Illicit object detection in X-ray images using Vision Transformers

0

Sign in to get full access
Overview
- This research paper explores the use of Vision Transformers, a type of deep neural network, for the task of detecting illicit objects in X-ray images.
- The work was funded by the European Union's Horizon Europe research and innovation programme under grant agreement No 101073876 (Ceasefire).
Plain English Explanation
The researchers in this study aimed to develop a more effective way to automatically detect hidden or prohibited items, such as weapons or explosives, in X-ray scans of luggage or cargo. They used a type of deep learning model called a Vision Transformer, which is inspired by the success of Transformer models in natural language processing.
Unlike traditional Convolutional Neural Networks (CNNs) that process images in a grid-like fashion, Vision Transformers break the image down into smaller patches and process them sequentially, allowing the model to better capture long-range dependencies in the visual data. The researchers hypothesized that this approach would be more effective for detecting complex, irregularly-shaped illicit objects compared to standard object detection methods.
To test their approach, the researchers trained and evaluated the Vision Transformer model on a dataset of X-ray images containing a variety of prohibited items. They compared the performance of their model to other state-of-the-art object detection techniques and found that the Vision Transformer achieved superior results, demonstrating its potential for real-world applications in airport security and cargo screening.
Technical Explanation
The researchers proposed a Vision Transformer architecture for the task of illicit object detection in X-ray images. Unlike traditional Convolutional Neural Networks (CNNs), which process images in a grid-like fashion, Vision Transformers break the image down into smaller patches and process them sequentially, allowing the model to better capture long-range dependencies in the visual data.
The Vision Transformer model consists of an embedding layer that converts the input image into a sequence of patches, followed by a stack of Transformer encoder layers. The Transformer encoder layers apply self-attention mechanisms to the patch sequence, enabling the model to learn rich visual representations that capture global context and long-range dependencies.
To adapt the Vision Transformer for the object detection task, the researchers incorporated a Nested Transformer architecture, which uses a hierarchical structure to extract features at multiple scales. This allowed the model to effectively detect both small and large illicit objects within the X-ray images.
The researchers trained and evaluated their Vision Transformer model on a dataset of X-ray images containing a variety of prohibited items, such as weapons, explosives, and other contraband. They compared the performance of their model to other state-of-the-art object detection techniques, including CNN-based and hybrid CNN-Transformer models, and found that the Vision Transformer achieved superior results in terms of both detection accuracy and inference speed.
Critical Analysis
The researchers acknowledge several limitations and areas for future research. First, the dataset used in the study, while diverse, may not be representative of the full spectrum of illicit items that could be encountered in real-world scenarios. Expanding the dataset to include a wider range of prohibited objects, as well as variations in X-ray imaging conditions, would be an important next step to further validate the model's performance.
Additionally, the researchers did not address the potential for adversarial attacks, where carefully crafted perturbations could be used to fool the model and bypass security systems. Investigating the robustness of the Vision Transformer to such adversarial examples would be a crucial area for future research, especially for security-critical applications.
Another consideration is the interpretability of the Vision Transformer's decision-making process. As with many deep learning models, the internal workings of the Vision Transformer can be opaque, making it difficult to understand why the model makes certain predictions. Developing techniques to improve the explainability of the model's outputs could enhance trust and confidence in its use for high-stakes applications like airport security.
Conclusion
This research demonstrates the potential of Vision Transformers for the task of illicit object detection in X-ray images. By leveraging the model's ability to capture long-range dependencies and global context, the researchers were able to achieve state-of-the-art performance in detecting complex, irregularly-shaped prohibited items.
The successful application of Vision Transformers to this security-critical domain highlights the versatility and power of this emerging deep learning approach. As the technology continues to evolve, it may find broader applications in areas such as real-time detection and analysis of vehicles and pedestrians, further enhancing safety and security across a wide range of industries and scenarios.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Illicit object detection in X-ray images using Vision Transformers
Jorgen Cani, Ioannis Mademlis, Adamantia Anna Rebolledo Chrysochoou, Georgios Th. Papadopoulos
Illicit object detection is a critical task performed at various high-security locations, including airports, train stations, subways, and ports. The continuous and tedious work of examining thousands of X-ray images per hour can be mentally taxing. Thus, Deep Neural Networks (DNNs) can be used to automate the X-ray image analysis process, improve efficiency and alleviate the security officers' inspection burden. The neural architectures typically utilized in relevant literature are Convolutional Neural Networks (CNNs), with Vision Transformers (ViTs) rarely employed. In order to address this gap, this paper conducts a comprehensive evaluation of relevant ViT architectures on illicit item detection in X-ray images. This study utilizes both Transformer and hybrid backbones, such as SWIN and NextViT, and detectors, such as DINO and RT-DETR. The results demonstrate the remarkable accuracy of the DINO Transformer detector in the low-data regime, the impressive real-time performance of YOLOv8, and the effectiveness of the hybrid NextViT backbone.
Read more4/30/2024
👀
0
A Timely Survey on Vision Transformer for Deepfake Detection
Zhikan Wang, Zhongyao Cheng, Jiajie Xiong, Xun Xu, Tianrui Li, Bharadwaj Veeravalli, Xulei Yang
In recent years, the rapid advancement of deepfake technology has revolutionized content creation, lowering forgery costs while elevating quality. However, this progress brings forth pressing concerns such as infringements on individual rights, national security threats, and risks to public safety. To counter these challenges, various detection methodologies have emerged, with Vision Transformer (ViT)-based approaches showcasing superior performance in generality and efficiency. This survey presents a timely overview of ViT-based deepfake detection models, categorized into standalone, sequential, and parallel architectures. Furthermore, it succinctly delineates the structure and characteristics of each model. By analyzing existing research and addressing future directions, this survey aims to equip researchers with a nuanced understanding of ViT's pivotal role in deepfake detection, serving as a valuable reference for both academic and practical pursuits in this domain.
Read more5/15/2024
0
Liveness Detection in Computer Vision: Transformer-based Self-Supervised Learning for Face Anti-Spoofing
Arman Keresh, Pakizar Shamoi
Face recognition systems are increasingly used in biometric security for convenience and effectiveness. However, they remain vulnerable to spoofing attacks, where attackers use photos, videos, or masks to impersonate legitimate users. This research addresses these vulnerabilities by exploring the Vision Transformer (ViT) architecture, fine-tuned with the DINO framework. The DINO framework facilitates self-supervised learning, enabling the model to learn distinguishing features from unlabeled data. We compared the performance of the proposed fine-tuned ViT model using the DINO framework against a traditional CNN model, EfficientNet b2, on the face anti-spoofing task. Numerous tests on standard datasets show that the ViT model performs better than the CNN model in terms of accuracy and resistance to different spoofing methods. Additionally, we collected our own dataset from a biometric application to validate our findings further. This study highlights the superior performance of transformer-based architecture in identifying complex spoofing cues, leading to significant advancements in biometric security.
Read more6/21/2024
0
Exploring Self-Supervised Vision Transformers for Deepfake Detection: A Comparative Analysis
Huy H. Nguyen, Junichi Yamagishi, Isao Echizen
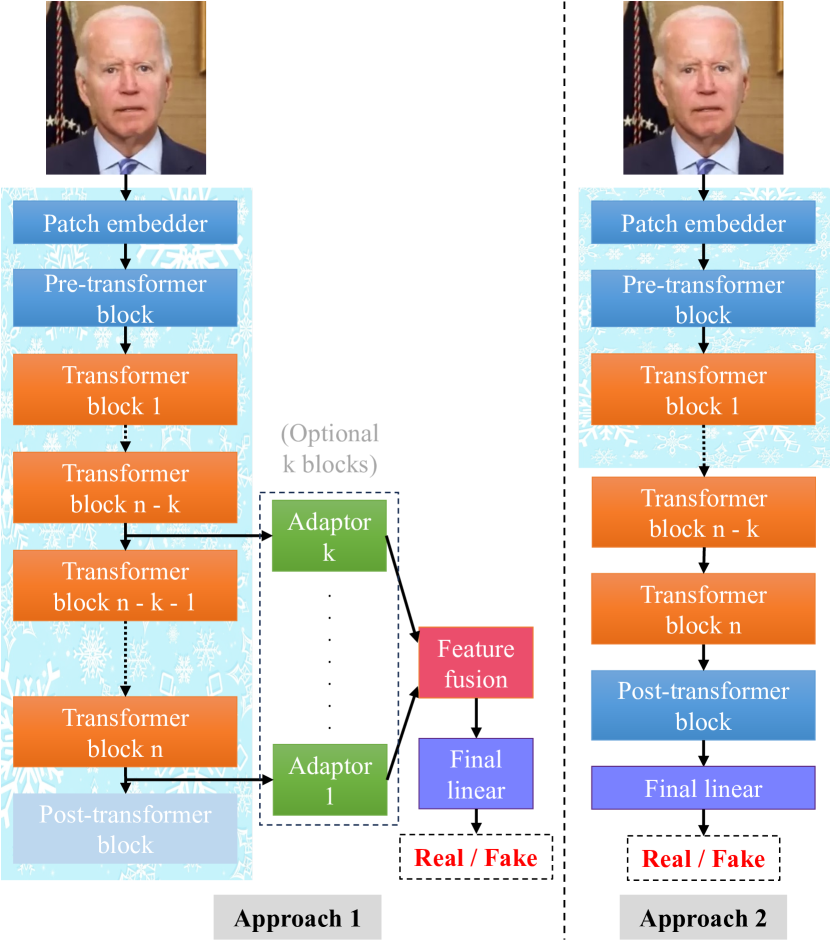
This paper investigates the effectiveness of self-supervised pre-trained vision transformers (ViTs) compared to supervised pre-trained ViTs and conventional neural networks (ConvNets) for detecting facial deepfake images and videos. It examines their potential for improved generalization and explainability, especially with limited training data. Despite the success of transformer architectures in various tasks, the deepfake detection community is hesitant to use large ViTs as feature extractors due to their perceived need for extensive data and suboptimal generalization with small datasets. This contrasts with ConvNets, which are already established as robust feature extractors. Additionally, training ViTs from scratch requires significant resources, limiting their use to large companies. Recent advancements in self-supervised learning (SSL) for ViTs, like masked autoencoders and DINOs, show adaptability across diverse tasks and semantic segmentation capabilities. By leveraging SSL ViTs for deepfake detection with modest data and partial fine-tuning, we find comparable adaptability to deepfake detection and explainability via the attention mechanism. Moreover, partial fine-tuning of ViTs is a resource-efficient option.
Read more8/12/2024