Image Fusion via Vision-Language Model

0
🖼️
Sign in to get full access
Overview
- This paper introduces a novel image fusion technique called Image Fusion via Vision-Language Model (FILM) that leverages textual information to guide the fusion process.
- Existing image fusion methods focus on visual features, but FILM uses descriptions generated by language models like ChatGPT to provide additional semantic context.
- FILM has shown promising results in four image fusion tasks: infrared-visible, medical, multi-exposure, and multi-focus image fusion.
- The authors also propose a vision-language dataset with ChatGPT-generated descriptions for eight image fusion datasets, enabling further research in this area.
Plain English Explanation
Image fusion is the process of combining multiple images into a single, more informative image. This can be useful in a variety of applications, such as medical imaging, surveillance, and satellite imaging. Existing image fusion methods typically focus on the visual features of the images, such as edges, textures, and colors.
However, the authors of this paper argue that these methods often overlook the deeper semantic information that can be extracted from the images. To address this, they have developed a new image fusion technique called FILM (Image Fusion via Vision-Language Model) that incorporates textual information to guide the fusion process.
The key idea behind FILM is to generate textual descriptions of the images using a language model like ChatGPT. These descriptions provide additional context and semantic information that can be used to enhance the image fusion process. For example, the language model might describe the objects, scenes, and relationships in the images, which can help the fusion algorithm better understand the content and structure of the images.
The authors have tested FILM on four different image fusion tasks, including infrared-visible, medical, multi-exposure, and multi-focus image fusion. In each case, FILM has shown promising results, outperforming existing methods that rely solely on visual features.
In addition to the FILM technique, the authors have also created a new dataset that pairs image fusion datasets with ChatGPT-generated textual descriptions. This dataset can be used by other researchers to explore the potential of vision-language models for image fusion and other related tasks.
Technical Explanation
The core of the FILM approach is the use of a vision-language model, specifically ChatGPT, to generate textual descriptions of the input images. These descriptions capture semantic information that goes beyond just the visual features of the images.
The FILM architecture consists of several key components:
- Image Encoder: This module extracts visual features from the input images using a convolutional neural network.
- Text Encoder: This module encodes the textual descriptions generated by ChatGPT using a transformer-based language model.
- Cross-Attention Fusion: The visual and textual features are fused using a cross-attention mechanism, which allows the textual information to guide the selection and weighting of the visual features.
- Fusion Output: The fused features are then used to generate the final, fused image.
The authors have evaluated FILM on four different image fusion tasks: infrared-visible, medical, multi-exposure, and multi-focus image fusion. In each case, FILM outperformed existing state-of-the-art methods that rely solely on visual features.
One key aspect of the FILM approach is the use of the DenseFusion architecture, which allows for the seamless integration of visual and textual features. This, combined with the Visualizing Dialogues technique for generating informative textual descriptions, enables FILM to capture a richer understanding of the image content and produce more meaningful fused outputs.
Critical Analysis
One potential limitation of the FILM approach is the reliance on the quality and accuracy of the textual descriptions generated by the language model. If the descriptions contain errors or fail to capture important semantic information, this could negatively impact the performance of the image fusion process.
Additionally, the authors do not provide a detailed analysis of the computational and memory requirements of the FILM architecture, which could be a concern for real-world applications with limited resources.
Another area for further research could be exploring the impact of different language models, such as GPT-3 or BERT, on the performance of FILM. It would be interesting to see how the choice of language model affects the quality of the textual descriptions and the overall fusion results.
Despite these potential limitations, the FILM approach represents a significant step forward in leveraging vision-language models for image fusion tasks. The authors' work highlights the potential of incorporating deeper semantic information beyond just visual features, and the proposed dataset could be a valuable resource for future research in this area.
Conclusion
The FILM technique introduced in this paper demonstrates the power of combining visual and textual information for image fusion tasks. By leveraging language models like ChatGPT to generate semantic descriptions of the input images, FILM is able to capture richer contextual understanding and produce more informative fused outputs.
The promising results across a range of image fusion applications, as well as the authors' introduction of a new vision-language dataset, suggest that this approach could have significant impact in fields such as medical imaging, surveillance, and remote sensing. As vision-language models continue to advance, the integration of textual information could become an increasingly important tool for enhancing image understanding and analysis.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🖼️
0
Image Fusion via Vision-Language Model
Zixiang Zhao, Lilun Deng, Haowen Bai, Yukun Cui, Zhipeng Zhang, Yulun Zhang, Haotong Qin, Dongdong Chen, Jiangshe Zhang, Peng Wang, Luc Van Gool
Image fusion integrates essential information from multiple images into a single composite, enhancing structures, textures, and refining imperfections. Existing methods predominantly focus on pixel-level and semantic visual features for recognition, but often overlook the deeper text-level semantic information beyond vision. Therefore, we introduce a novel fusion paradigm named image Fusion via vIsion-Language Model (FILM), for the first time, utilizing explicit textual information from source images to guide the fusion process. Specifically, FILM generates semantic prompts from images and inputs them into ChatGPT for comprehensive textual descriptions. These descriptions are fused within the textual domain and guide the visual information fusion, enhancing feature extraction and contextual understanding, directed by textual semantic information via cross-attention. FILM has shown promising results in four image fusion tasks: infrared-visible, medical, multi-exposure, and multi-focus image fusion. We also propose a vision-language dataset containing ChatGPT-generated paragraph descriptions for the eight image fusion datasets across four fusion tasks, facilitating future research in vision-language model-based image fusion. Code and dataset are available at https://github.com/Zhaozixiang1228/IF-FILM.
Read more7/12/2024

0
New!Infrared and Visible Image Fusion with Hierarchical Human Perception
Guang Yang, Jie Li, Xin Liu, Zhusi Zhong, Xinbo Gao
Image fusion combines images from multiple domains into one image, containing complementary information from source domains. Existing methods take pixel intensity, texture and high-level vision task information as the standards to determine preservation of information, lacking enhancement for human perception. We introduce an image fusion method, Hierarchical Perception Fusion (HPFusion), which leverages Large Vision-Language Model to incorporate hierarchical human semantic priors, preserving complementary information that satisfies human visual system. We propose multiple questions that humans focus on when viewing an image pair, and answers are generated via the Large Vision-Language Model according to images. The texts of answers are encoded into the fusion network, and the optimization also aims to guide the human semantic distribution of the fused image more similarly to source images, exploring complementary information within the human perception domain. Extensive experiments demonstrate our HPFusoin can achieve high-quality fusion results both for information preservation and human visual enhancement.
Read more9/17/2024

0
Distilling Vision-Language Models on Millions of Videos
Yue Zhao, Long Zhao, Xingyi Zhou, Jialin Wu, Chun-Te Chu, Hui Miao, Florian Schroff, Hartwig Adam, Ting Liu, Boqing Gong, Philipp Krahenbuhl, Liangzhe Yuan
The recent advance in vision-language models is largely attributed to the abundance of image-text data. We aim to replicate this success for video-language models, but there simply is not enough human-curated video-text data available. We thus resort to fine-tuning a video-language model from a strong image-language baseline with synthesized instructional data. The resulting video model by video-instruction-tuning (VIIT) is then used to auto-label millions of videos to generate high-quality captions. We show the adapted video-language model performs well on a wide range of video-language benchmarks. For instance, it surpasses the best prior result on open-ended NExT-QA by 2.8%. Besides, our model generates detailed descriptions for previously unseen videos, which provide better textual supervision than existing methods. Experiments show that a video-language dual-encoder model contrastively trained on these auto-generated captions is 3.8% better than the strongest baseline that also leverages vision-language models. Our best model outperforms state-of-the-art methods on MSR-VTT zero-shot text-to-video retrieval by 6%. As a side product, we generate the largest video caption dataset to date.
Read more4/17/2024
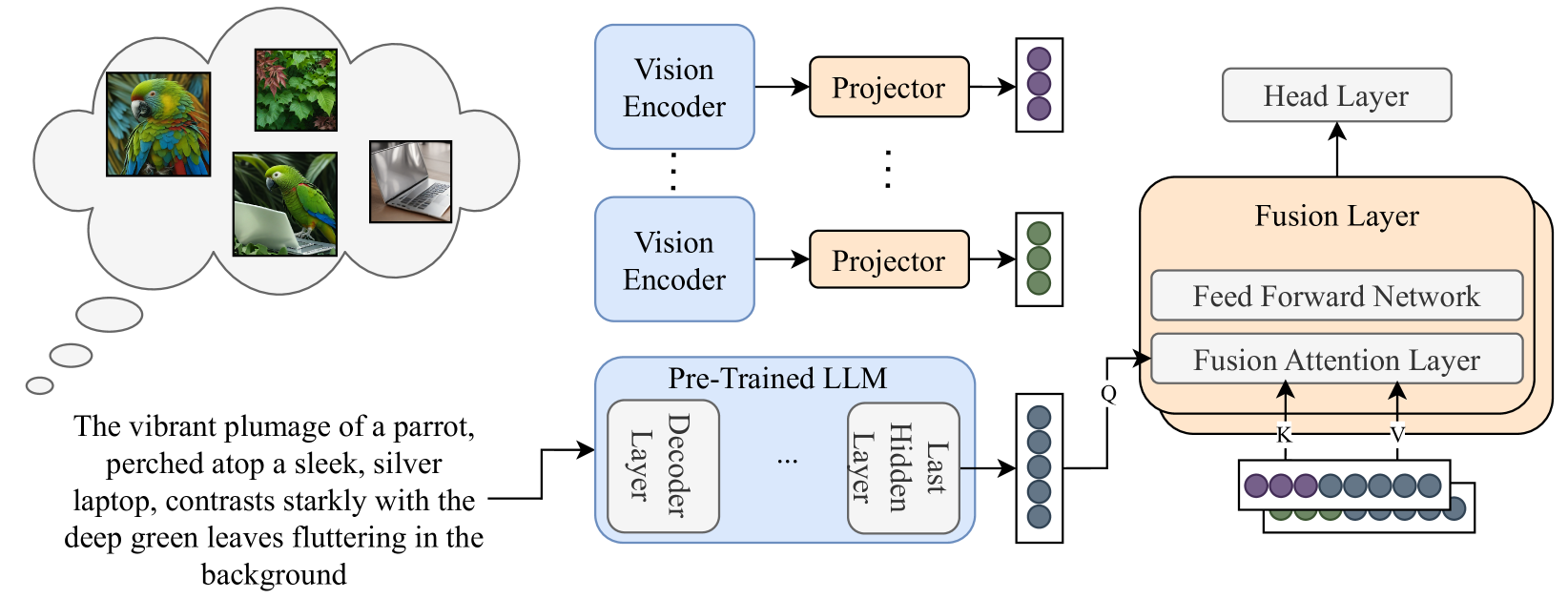
0
Improving Visual Commonsense in Language Models via Multiple Image Generation
Guy Yariv, Idan Schwartz, Yossi Adi, Sagie Benaim
Commonsense reasoning is fundamentally based on multimodal knowledge. However, existing large language models (LLMs) are primarily trained using textual data only, limiting their ability to incorporate essential visual information. In contrast, Visual Language Models, which excel at visually-oriented tasks, often fail at non-visual tasks such as basic commonsense reasoning. This divergence highlights a critical challenge - the integration of robust visual understanding with foundational text-based language reasoning. To this end, we introduce a method aimed at enhancing LLMs' visual commonsense. Specifically, our method generates multiple images based on the input text prompt and integrates these into the model's decision-making process by mixing their prediction probabilities. To facilitate multimodal grounded language modeling, we employ a late-fusion layer that combines the projected visual features with the output of a pre-trained LLM conditioned on text only. This late-fusion layer enables predictions based on comprehensive image-text knowledge as well as text only when this is required. We evaluate our approach using several visual commonsense reasoning tasks together with traditional NLP tasks, including common sense reasoning and reading comprehension. Our experimental results demonstrate significant superiority over existing baselines. When applied to recent state-of-the-art LLMs (e.g., Llama3), we observe improvements not only in visual common sense but also in traditional NLP benchmarks. Code and models are available under https://github.com/guyyariv/vLMIG.
Read more6/21/2024