Open Vocabulary 3D Scene Understanding via Geometry Guided Self-Distillation

0

Sign in to get full access
Overview
• This paper presents a novel approach for open vocabulary 3D scene understanding, which allows models to recognize a wide range of object categories without being limited to a predefined set.
• The key innovation is a self-distillation technique that leverages 3D geometry to guide the learning process, enabling the model to acquire richer visual representations and generalize to new object classes.
• The method outperforms state-of-the-art approaches on several 3D scene understanding benchmarks, demonstrating its effectiveness in supporting open-ended 3D perception.
Plain English Explanation
• Traditional 3D scene understanding models are typically trained to recognize only a fixed set of object categories, limiting their real-world applicability. This paper introduces a new approach that allows the model to recognize a much wider range of objects, including ones it hasn't been explicitly trained on.
• The key idea is to use the 3D geometry of the scene as a guide during the training process. By learning to relate the visual appearance of objects to their 3D shape and spatial arrangement, the model can acquire a richer understanding of the world that helps it generalize to new, unseen object classes.
• This "self-distillation" technique, where the model essentially teaches itself, leads to significant performance gains compared to prior methods on benchmark 3D scene understanding tasks. It represents an important step towards developing more flexible and capable 3D perception systems.
Technical Explanation
• The proposed approach builds on recent work in 3D feature distillation and geometry-aware score distillation, using 3D geometry as a guiding signal to help the model learn more generalizable visual representations.
• The key innovation is a self-distillation process, where the model first learns to predict 3D bounding boxes and semantic labels for a set of known object categories. It then uses this 3D geometric information to distill additional knowledge into the model, helping it acquire richer visual features that support open-vocabulary recognition.
• Experiments on standard 3D scene understanding benchmarks, such as ScanNet and NYUv2, demonstrate that this approach outperforms prior state-of-the-art methods in terms of both open-vocabulary recognition performance and generalization to novel object classes.
Critical Analysis
• One potential limitation of the proposed approach is that it relies on the availability of accurate 3D geometric information, which may not always be easy to obtain in real-world scenarios. Further research is needed to explore ways of leveraging weaker or more noisy 3D cues.
• Additionally, the paper does not provide a detailed analysis of the types of object categories that the model is able to recognize beyond the known set. It would be valuable to better understand the model's strengths and weaknesses in this regard, as well as the factors that contribute to its ability to generalize.
• While the results are promising, the paper could also benefit from a more thorough comparison to alternative techniques for open-vocabulary 3D perception, such as those based on text-to-3D mapping or retrieval-augmented score distillation.
Conclusion
• This paper presents a novel approach for open vocabulary 3D scene understanding that leverages 3D geometric information to guide the learning of more generalizable visual representations.
• By using a self-distillation technique, the model is able to outperform state-of-the-art methods on several 3D scene understanding benchmarks, demonstrating its potential to support more flexible and capable 3D perception systems.
• The research highlights the value of incorporating 3D geometric cues into deep learning models, and suggests that further advancements in this direction could lead to significant improvements in open-ended 3D scene understanding.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Open Vocabulary 3D Scene Understanding via Geometry Guided Self-Distillation
Pengfei Wang, Yuxi Wang, Shuai Li, Zhaoxiang Zhang, Zhen Lei, Lei Zhang
The scarcity of large-scale 3D-text paired data poses a great challenge on open vocabulary 3D scene understanding, and hence it is popular to leverage internet-scale 2D data and transfer their open vocabulary capabilities to 3D models through knowledge distillation. However, the existing distillation-based 3D scene understanding approaches rely on the representation capacity of 2D models, disregarding the exploration of geometric priors and inherent representational advantages offered by 3D data. In this paper, we propose an effective approach, namely Geometry Guided Self-Distillation (GGSD), to learn superior 3D representations from 2D pre-trained models. Specifically, we first design a geometry guided distillation module to distill knowledge from 2D models, and then leverage the 3D geometric priors to alleviate the inherent noise in 2D models and enhance the representation learning process. Due to the advantages of 3D representation, the performance of the distilled 3D student model can significantly surpass that of the 2D teacher model. This motivates us to further leverage the representation advantages of 3D data through self-distillation. As a result, our proposed GGSD approach outperforms the existing open vocabulary 3D scene understanding methods by a large margin, as demonstrated by our experiments on both indoor and outdoor benchmark datasets.
Read more7/19/2024

0
Enhancing Generalizability of Representation Learning for Data-Efficient 3D Scene Understanding
Yunsong Wang, Na Zhao, Gim Hee Lee
The field of self-supervised 3D representation learning has emerged as a promising solution to alleviate the challenge presented by the scarcity of extensive, well-annotated datasets. However, it continues to be hindered by the lack of diverse, large-scale, real-world 3D scene datasets for source data. To address this shortfall, we propose Generalizable Representation Learning (GRL), where we devise a generative Bayesian network to produce diverse synthetic scenes with real-world patterns, and conduct pre-training with a joint objective. By jointly learning a coarse-to-fine contrastive learning task and an occlusion-aware reconstruction task, the model is primed with transferable, geometry-informed representations. Post pre-training on synthetic data, the acquired knowledge of the model can be seamlessly transferred to two principal downstream tasks associated with 3D scene understanding, namely 3D object detection and 3D semantic segmentation, using real-world benchmark datasets. A thorough series of experiments robustly display our method's consistent superiority over existing state-of-the-art pre-training approaches.
Read more6/18/2024

0
Image-to-Lidar Relational Distillation for Autonomous Driving Data
Anas Mahmoud, Ali Harakeh, Steven Waslander
Pre-trained on extensive and diverse multi-modal datasets, 2D foundation models excel at addressing 2D tasks with little or no downstream supervision, owing to their robust representations. The emergence of 2D-to-3D distillation frameworks has extended these capabilities to 3D models. However, distilling 3D representations for autonomous driving datasets presents challenges like self-similarity, class imbalance, and point cloud sparsity, hindering the effectiveness of contrastive distillation, especially in zero-shot learning contexts. Whereas other methodologies, such as similarity-based distillation, enhance zero-shot performance, they tend to yield less discriminative representations, diminishing few-shot performance. We investigate the gap in structure between the 2D and the 3D representations that result from state-of-the-art distillation frameworks and reveal a significant mismatch between the two. Additionally, we demonstrate that the observed structural gap is negatively correlated with the efficacy of the distilled representations on zero-shot and few-shot 3D semantic segmentation. To bridge this gap, we propose a relational distillation framework enforcing intra-modal and cross-modal constraints, resulting in distilled 3D representations that closely capture the structure of the 2D representation. This alignment significantly enhances 3D representation performance over those learned through contrastive distillation in zero-shot segmentation tasks. Furthermore, our relational loss consistently improves the quality of 3D representations in both in-distribution and out-of-distribution few-shot segmentation tasks, outperforming approaches that rely on the similarity loss.
Read more9/4/2024
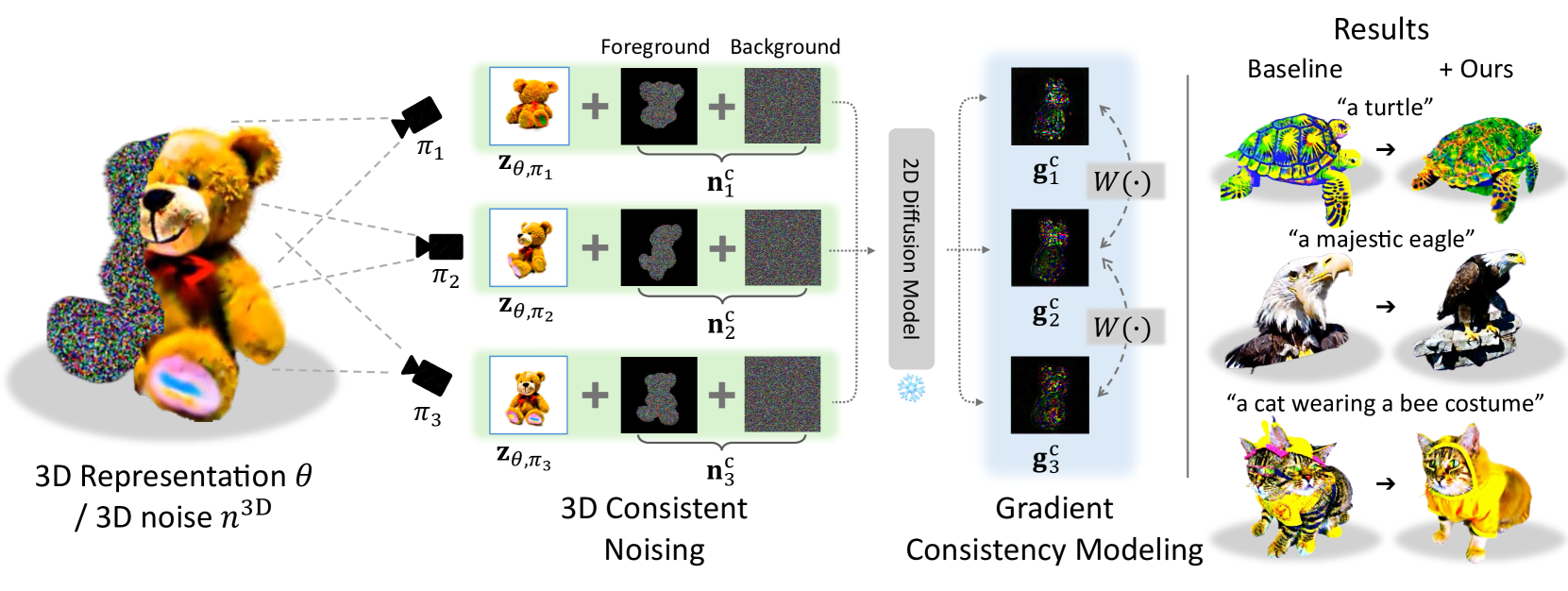
0
Geometry-Aware Score Distillation via 3D Consistent Noising and Gradient Consistency Modeling
Min-Seop Kwak, Donghoon Ahn, Ines Hyeonsu Kim, Jin-Hwa Kim, Seungryong Kim
Score distillation sampling (SDS), the methodology in which the score from pretrained 2D diffusion models is distilled into 3D representation, has recently brought significant advancements in text-to-3D generation task. However, this approach is still confronted with critical geometric inconsistency problems such as the Janus problem. Starting from a hypothesis that such inconsistency problems may be induced by multiview inconsistencies between 2D scores predicted from various viewpoints, we introduce GSD, a simple and general plug-and-play framework for incorporating 3D consistency and therefore geometry awareness into the SDS process. Our methodology is composed of three components: 3D consistent noising, designed to produce 3D consistent noise maps that perfectly follow the standard Gaussian distribution, geometry-based gradient warping for identifying correspondences between predicted gradients of different viewpoints, and novel gradient consistency loss to optimize the scene geometry toward producing more consistent gradients. We demonstrate that our method significantly improves performance, successfully addressing the geometric inconsistency problems in text-to-3D generation task with minimal computation cost and being compatible with existing score distillation-based models. Our project page is available at https://ku-cvlab.github.io/GSD/.
Read more7/2/2024