IFViT: Interpretable Fixed-Length Representation for Fingerprint Matching via Vision Transformer

0

Sign in to get full access
Overview
- Presents a new approach called IFViT (Interpretable Fixed-Length Representation for Fingerprint Matching via Vision Transformer) for fingerprint recognition
- Proposes using a Vision Transformer (ViT) to extract a fixed-length representation from fingerprint images, enabling efficient matching
- Aims to achieve interpretable and accurate fingerprint recognition without the need for complex preprocessing or feature engineering
Plain English Explanation
The paper introduces a new method called IFViT for fingerprint recognition. Fingerprint recognition is an important biometric identification technique, but traditional methods can be complex and require a lot of manual feature engineering.
The researchers propose using a Vision Transformer (ViT) to extract a fixed-length representation directly from the fingerprint image. This fixed-length representation can then be used for efficient matching and comparison of fingerprints.
The key advantage of this approach is that it is interpretable - the ViT model can provide insights into which parts of the fingerprint image are most important for recognition. This is in contrast to more complex "black box" models that can be difficult to understand.
The researchers demonstrate that IFViT achieves high accuracy on standard fingerprint recognition benchmarks, while also being efficient and easy to understand. This could make it a valuable tool for real-world fingerprint-based identification systems.
Technical Explanation
The paper proposes the IFViT architecture, which uses a Vision Transformer (ViT) to extract a fixed-length representation from fingerprint images.
The ViT model divides the input fingerprint image into patches, which are then processed through a series of transformer layers to produce a fixed-length feature vector. This fixed-length representation can then be used for efficient fingerprint matching and comparison.
The researchers experiment with different ViT configurations, including variations in patch size and the number of transformer layers. They also explore incorporating some domain-specific fingerprint features, such as orientation and frequency information, into the ViT model.
Through extensive experiments on several public fingerprint recognition datasets, the authors demonstrate that IFViT achieves state-of-the-art performance, outperforming traditional fingerprint recognition methods as well as other deep learning approaches. Importantly, the interpretable nature of the ViT model allows for better understanding of the most important fingerprint features for recognition.
Critical Analysis
The paper presents a promising approach to fingerprint recognition that combines the power of Vision Transformers with the benefits of interpretability. The authors demonstrate strong empirical results and provide insights into the key fingerprint features learned by the IFViT model.
However, the paper does not fully address the potential limitations of this approach. For example, the authors do not discuss how the IFViT model might perform on more challenging or diverse fingerprint datasets, such as those with higher variability in image quality or noise levels. Additionally, the paper does not explore the computational efficiency of the IFViT model in real-world deployment scenarios.
Furthermore, the authors could have delved deeper into the interpretability aspects of the IFViT model, providing more detailed analysis of the learned attention maps and their correspondence to known fingerprint features. This could have strengthened the claims about the model's interpretability and its potential benefits for understanding the fingerprint recognition process.
Overall, the IFViT approach is a promising contribution to the field of fingerprint recognition, leveraging the strengths of Vision Transformers to achieve interpretable and accurate results. However, further research is needed to fully assess the practical implications and limitations of this method.
Conclusion
The IFViT paper presents a novel approach to fingerprint recognition that utilizes a Vision Transformer to extract a fixed-length representation from fingerprint images. This approach aims to achieve both high accuracy and interpretability, addressing some of the limitations of traditional fingerprint recognition methods.
The key innovation of IFViT is the use of a ViT model to directly process fingerprint images, without the need for complex preprocessing or feature engineering. The authors demonstrate that this approach outperforms state-of-the-art fingerprint recognition techniques on several benchmark datasets.
Moreover, the interpretability of the ViT model allows for a better understanding of the fingerprint features that are most important for recognition. This could lead to improved system design and potentially facilitate the adoption of fingerprint recognition in a wider range of applications.
Overall, the IFViT paper presents a promising direction for the field of fingerprint recognition, leveraging the strengths of Vision Transformers to achieve both high performance and interpretability. Further research and real-world deployment of this approach could yield valuable insights and advancements in the field of biometric identification.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
IFViT: Interpretable Fixed-Length Representation for Fingerprint Matching via Vision Transformer
Yuhang Qiu, Honghui Chen, Xingbo Dong, Zheng Lin, Iman Yi Liao, Massimo Tistarelli, Zhe Jin
Determining dense feature points on fingerprints used in constructing deep fixed-length representations for accurate matching, particularly at the pixel level, is of significant interest. To explore the interpretability of fingerprint matching, we propose a multi-stage interpretable fingerprint matching network, namely Interpretable Fixed-length Representation for Fingerprint Matching via Vision Transformer (IFViT), which consists of two primary modules. The first module, an interpretable dense registration module, establishes a Vision Transformer (ViT)-based Siamese Network to capture long-range dependencies and the global context in fingerprint pairs. It provides interpretable dense pixel-wise correspondences of feature points for fingerprint alignment and enhances the interpretability in the subsequent matching stage. The second module takes into account both local and global representations of the aligned fingerprint pair to achieve an interpretable fixed-length representation extraction and matching. It employs the ViTs trained in the first module with the additional fully connected layer and retrains them to simultaneously produce the discriminative fixed-length representation and interpretable dense pixel-wise correspondences of feature points. Extensive experimental results on diverse publicly available fingerprint databases demonstrate that the proposed framework not only exhibits superior performance on dense registration and matching but also significantly promotes the interpretability in deep fixed-length representations-based fingerprint matching.
Read more4/15/2024
0
Playing to Vision Foundation Model's Strengths in Stereo Matching
Chuang-Wei Liu, Qijun Chen, Rui Fan
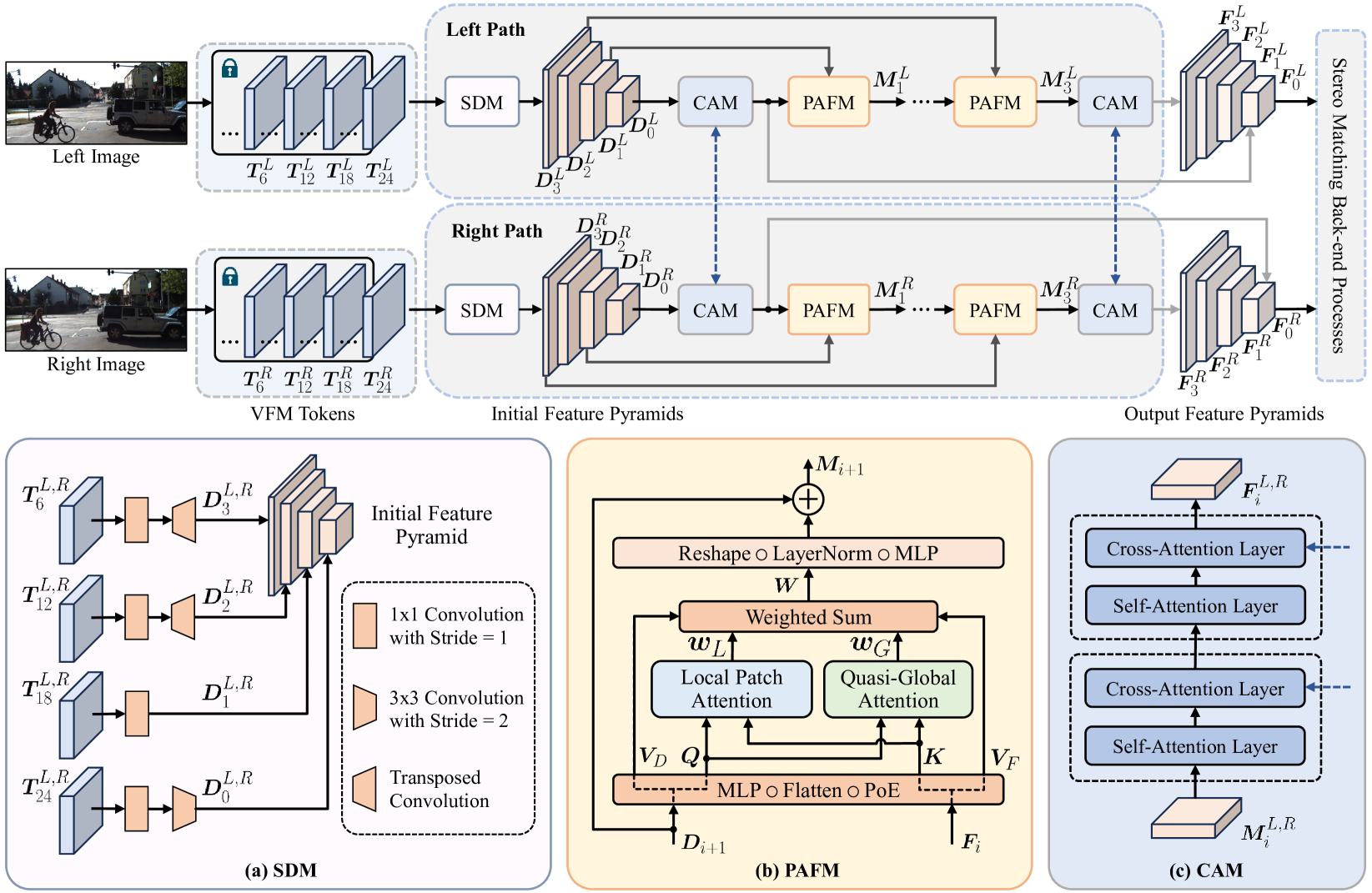
Stereo matching has become a key technique for 3D environment perception in intelligent vehicles. For a considerable time, convolutional neural networks (CNNs) have remained the mainstream choice for feature extraction in this domain. Nonetheless, there is a growing consensus that the existing paradigm should evolve towards vision foundation models (VFM), particularly those developed based on vision Transformers (ViTs) and pre-trained through self-supervision on extensive, unlabeled datasets. While VFMs are adept at extracting informative, general-purpose visual features, specifically for dense prediction tasks, their performance often lacks in geometric vision tasks. This study serves as the first exploration of a viable approach for adapting VFMs to stereo matching. Our ViT adapter, referred to as ViTAS, is constructed upon three types of modules: spatial differentiation, patch attention fusion, and cross-attention. The first module initializes feature pyramids, while the latter two aggregate stereo and multi-scale contextual information into fine-grained features, respectively. ViTAStereo, which combines ViTAS with cost volume-based stereo matching back-end processes, achieves the top rank on the KITTI Stereo 2012 dataset and outperforms the second-best network StereoBase by approximately 7.9% in terms of the percentage of error pixels, with a tolerance of 3 pixels. Additional experiments across diverse scenarios further demonstrate its superior generalizability compared to all other state-of-the-art approaches. We believe this new paradigm will pave the way for the next generation of stereo matching networks.
Read more4/10/2024
👀
0
Improving Interpretation Faithfulness for Vision Transformers
Lijie Hu, Yixin Liu, Ninghao Liu, Mengdi Huai, Lichao Sun, Di Wang
Vision Transformers (ViTs) have achieved state-of-the-art performance for various vision tasks. One reason behind the success lies in their ability to provide plausible innate explanations for the behavior of neural architectures. However, ViTs suffer from issues with explanation faithfulness, as their focal points are fragile to adversarial attacks and can be easily changed with even slight perturbations on the input image. In this paper, we propose a rigorous approach to mitigate these issues by introducing Faithful ViTs (FViTs). Briefly speaking, an FViT should have the following two properties: (1) The top-$k$ indices of its self-attention vector should remain mostly unchanged under input perturbation, indicating stable explanations; (2) The prediction distribution should be robust to perturbations. To achieve this, we propose a new method called Denoised Diffusion Smoothing (DDS), which adopts randomized smoothing and diffusion-based denoising. We theoretically prove that processing ViTs directly with DDS can turn them into FViTs. We also show that Gaussian noise is nearly optimal for both $ell_2$ and $ell_infty$-norm cases. Finally, we demonstrate the effectiveness of our approach through comprehensive experiments and evaluations. Results show that FViTs are more robust against adversarial attacks while maintaining the explainability of attention, indicating higher faithfulness.
Read more5/6/2024

0
LookupViT: Compressing visual information to a limited number of tokens
Rajat Koner, Gagan Jain, Prateek Jain, Volker Tresp, Sujoy Paul
Vision Transformers (ViT) have emerged as the de-facto choice for numerous industry grade vision solutions. But their inference cost can be prohibitive for many settings, as they compute self-attention in each layer which suffers from quadratic computational complexity in the number of tokens. On the other hand, spatial information in images and spatio-temporal information in videos is usually sparse and redundant. In this work, we introduce LookupViT, that aims to exploit this information sparsity to reduce ViT inference cost. LookupViT provides a novel general purpose vision transformer block that operates by compressing information from higher resolution tokens to a fixed number of tokens. These few compressed tokens undergo meticulous processing, while the higher-resolution tokens are passed through computationally cheaper layers. Information sharing between these two token sets is enabled through a bidirectional cross-attention mechanism. The approach offers multiple advantages - (a) easy to implement on standard ML accelerators (GPUs/TPUs) via standard high-level operators, (b) applicable to standard ViT and its variants, thus generalizes to various tasks, (c) can handle different tokenization and attention approaches. LookupViT also offers flexibility for the compressed tokens, enabling performance-computation trade-offs in a single trained model. We show LookupViT's effectiveness on multiple domains - (a) for image-classification (ImageNet-1K and ImageNet-21K), (b) video classification (Kinetics400 and Something-Something V2), (c) image captioning (COCO-Captions) with a frozen encoder. LookupViT provides $2times$ reduction in FLOPs while upholding or improving accuracy across these domains. In addition, LookupViT also demonstrates out-of-the-box robustness and generalization on image classification (ImageNet-C,R,A,O), improving by up to $4%$ over ViT.
Read more7/18/2024