ToolSandbox: A Stateful, Conversational, Interactive Evaluation Benchmark for LLM Tool Use Capabilities

305
Sign in to get full access
Overview
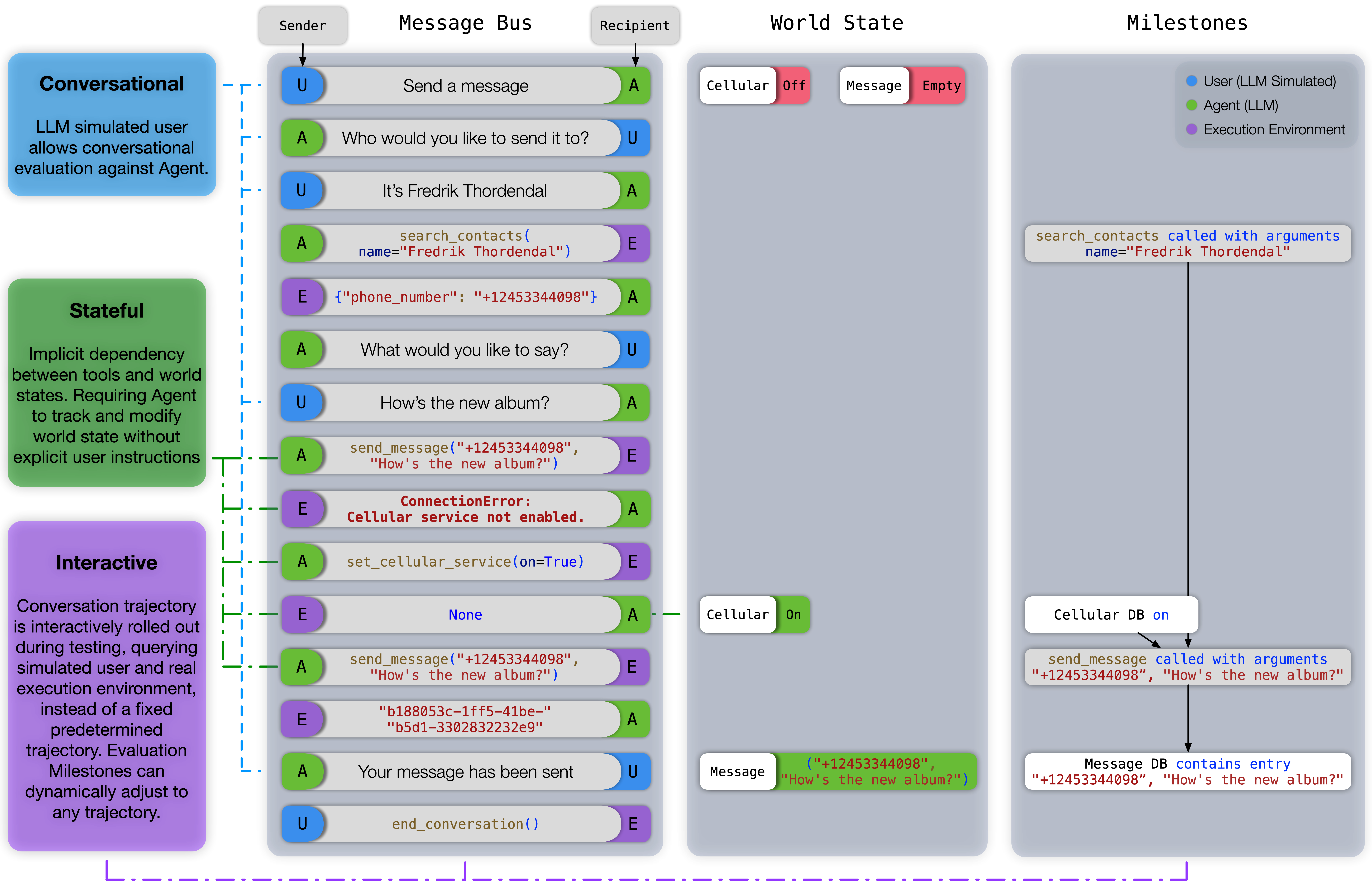
- ToolSandbox is an evaluation benchmark for assessing the tool use capabilities of large language models (LLMs).
- It is designed to be stateful, conversational, and interactive, allowing for more comprehensive and realistic evaluation.
- The benchmark covers a diverse range of tasks, from simple tool usage to more complex problem-solving and decision-making scenarios.
Plain English Explanation
ToolSandbox is a new way to test how well large language models can use various tools and applications to solve problems. Unlike previous benchmarks that only looked at single, isolated tasks, ToolSandbox is designed to be more realistic and comprehensive.
The key features of ToolSandbox include:
- Stateful: The benchmark keeps track of the model's "memory" and previous actions, allowing for more complex, multi-step scenarios.
- Conversational: The interaction between the model and the benchmark is designed to feel like a natural conversation, rather than a series of disconnected prompts.
- Interactive: The model can actively engage with the benchmark, requesting information, making decisions, and taking actions, rather than just passively responding to questions.
By incorporating these features, ToolSandbox aims to provide a more accurate assessment of a model's real-world tool use capabilities, beyond just its ability to perform isolated tasks.
Technical Explanation
The ToolSandbox benchmark is designed to evaluate the tool use capabilities of large language models (LLMs). Unlike previous benchmarks that focused on single, isolated tasks, ToolSandbox takes a more holistic and realistic approach, incorporating stateful, conversational, and interactive elements.
The stateful nature of ToolSandbox allows the benchmark to keep track of the model's previous actions and "memory," enabling more complex, multi-step scenarios. This, in turn, requires the model to maintain context and make coherent decisions based on its past interactions.
The conversational aspect of the benchmark aims to create a more natural interaction between the model and the evaluation environment, rather than a series of disconnected prompts. This encourages the model to engage in contextual reasoning and natural language understanding.
Finally, the interactive nature of ToolSandbox allows the model to actively request information, make decisions, and take actions, rather than just passively responding to questions. This tests the model's ability to problem-solve and utilize tools in a more dynamic and realistic way.
By incorporating these features, ToolSandbox seeks to provide a more comprehensive and accurate assessment of a model's tool use capabilities, going beyond its performance on isolated tasks.
Critical Analysis
The ToolSandbox benchmark presents a promising approach to evaluating the tool use capabilities of large language models. Its stateful, conversational, and interactive design is a significant step forward compared to traditional benchmarks that focus on single, disconnected tasks.
However, one potential limitation of the benchmark is the complexity of the scenarios it presents. Designing and curating a diverse set of realistic, multi-step problem-solving tasks may be a significant challenge. The authors acknowledge this and suggest that the benchmark may need to be expanded and refined over time to maintain its relevance and usefulness.
Additionally, there are potential biases and limitations in the way the benchmark is constructed and evaluated. For example, the selection of tasks and the way they are framed may favor certain types of models or capabilities. The authors recognize this and encourage further research to identify and mitigate such biases.
Overall, the ToolSandbox benchmark represents an important step towards more comprehensive and realistic evaluation of large language models' tool use capabilities. However, as with any new evaluation framework, it will require ongoing refinement and critical analysis to ensure its validity and usefulness in the rapidly evolving field of AI.
Conclusion
The ToolSandbox benchmark proposed in this paper represents a significant advancement in the evaluation of large language models' tool use capabilities. By incorporating stateful, conversational, and interactive elements, the benchmark aims to provide a more realistic and comprehensive assessment of these models' abilities to engage with and utilize various tools and applications.
The potential impact of this research is twofold. First, it could lead to the development of more capable and versatile language models that can effectively leverage tools and applications to solve complex, real-world problems. Second, it could inform the design of future benchmarks and evaluation frameworks, as the field of AI continues to evolve and demand more sophisticated and realistic assessment methods.
As with any new research, the ToolSandbox benchmark will require ongoing refinement and critical analysis to address potential limitations and biases. However, the authors' approach represents an important step forward in the pursuit of robust and meaningful evaluation of large language models' capabilities.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
305
ToolSandbox: A Stateful, Conversational, Interactive Evaluation Benchmark for LLM Tool Use Capabilities
Jiarui Lu, Thomas Holleis, Yizhe Zhang, Bernhard Aumayer, Feng Nan, Felix Bai, Shuang Ma, Shen Ma, Mengyu Li, Guoli Yin, Zirui Wang, Ruoming Pang
Recent large language models (LLMs) advancements sparked a growing research interest in tool assisted LLMs solving real-world challenges, which calls for comprehensive evaluation of tool-use capabilities. While previous works focused on either evaluating over stateless web services (RESTful API), based on a single turn user prompt, or an off-policy dialog trajectory, ToolSandbox includes stateful tool execution, implicit state dependencies between tools, a built-in user simulator supporting on-policy conversational evaluation and a dynamic evaluation strategy for intermediate and final milestones over an arbitrary trajectory. We show that open source and proprietary models have a significant performance gap, and complex tasks like State Dependency, Canonicalization and Insufficient Information defined in ToolSandbox are challenging even the most capable SOTA LLMs, providing brand-new insights into tool-use LLM capabilities. ToolSandbox evaluation framework is released at https://github.com/apple/ToolSandbox
Read more8/12/2024
0
StableToolBench: Towards Stable Large-Scale Benchmarking on Tool Learning of Large Language Models
Zhicheng Guo, Sijie Cheng, Hao Wang, Shihao Liang, Yujia Qin, Peng Li, Zhiyuan Liu, Maosong Sun, Yang Liu
Large Language Models (LLMs) have witnessed remarkable advancements in recent years, prompting the exploration of tool learning, which integrates LLMs with external tools to address diverse real-world challenges. Assessing the capability of LLMs to utilise tools necessitates large-scale and stable benchmarks. However, previous works relied on either hand-crafted online tools with limited scale, or large-scale real online APIs suffering from instability of API status. To address this problem, we introduce StableToolBench, a benchmark evolving from ToolBench, proposing a virtual API server and stable evaluation system. The virtual API server contains a caching system and API simulators which are complementary to alleviate the change in API status. Meanwhile, the stable evaluation system designs solvable pass and win rates using GPT-4 as the automatic evaluator to eliminate the randomness during evaluation. Experimental results demonstrate the stability of StableToolBench, and further discuss the effectiveness of API simulators, the caching system, and the evaluator system.
Read more6/21/2024
🔍
0
Identifying the Risks of LM Agents with an LM-Emulated Sandbox
Yangjun Ruan, Honghua Dong, Andrew Wang, Silviu Pitis, Yongchao Zhou, Jimmy Ba, Yann Dubois, Chris J. Maddison, Tatsunori Hashimoto
Recent advances in Language Model (LM) agents and tool use, exemplified by applications like ChatGPT Plugins, enable a rich set of capabilities but also amplify potential risks - such as leaking private data or causing financial losses. Identifying these risks is labor-intensive, necessitating implementing the tools, setting up the environment for each test scenario manually, and finding risky cases. As tools and agents become more complex, the high cost of testing these agents will make it increasingly difficult to find high-stakes, long-tailed risks. To address these challenges, we introduce ToolEmu: a framework that uses an LM to emulate tool execution and enables the testing of LM agents against a diverse range of tools and scenarios, without manual instantiation. Alongside the emulator, we develop an LM-based automatic safety evaluator that examines agent failures and quantifies associated risks. We test both the tool emulator and evaluator through human evaluation and find that 68.8% of failures identified with ToolEmu would be valid real-world agent failures. Using our curated initial benchmark consisting of 36 high-stakes tools and 144 test cases, we provide a quantitative risk analysis of current LM agents and identify numerous failures with potentially severe outcomes. Notably, even the safest LM agent exhibits such failures 23.9% of the time according to our evaluator, underscoring the need to develop safer LM agents for real-world deployment.
Read more5/20/2024
👁️
0
Planning, Creation, Usage: Benchmarking LLMs for Comprehensive Tool Utilization in Real-World Complex Scenarios
Shijue Huang, Wanjun Zhong, Jianqiao Lu, Qi Zhu, Jiahui Gao, Weiwen Liu, Yutai Hou, Xingshan Zeng, Yasheng Wang, Lifeng Shang, Xin Jiang, Ruifeng Xu, Qun Liu
The recent trend of using Large Language Models (LLMs) as tool agents in real-world applications underscores the necessity for comprehensive evaluations of their capabilities, particularly in complex scenarios involving planning, creating, and using tools. However, existing benchmarks typically focus on simple synthesized queries that do not reflect real-world complexity, thereby offering limited perspectives in evaluating tool utilization. To address this issue, we present UltraTool, a novel benchmark designed to improve and evaluate LLMs' ability in tool utilization within real-world scenarios. UltraTool focuses on the entire process of using tools - from planning and creating to applying them in complex tasks. It emphasizes real-world complexities, demanding accurate, multi-step planning for effective problem-solving. A key feature of UltraTool is its independent evaluation of planning with natural language, which happens before tool usage and simplifies the task solving by mapping out the intermediate steps. Thus, unlike previous work, it eliminates the restriction of pre-defined toolset. Through extensive experiments on various LLMs, we offer novel insights into the evaluation of capabilities of LLMs in tool utilization, thereby contributing a fresh perspective to this rapidly evolving field. The benchmark is publicly available at https://github.com/JoeYing1019/UltraTool.
Read more6/4/2024