An Image is Worth More Than 16x16 Patches: Exploring Transformers on Individual Pixels
2406.09415
0
0

Abstract
This work does not introduce a new method. Instead, we present an interesting finding that questions the necessity of the inductive bias -- locality in modern computer vision architectures. Concretely, we find that vanilla Transformers can operate by directly treating each individual pixel as a token and achieve highly performant results. This is substantially different from the popular design in Vision Transformer, which maintains the inductive bias from ConvNets towards local neighborhoods (e.g. by treating each 16x16 patch as a token). We mainly showcase the effectiveness of pixels-as-tokens across three well-studied tasks in computer vision: supervised learning for object classification, self-supervised learning via masked autoencoding, and image generation with diffusion models. Although directly operating on individual pixels is less computationally practical, we believe the community must be aware of this surprising piece of knowledge when devising the next generation of neural architectures for computer vision.
Create account to get full access
Overview
- This paper explores the use of Transformers, a type of deep learning model, for processing images at the individual pixel level rather than in larger 16x16 patches.
- The researchers investigate whether this fine-grained approach can outperform the more common patch-based methods used in Transformer-based image models.
- They evaluate the model's performance on tasks like image classification, reconstruction, and generation.
Plain English Explanation
In this paper, the researchers look at a different way of using Transformers, a type of AI model, to work with images. Typically, Transformer-based image models break the image up into larger 16x16 pixel patches and process them. But the researchers wondered if processing the image at the individual pixel level instead could lead to better performance.
So they built a model that looks at each individual pixel in an image, rather than larger chunks of pixels. They tested this model on tasks like identifying what's in an image, reconstructing an image from a partial or corrupted version, and generating new images.
The key idea is that by focusing on the smallest building blocks of the image (the individual pixels), the model might be able to capture more subtle details and patterns that get lost when you group pixels into larger patches. This could lead to better performance on various computer vision tasks.
The paper explores the pros and cons of this pixel-level approach compared to the more common patch-based methods used in Transformer-based image models. It provides insights into when and why the pixel-level approach might be advantageous.
Technical Explanation
The paper introduces a Transformer-based image model that operates directly on individual pixels, rather than the more common approach of processing the image in larger 16x16 pixel patches.
The researchers hypothesize that this fine-grained, pixel-level processing can capture more subtle details and patterns that get lost when using larger image patches. To test this, they evaluate the model's performance on tasks like image classification, reconstruction, and generation.
The model architecture consists of a Transformer encoder that processes each pixel individually, followed by task-specific heads for the different computer vision applications. The authors compare this pixel-level Transformer to more traditional patch-based Transformer models, as well as convolutional neural networks.
The experimental results show that in some cases, the pixel-level Transformer can outperform patch-based approaches, particularly on tasks that require fine-grained understanding of image content. However, the researchers also note that the computational cost of the pixel-level model is higher, which may limit its practical applicability.
Critical Analysis
The paper provides an interesting exploration of an alternative approach to using Transformers for computer vision tasks. The key idea of processing images at the individual pixel level rather than in larger patches is novel and could lead to performance improvements in certain scenarios.
However, the increased computational cost of the pixel-level model is a significant limitation that the authors acknowledge. In many practical applications, the computational efficiency of the model is just as important as its accuracy. The authors do not provide a clear sense of the trade-offs between the performance gains and the increased computational requirements.
Additionally, the paper does not delve deeply into the specific mechanisms by which the pixel-level approach confers advantages over patch-based methods. More analysis and explanation of the underlying reasons for the performance differences would help readers better understand the strengths and weaknesses of the proposed approach.
Further research could explore ways to mitigate the computational challenges of the pixel-level Transformer, such as through model optimization or the use of specialized hardware. Investigating the types of computer vision tasks where the pixel-level approach is most beneficial would also be a valuable direction for future work.
Conclusion
This paper presents a novel Transformer-based image model that operates at the individual pixel level, rather than the more common approach of processing larger image patches. The researchers find that in some cases, this fine-grained, pixel-level processing can outperform patch-based Transformer models, particularly on tasks that require a detailed understanding of image content.
However, the increased computational cost of the pixel-level model is a significant limitation that may restrict its practical applicability. Further research is needed to better understand the specific mechanisms behind the performance gains of the pixel-level approach and to explore ways to mitigate the computational challenges.
Overall, this paper offers an interesting perspective on the use of Transformers for computer vision and highlights the potential benefits of processing images at the lowest level of granularity. As the field of AI continues to evolve, innovative approaches like this may lead to new breakthroughs in image understanding and generation.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

An Image is Worth 32 Tokens for Reconstruction and Generation
Qihang Yu, Mark Weber, Xueqing Deng, Xiaohui Shen, Daniel Cremers, Liang-Chieh Chen
0
0
Recent advancements in generative models have highlighted the crucial role of image tokenization in the efficient synthesis of high-resolution images. Tokenization, which transforms images into latent representations, reduces computational demands compared to directly processing pixels and enhances the effectiveness and efficiency of the generation process. Prior methods, such as VQGAN, typically utilize 2D latent grids with fixed downsampling factors. However, these 2D tokenizations face challenges in managing the inherent redundancies present in images, where adjacent regions frequently display similarities. To overcome this issue, we introduce Transformer-based 1-Dimensional Tokenizer (TiTok), an innovative approach that tokenizes images into 1D latent sequences. TiTok provides a more compact latent representation, yielding substantially more efficient and effective representations than conventional techniques. For example, a 256 x 256 x 3 image can be reduced to just 32 discrete tokens, a significant reduction from the 256 or 1024 tokens obtained by prior methods. Despite its compact nature, TiTok achieves competitive performance to state-of-the-art approaches. Specifically, using the same generator framework, TiTok attains 1.97 gFID, outperforming MaskGIT baseline significantly by 4.21 at ImageNet 256 x 256 benchmark. The advantages of TiTok become even more significant when it comes to higher resolution. At ImageNet 512 x 512 benchmark, TiTok not only outperforms state-of-the-art diffusion model DiT-XL/2 (gFID 2.74 vs. 3.04), but also reduces the image tokens by 64x, leading to 410x faster generation process. Our best-performing variant can significantly surpasses DiT-XL/2 (gFID 2.13 vs. 3.04) while still generating high-quality samples 74x faster.
6/12/2024
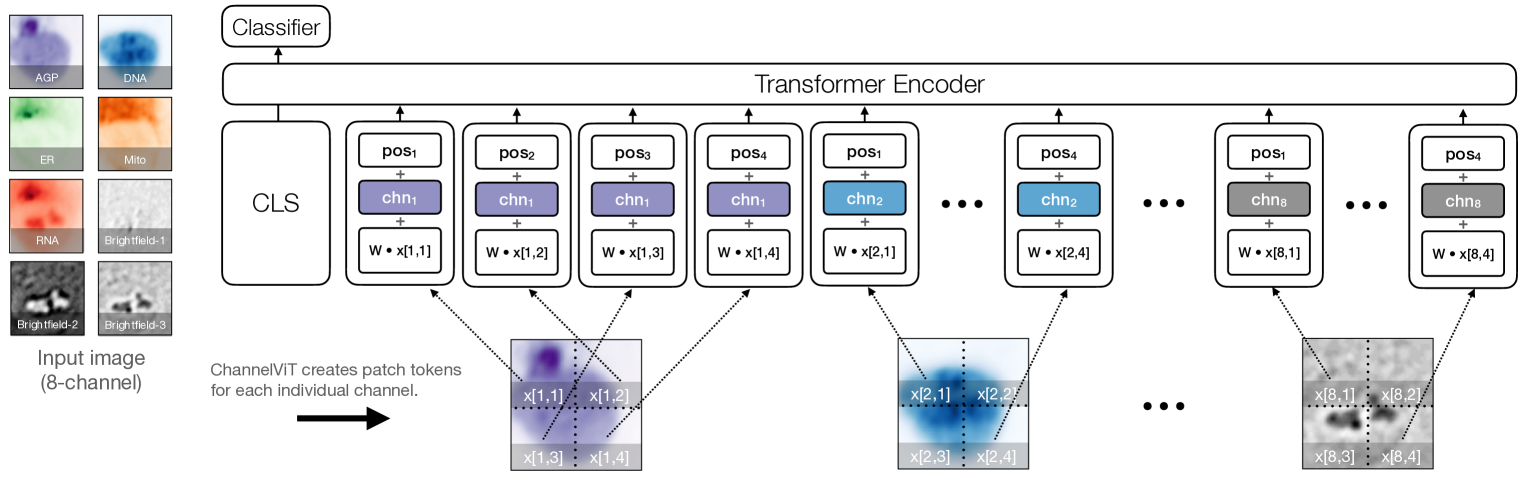
Channel Vision Transformers: An Image Is Worth 1 x 16 x 16 Words
Yujia Bao, Srinivasan Sivanandan, Theofanis Karaletsos
0
0
Vision Transformer (ViT) has emerged as a powerful architecture in the realm of modern computer vision. However, its application in certain imaging fields, such as microscopy and satellite imaging, presents unique challenges. In these domains, images often contain multiple channels, each carrying semantically distinct and independent information. Furthermore, the model must demonstrate robustness to sparsity in input channels, as they may not be densely available during training or testing. In this paper, we propose a modification to the ViT architecture that enhances reasoning across the input channels and introduce Hierarchical Channel Sampling (HCS) as an additional regularization technique to ensure robustness when only partial channels are presented during test time. Our proposed model, ChannelViT, constructs patch tokens independently from each input channel and utilizes a learnable channel embedding that is added to the patch tokens, similar to positional embeddings. We evaluate the performance of ChannelViT on ImageNet, JUMP-CP (microscopy cell imaging), and So2Sat (satellite imaging). Our results show that ChannelViT outperforms ViT on classification tasks and generalizes well, even when a subset of input channels is used during testing. Across our experiments, HCS proves to be a powerful regularizer, independent of the architecture employed, suggesting itself as a straightforward technique for robust ViT training. Lastly, we find that ChannelViT generalizes effectively even when there is limited access to all channels during training, highlighting its potential for multi-channel imaging under real-world conditions with sparse sensors. Our code is available at https://github.com/insitro/ChannelViT.
4/22/2024

Transformer based Pluralistic Image Completion with Reduced Information Loss
Qiankun Liu, Yuqi Jiang, Zhentao Tan, Dongdong Chen, Ying Fu, Qi Chu, Gang Hua, Nenghai Yu
0
0
Transformer based methods have achieved great success in image inpainting recently. However, we find that these solutions regard each pixel as a token, thus suffering from an information loss issue from two aspects: 1) They downsample the input image into much lower resolutions for efficiency consideration. 2) They quantize $256^3$ RGB values to a small number (such as 512) of quantized color values. The indices of quantized pixels are used as tokens for the inputs and prediction targets of the transformer. To mitigate these issues, we propose a new transformer based framework called PUT. Specifically, to avoid input downsampling while maintaining computation efficiency, we design a patch-based auto-encoder P-VQVAE. The encoder converts the masked image into non-overlapped patch tokens and the decoder recovers the masked regions from the inpainted tokens while keeping the unmasked regions unchanged. To eliminate the information loss caused by input quantization, an Un-quantized Transformer is applied. It directly takes features from the P-VQVAE encoder as input without any quantization and only regards the quantized tokens as prediction targets. Furthermore, to make the inpainting process more controllable, we introduce semantic and structural conditions as extra guidance. Extensive experiments show that our method greatly outperforms existing transformer based methods on image fidelity and achieves much higher diversity and better fidelity than state-of-the-art pluralistic inpainting methods on complex large-scale datasets (e.g., ImageNet). Codes are available at https://github.com/liuqk3/PUT.
4/16/2024
👀
Which Transformer to Favor: A Comparative Analysis of Efficiency in Vision Transformers
Tobias Christian Nauen, Sebastian Palacio, Andreas Dengel
0
0
Transformers come with a high computational cost, yet their effectiveness in addressing problems in language and vision has sparked extensive research aimed at enhancing their efficiency. However, diverse experimental conditions, spanning multiple input domains, prevent a fair comparison based solely on reported results, posing challenges for model selection. To address this gap in comparability, we design a comprehensive benchmark of more than 30 models for image classification, evaluating key efficiency aspects, including accuracy, speed, and memory usage. This benchmark provides a standardized baseline across the landscape of efficiency-oriented transformers and our framework of analysis, based on Pareto optimality, reveals surprising insights. Despite claims of other models being more efficient, ViT remains Pareto optimal across multiple metrics. We observe that hybrid attention-CNN models exhibit remarkable inference memory- and parameter-efficiency. Moreover, our benchmark shows that using a larger model in general is more efficient than using higher resolution images. Thanks to our holistic evaluation, we provide a centralized resource for practitioners and researchers, facilitating informed decisions when selecting transformers or measuring progress of the development of efficient transformers.
4/15/2024