in a building can be extremely difficult and dangerous without proper assistance.
To address this, the researchers investigate ways for AI systems to automatically identify crucial objects in the environment that are essential for safe navigation. This could include things like curbs, stairs, doors, and other landmarks that sighted people rely on subconsciously. By detecting and recognizing these key elements, the AI can then provide tailored guidance and instructions to the user, helping them move through their surroundings more safely and confidently.
The work builds on prior research into generating contextually relevant navigation instructions for blind and low-vision individuals. The goal is to develop multi-modal foundation models that can leverage computer vision, audio, and other sensory inputs to understand a user's environment and offer reliable, real-time assistance.
Technical Explanation
The paper presents a novel approach for identifying crucial objects in images that are particularly important for the navigation of blind and low-vision individuals. The researchers propose a deep learning-based model that can accurately detect and classify a variety of environmental features, from curbs and stairs to doors and other landmarks.
The model is trained on a custom dataset of annotated images, with each object of interest labeled according to its level of importance for navigation. This allows the AI to learn the distinctive visual characteristics of these crucial elements and prioritize them during inference.
The researchers also explore techniques for leveraging street cameras to gather contextual information about a user's surroundings, which can further enhance the system's ability to provide relevant and timely guidance. This multi-modal approach combines computer vision with other sensory inputs to build a more comprehensive understanding of the user's environment.
Critical Analysis
The research presented in this paper represents an important step forward in the development of assistive technologies for blind and low-vision individuals. By focusing on the identification of crucial environmental objects, the proposed model has the potential to significantly improve the safety and independence of those with visual impairments during navigation.
However, the paper also acknowledges several limitations and areas for further research. For example, the dataset used for training the model may not capture the full diversity of real-world environments and object configurations. There are also potential privacy concerns around the use of street cameras and other sensors to gather user data.
Additionally, the researchers note that the current model is primarily focused on object detection and classification, and that future work should explore more advanced techniques for interpreting the overall spatial layout and contextual relationships between navigational elements. Integrating this higher-level understanding into the assistive system could further enhance its effectiveness and usability.
Conclusion
This research paper presents a promising approach for identifying crucial objects in the navigation of blind and low-vision individuals. By developing AI-powered computer vision models that can accurately detect and recognize key environmental features, the researchers aim to create more effective and reliable assistive technologies to support those with visual impairments.
While the work has some limitations and areas for further development, the overall approach represents an important step forward in enhancing the independence and safety of blind and low-vision individuals as they navigate the physical world. As the technology continues to evolve, it has the potential to significantly improve the quality of life for those with visual disabilities.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Identifying Crucial Objects in Blind and Low-Vision Individuals' Navigation
Md Touhidul Islam, Imran Kabir, Elena Ariel Pearce, Md Alimoor Reza, Syed Masum Billah
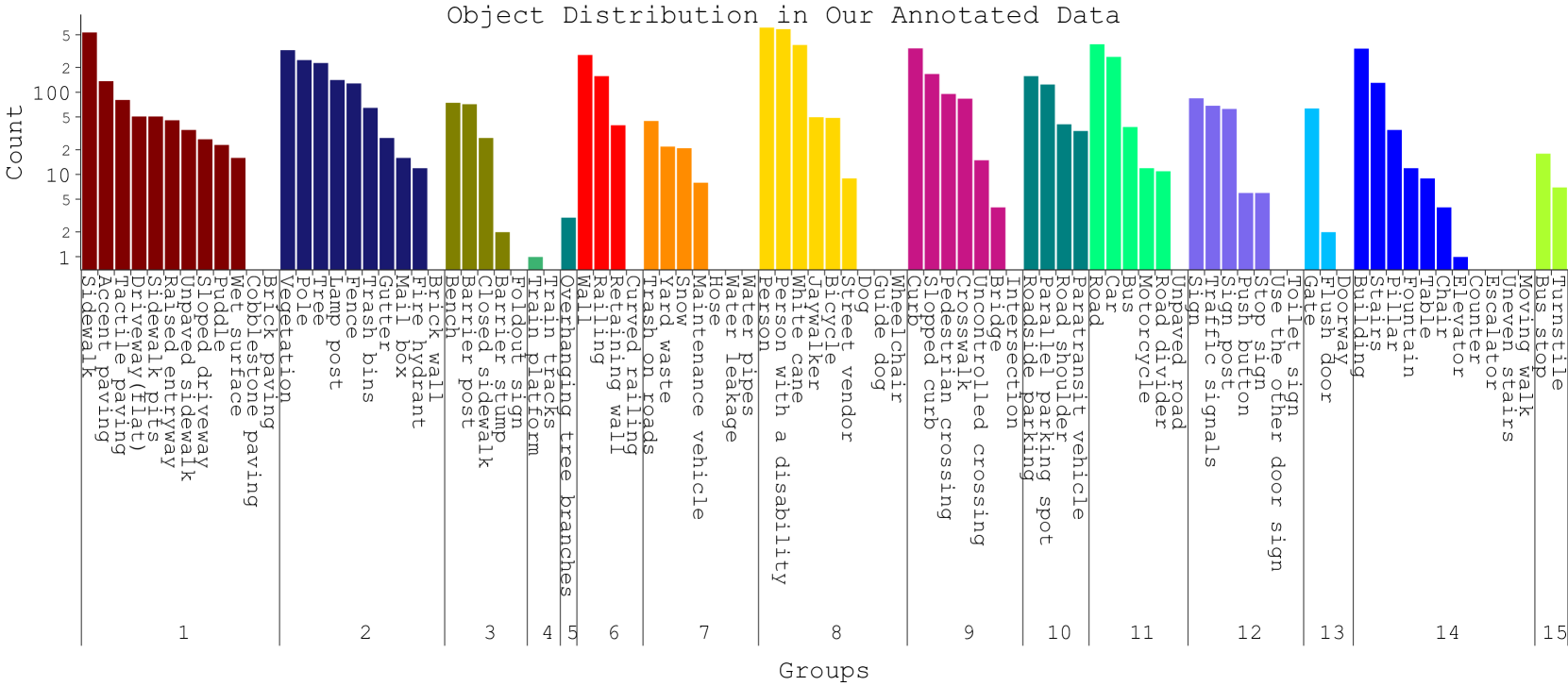
This paper presents a curated list of 90 objects essential for the navigation of blind and low-vision (BLV) individuals, encompassing road, sidewalk, and indoor environments. We develop the initial list by analyzing 21 publicly available videos featuring BLV individuals navigating various settings. Then, we refine the list through feedback from a focus group study involving blind, low-vision, and sighted companions of BLV individuals. A subsequent analysis reveals that most contemporary datasets used to train recent computer vision models contain only a small subset of the objects in our proposed list. Furthermore, we provide detailed object labeling for these 90 objects across 31 video segments derived from the original 21 videos. Finally, we make the object list, the 21 videos, and object labeling in the 31 video segments publicly available. This paper aims to fill the existing gap and foster the development of more inclusive and effective navigation aids for the BLV community.
Read more8/26/2024
0
A Dataset for Crucial Object Recognition in Blind and Low-Vision Individuals' Navigation
Md Touhidul Islam, Imran Kabir, Elena Ariel Pearce, Md Alimoor Reza, Syed Masum Billah
This paper introduces a dataset for improving real-time object recognition systems to aid blind and low-vision (BLV) individuals in navigation tasks. The dataset comprises 21 videos of BLV individuals navigating outdoor spaces, and a taxonomy of 90 objects crucial for BLV navigation, refined through a focus group study. We also provide object labeling for the 90 objects across 31 video segments created from the 21 videos. A deeper analysis reveals that most contemporary datasets used in training computer vision models contain only a small subset of the taxonomy in our dataset. Preliminary evaluation of state-of-the-art computer vision models on our dataset highlights shortcomings in accurately detecting key objects relevant to BLV navigation, emphasizing the need for specialized datasets. We make our dataset publicly available, offering valuable resources for developing more inclusive navigation systems for BLV individuals.
Read more7/25/2024

0
Generating Contextually-Relevant Navigation Instructions for Blind and Low Vision People
Zain Merchant, Abrar Anwar, Emily Wang, Souti Chattopadhyay, Jesse Thomason
Navigating unfamiliar environments presents significant challenges for blind and low-vision (BLV) individuals. In this work, we construct a dataset of images and goals across different scenarios such as searching through kitchens or navigating outdoors. We then investigate how grounded instruction generation methods can provide contextually-relevant navigational guidance to users in these instances. Through a sighted user study, we demonstrate that large pretrained language models can produce correct and useful instructions perceived as beneficial for BLV users. We also conduct a survey and interview with 4 BLV users and observe useful insights on preferences for different instructions based on the scenario.
Read more7/12/2024
📈
0
A Multi-Modal Foundation Model to Assist People with Blindness and Low Vision in Environmental Interaction
Yu Hao, Fan Yang, Hao Huang, Shuaihang Yuan, Sundeep Rangan, John-Ross Rizzo, Yao Wang, Yi Fang
People with blindness and low vision (pBLV) encounter substantial challenges when it comes to comprehensive scene recognition and precise object identification in unfamiliar environments. Additionally, due to the vision loss, pBLV have difficulty in accessing and identifying potential tripping hazards on their own. In this paper, we present a pioneering approach that leverages a large vision-language model to enhance visual perception for pBLV, offering detailed and comprehensive descriptions of the surrounding environments and providing warnings about the potential risks. Our method begins by leveraging a large image tagging model (i.e., Recognize Anything (RAM)) to identify all common objects present in the captured images. The recognition results and user query are then integrated into a prompt, tailored specifically for pBLV using prompt engineering. By combining the prompt and input image, a large vision-language model (i.e., InstructBLIP) generates detailed and comprehensive descriptions of the environment and identifies potential risks in the environment by analyzing the environmental objects and scenes, relevant to the prompt. We evaluate our approach through experiments conducted on both indoor and outdoor datasets. Our results demonstrate that our method is able to recognize objects accurately and provide insightful descriptions and analysis of the environment for pBLV.
Read more4/30/2024