Identifying the Risks of LM Agents with an LM-Emulated Sandbox

0
🔍
Sign in to get full access
Overview
- Recent advances in Language Model (LM) agents and tool use, such as ChatGPT Plugins, offer a wide range of capabilities but also introduce potential risks like leaking private data or causing financial losses.
- Identifying these risks is labor-intensive, requiring manual setup and testing for each scenario.
- As tools and agents become more complex, the high cost of testing will make it increasingly difficult to find high-stakes, long-tailed risks.
Plain English Explanation
Powerful language models like ChatGPT Plugins can now be used to control various tools and applications, opening up a wealth of possibilities. However, these capabilities also come with risks, such as accidentally sharing private information or causing financial harm.
Identifying all the potential risks with these language model agents is a time-consuming process. It involves manually setting up and testing each tool or scenario to see how the agent might behave. As these language models and their associated tools become more complex, it will become increasingly challenging to find all the important, less common risks.
To address these challenges, the researchers introduce a new framework called ToolEmu, which uses a language model to simulate the execution of tools, without the need to manually set up each test scenario. This allows for more extensive testing and risk analysis. The researchers also develop an automatic safety evaluator that can assess the severity of any issues found with the language model agents.
Technical Explanation
The researchers present ToolEmu, a framework that uses a language model to emulate the execution of various tools and enables the testing of language model agents against a diverse range of scenarios, without the need for manual setup.
Alongside the emulator, the researchers develop an LM-based automatic safety evaluator that examines agent failures and quantifies the associated risks. They test both the tool emulator and evaluator through human evaluation, finding that 68.8% of the failures identified by ToolEmu would be valid in real-world settings.
Using an initial benchmark of 36 high-stakes tools and 144 test cases, the researchers provide a quantitative risk analysis of current language model agents. They find that even the safest agent exhibits failures with potentially severe outcomes 23.9% of the time, according to their evaluator. This underscores the need to develop safer language model agents for real-world deployment.
Critical Analysis
The researchers acknowledge that their initial benchmark, while comprehensive, may not cover all possible tools and scenarios. As language models and their capabilities continue to evolve, the set of tools and test cases will need to be regularly updated and expanded.
While the ToolEmu framework and safety evaluator show promise, it's important to note that they rely on the language model's ability to accurately emulate tool behavior and assess potential risks. The accuracy of these components may be influenced by the model's training data and capabilities, which could introduce biases or blind spots.
Additionally, the researchers' evaluation focuses on individual agent failures, but the real-world impact of these failures may depend on the specific context and application. Further research is needed to understand how these risks manifest in practical, end-to-end deployments of language model agents.
Conclusion
The paper introduces a novel approach to testing and evaluating the safety of language model agents, which is crucial as these powerful tools become more widespread. The ToolEmu framework and safety evaluator provide a promising way to systematically identify and quantify potential risks, even for complex and evolving language model capabilities.
However, the research also highlights the ongoing challenges in ensuring the safe and responsible deployment of these technologies. Continued efforts to improve the accuracy and robustness of safety evaluation methods, as well as a deeper understanding of the real-world implications of language model agent failures, will be crucial as these technologies become more integrated into our daily lives.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🔍
0
Identifying the Risks of LM Agents with an LM-Emulated Sandbox
Yangjun Ruan, Honghua Dong, Andrew Wang, Silviu Pitis, Yongchao Zhou, Jimmy Ba, Yann Dubois, Chris J. Maddison, Tatsunori Hashimoto
Recent advances in Language Model (LM) agents and tool use, exemplified by applications like ChatGPT Plugins, enable a rich set of capabilities but also amplify potential risks - such as leaking private data or causing financial losses. Identifying these risks is labor-intensive, necessitating implementing the tools, setting up the environment for each test scenario manually, and finding risky cases. As tools and agents become more complex, the high cost of testing these agents will make it increasingly difficult to find high-stakes, long-tailed risks. To address these challenges, we introduce ToolEmu: a framework that uses an LM to emulate tool execution and enables the testing of LM agents against a diverse range of tools and scenarios, without manual instantiation. Alongside the emulator, we develop an LM-based automatic safety evaluator that examines agent failures and quantifies associated risks. We test both the tool emulator and evaluator through human evaluation and find that 68.8% of failures identified with ToolEmu would be valid real-world agent failures. Using our curated initial benchmark consisting of 36 high-stakes tools and 144 test cases, we provide a quantitative risk analysis of current LM agents and identify numerous failures with potentially severe outcomes. Notably, even the safest LM agent exhibits such failures 23.9% of the time according to our evaluator, underscoring the need to develop safer LM agents for real-world deployment.
Read more5/20/2024
🤷
0
Prioritizing Safeguarding Over Autonomy: Risks of LLM Agents for Science
Xiangru Tang, Qiao Jin, Kunlun Zhu, Tongxin Yuan, Yichi Zhang, Wangchunshu Zhou, Meng Qu, Yilun Zhao, Jian Tang, Zhuosheng Zhang, Arman Cohan, Zhiyong Lu, Mark Gerstein
Intelligent agents powered by large language models (LLMs) have demonstrated substantial promise in autonomously conducting experiments and facilitating scientific discoveries across various disciplines. While their capabilities are promising, these agents, called scientific LLM agents, also introduce novel vulnerabilities that demand careful consideration for safety. However, there exists a notable gap in the literature, as there has been no comprehensive exploration of these vulnerabilities. This perspective paper fills this gap by conducting a thorough examination of vulnerabilities in LLM-based agents within scientific domains, shedding light on potential risks associated with their misuse and emphasizing the need for safety measures. We begin by providing a comprehensive overview of the potential risks inherent to scientific LLM agents, taking into account user intent, the specific scientific domain, and their potential impact on the external environment. Then, we delve into the origins of these vulnerabilities and provide a scoping review of the limited existing works. Based on our analysis, we propose a triadic framework involving human regulation, agent alignment, and an understanding of environmental feedback (agent regulation) to mitigate these identified risks. Furthermore, we highlight the limitations and challenges associated with safeguarding scientific agents and advocate for the development of improved models, robust benchmarks, and comprehensive regulations to address these issues effectively.
Read more6/6/2024
🤖
0
Current state of LLM Risks and AI Guardrails
Suriya Ganesh Ayyamperumal, Limin Ge
Large language models (LLMs) have become increasingly sophisticated, leading to widespread deployment in sensitive applications where safety and reliability are paramount. However, LLMs have inherent risks accompanying them, including bias, potential for unsafe actions, dataset poisoning, lack of explainability, hallucinations, and non-reproducibility. These risks necessitate the development of guardrails to align LLMs with desired behaviors and mitigate potential harm. This work explores the risks associated with deploying LLMs and evaluates current approaches to implementing guardrails and model alignment techniques. We examine intrinsic and extrinsic bias evaluation methods and discuss the importance of fairness metrics for responsible AI development. The safety and reliability of agentic LLMs (those capable of real-world actions) are explored, emphasizing the need for testability, fail-safes, and situational awareness. Technical strategies for securing LLMs are presented, including a layered protection model operating at external, secondary, and internal levels. System prompts, Retrieval-Augmented Generation (RAG) architectures, and techniques to minimize bias and protect privacy are highlighted. Effective guardrail design requires a deep understanding of the LLM's intended use case, relevant regulations, and ethical considerations. Striking a balance between competing requirements, such as accuracy and privacy, remains an ongoing challenge. This work underscores the importance of continuous research and development to ensure the safe and responsible use of LLMs in real-world applications.
Read more6/21/2024
305
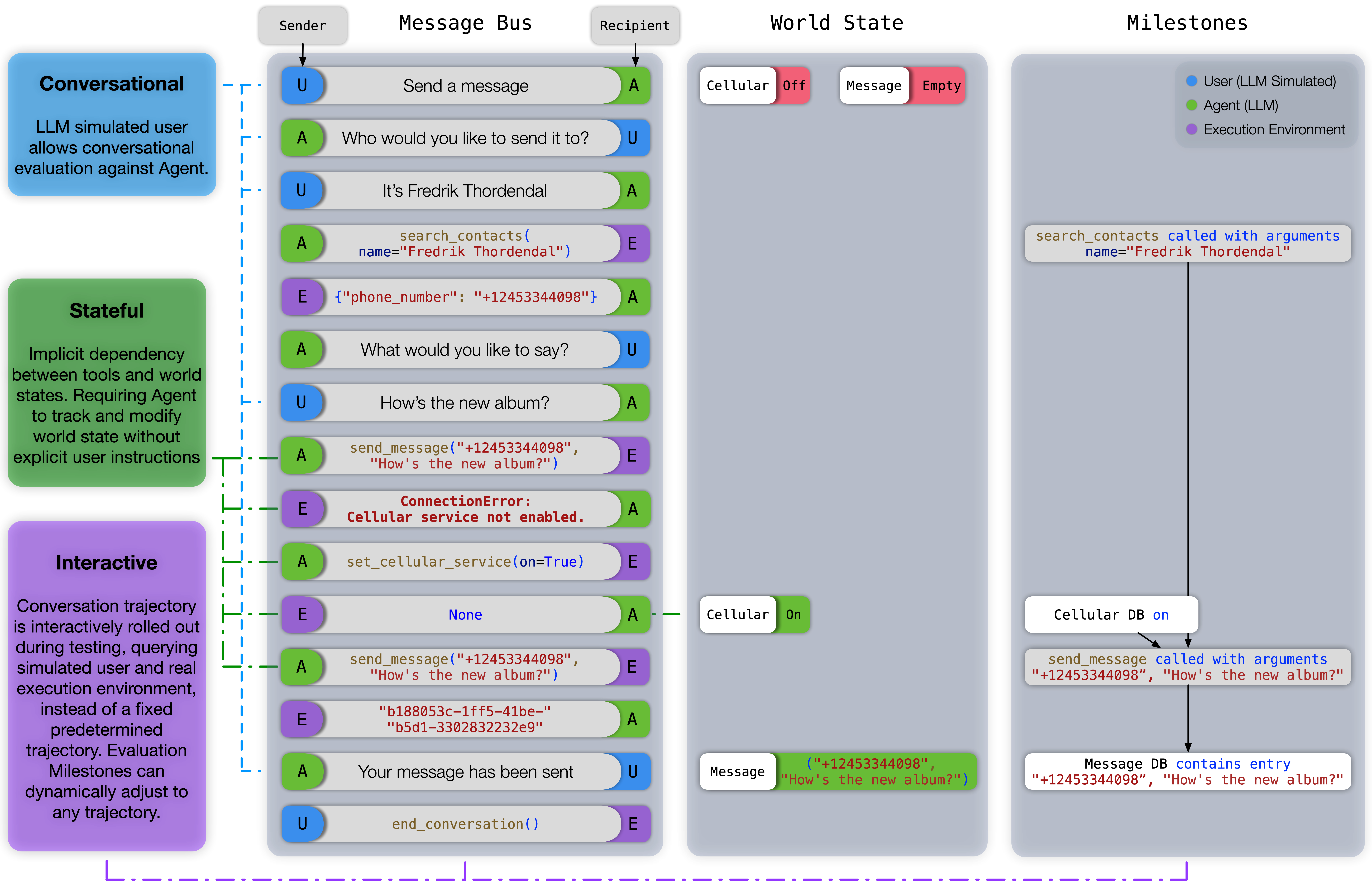
ToolSandbox: A Stateful, Conversational, Interactive Evaluation Benchmark for LLM Tool Use Capabilities
Jiarui Lu, Thomas Holleis, Yizhe Zhang, Bernhard Aumayer, Feng Nan, Felix Bai, Shuang Ma, Shen Ma, Mengyu Li, Guoli Yin, Zirui Wang, Ruoming Pang
Recent large language models (LLMs) advancements sparked a growing research interest in tool assisted LLMs solving real-world challenges, which calls for comprehensive evaluation of tool-use capabilities. While previous works focused on either evaluating over stateless web services (RESTful API), based on a single turn user prompt, or an off-policy dialog trajectory, ToolSandbox includes stateful tool execution, implicit state dependencies between tools, a built-in user simulator supporting on-policy conversational evaluation and a dynamic evaluation strategy for intermediate and final milestones over an arbitrary trajectory. We show that open source and proprietary models have a significant performance gap, and complex tasks like State Dependency, Canonicalization and Insufficient Information defined in ToolSandbox are challenging even the most capable SOTA LLMs, providing brand-new insights into tool-use LLM capabilities. ToolSandbox evaluation framework is released at https://github.com/apple/ToolSandbox
Read more8/12/2024