LabelDistill: Label-guided Cross-modal Knowledge Distillation for Camera-based 3D Object Detection

0
Sign in to get full access
Overview
- This paper introduces LabelDistill, a novel approach for camera-based 3D object detection that leverages cross-modal knowledge distillation.
- The key idea is to guide the training of a 2D camera-based object detector using rich 3D object information from a separate 3D sensor, such as LiDAR.
- The method is shown to significantly improve the performance of 2D camera-based 3D object detection models compared to existing approaches.
Plain English Explanation
LabelDistill is a technique for improving the performance of 3D object detection using only 2D camera data. Typically, 3D object detection relies on more expensive sensors like LiDAR, which can provide detailed 3D information about objects in a scene.
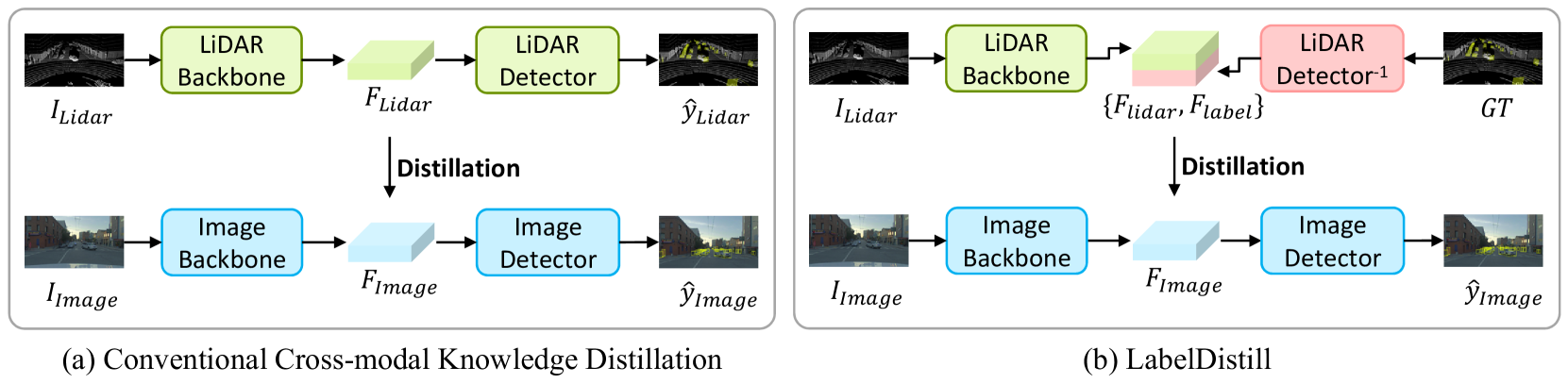
The key insight of LabelDistill is to take the knowledge learned by a model trained on LiDAR data and "distill" or transfer that knowledge to a camera-only model. This is done by having the camera-based model learn from the detailed 3D object labels produced by the LiDAR-based model.
By leveraging this cross-modal distillation of knowledge, the camera-only model is able to make more accurate 3D object predictions, even without the benefit of the 3D sensor data. This can lead to significant performance gains compared to training the camera model on its own, making 3D object detection more accessible and practical in scenarios where LiDAR sensors may not be available or cost-effective.
Technical Explanation
The LabelDistill framework consists of two main components: a teacher model trained on LiDAR data and a student model trained on camera data. The teacher model is a state-of-the-art 3D object detector that can produce highly accurate 3D object bounding boxes and other 3D information.
The student model is a more lightweight 2D camera-based object detector. During training, the student model learns not only from the ground truth 2D image annotations, but also from the rich 3D object labels produced by the teacher model. This cross-modal knowledge distillation process allows the student to benefit from the 3D understanding of the teacher, despite only having access to 2D camera inputs.
The authors demonstrate the effectiveness of LabelDistill on several benchmark datasets for camera-based 3D object detection. They show that the student model trained with LabelDistill significantly outperforms other camera-only 3D object detectors, achieving results on par with more expensive LiDAR-based approaches.
Critical Analysis
The LabelDistill approach offers a promising solution for enabling accurate 3D object detection using only 2D camera inputs. By leveraging the complementary strengths of camera and LiDAR sensors through knowledge distillation, the method is able to overcome some of the limitations of camera-only 3D object detection.
However, the paper does not address the potential issues that may arise when the camera and LiDAR sensors are not perfectly aligned or synchronized. In real-world deployment scenarios, such sensor misalignment could introduce errors that may degrade the performance of the distillation process.
Additionally, the paper does not explore the generalization capabilities of the LabelDistill approach. It remains to be seen how well the method would perform on datasets or scenarios that differ significantly from the training data, or how robust it would be to changes in the sensor configuration or environmental conditions.
Further research could also investigate the potential for end-to-end training of the entire LabelDistill framework, rather than the current two-stage approach of first training the teacher model and then distilling its knowledge into the student model.
Conclusion
The LabelDistill approach represents an important step forward in enabling accurate 3D object detection using only 2D camera inputs. By leveraging cross-modal knowledge distillation from a LiDAR-based teacher model, the method is able to significantly improve the performance of camera-only 3D object detectors.
This advance has the potential to make 3D object detection more accessible and practical in a wide range of applications, from autonomous vehicles to robotic systems, where the cost and complexity of LiDAR sensors may be prohibitive. As the authors demonstrate, LabelDistill can bring camera-based 3D detection closer to the capabilities of LiDAR-based approaches, paving the way for more widespread adoption of this technology.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
LabelDistill: Label-guided Cross-modal Knowledge Distillation for Camera-based 3D Object Detection
Sanmin Kim, Youngseok Kim, Sihwan Hwang, Hyeonjun Jeong, Dongsuk Kum
Recent advancements in camera-based 3D object detection have introduced cross-modal knowledge distillation to bridge the performance gap with LiDAR 3D detectors, leveraging the precise geometric information in LiDAR point clouds. However, existing cross-modal knowledge distillation methods tend to overlook the inherent imperfections of LiDAR, such as the ambiguity of measurements on distant or occluded objects, which should not be transferred to the image detector. To mitigate these imperfections in LiDAR teacher, we propose a novel method that leverages aleatoric uncertainty-free features from ground truth labels. In contrast to conventional label guidance approaches, we approximate the inverse function of the teacher's head to effectively embed label inputs into feature space. This approach provides additional accurate guidance alongside LiDAR teacher, thereby boosting the performance of the image detector. Additionally, we introduce feature partitioning, which effectively transfers knowledge from the teacher modality while preserving the distinctive features of the student, thereby maximizing the potential of both modalities. Experimental results demonstrate that our approach improves mAP and NDS by 5.1 points and 4.9 points compared to the baseline model, proving the effectiveness of our approach. The code is available at https://github.com/sanmin0312/LabelDistill
Read more7/16/2024

0
MapDistill: Boosting Efficient Camera-based HD Map Construction via Camera-LiDAR Fusion Model Distillation
Xiaoshuai Hao, Ruikai Li, Hui Zhang, Dingzhe Li, Rong Yin, Sangil Jung, Seung-In Park, ByungIn Yoo, Haimei Zhao, Jing Zhang
Online high-definition (HD) map construction is an important and challenging task in autonomous driving. Recently, there has been a growing interest in cost-effective multi-view camera-based methods without relying on other sensors like LiDAR. However, these methods suffer from a lack of explicit depth information, necessitating the use of large models to achieve satisfactory performance. To address this, we employ the Knowledge Distillation (KD) idea for efficient HD map construction for the first time and introduce a novel KD-based approach called MapDistill to transfer knowledge from a high-performance camera-LiDAR fusion model to a lightweight camera-only model. Specifically, we adopt the teacher-student architecture, i.e., a camera-LiDAR fusion model as the teacher and a lightweight camera model as the student, and devise a dual BEV transform module to facilitate cross-modal knowledge distillation while maintaining cost-effective camera-only deployment. Additionally, we present a comprehensive distillation scheme encompassing cross-modal relation distillation, dual-level feature distillation, and map head distillation. This approach alleviates knowledge transfer challenges between modalities, enabling the student model to learn improved feature representations for HD map construction. Experimental results on the challenging nuScenes dataset demonstrate the effectiveness of MapDistill, surpassing existing competitors by over 7.7 mAP or 4.5X speedup.
Read more7/17/2024
0
MonoTAKD: Teaching Assistant Knowledge Distillation for Monocular 3D Object Detection
Hou-I Liu, Christine Wu, Jen-Hao Cheng, Wenhao Chai, Shian-Yun Wang, Gaowen Liu, Jenq-Neng Hwang, Hong-Han Shuai, Wen-Huang Cheng
Monocular 3D object detection (Mono3D) is an indispensable research topic in autonomous driving, thanks to the cost-effective monocular camera sensors and its wide range of applications. Since the image perspective has depth ambiguity, the challenges of Mono3D lie in understanding 3D scene geometry and reconstructing 3D object information from a single image. Previous methods attempted to transfer 3D information directly from the LiDAR-based teacher to the camera-based student. However, a considerable gap in feature representation makes direct cross-modal distillation inefficient, resulting in a significant performance deterioration between the LiDAR-based teacher and the camera-based student. To address this issue, we propose the Teaching Assistant Knowledge Distillation (MonoTAKD) to break down the learning objective by integrating intra-modal distillation with cross-modal residual distillation. In particular, we employ a strong camera-based teaching assistant model to distill powerful visual knowledge effectively through intra-modal distillation. Subsequently, we introduce the cross-modal residual distillation to transfer the 3D spatial cues. By acquiring both visual knowledge and 3D spatial cues, the predictions of our approach are rigorously evaluated on the KITTI 3D object detection benchmark and achieve state-of-the-art performance in Mono3D.
Read more4/9/2024

0
Make a Strong Teacher with Label Assistance: A Novel Knowledge Distillation Approach for Semantic Segmentation
Shoumeng Qiu, Jie Chen, Xinrun Li, Ru Wan, Xiangyang Xue, Jian Pu
In this paper, we introduce a novel knowledge distillation approach for the semantic segmentation task. Unlike previous methods that rely on power-trained teachers or other modalities to provide additional knowledge, our approach does not require complex teacher models or information from extra sensors. Specifically, for the teacher model training, we propose to noise the label and then incorporate it into input to effectively boost the lightweight teacher performance. To ensure the robustness of the teacher model against the introduced noise, we propose a dual-path consistency training strategy featuring a distance loss between the outputs of two paths. For the student model training, we keep it consistent with the standard distillation for simplicity. Our approach not only boosts the efficacy of knowledge distillation but also increases the flexibility in selecting teacher and student models. To demonstrate the advantages of our Label Assisted Distillation (LAD) method, we conduct extensive experiments on five challenging datasets including Cityscapes, ADE20K, PASCAL-VOC, COCO-Stuff 10K, and COCO-Stuff 164K, five popular models: FCN, PSPNet, DeepLabV3, STDC, and OCRNet, and results show the effectiveness and generalization of our approach. We posit that incorporating labels into the input, as demonstrated in our work, will provide valuable insights into related fields. Code is available at https://github.com/skyshoumeng/Label_Assisted_Distillation.
Read more7/19/2024