ImageInWords: Unlocking Hyper-Detailed Image Descriptions

0

Sign in to get full access
Overview
- This paper introduces the ImageInWords dataset, a large-scale dataset of hyper-detailed image descriptions that aims to push the boundaries of image captioning and visual question answering.
- The dataset contains over 2.5 million image-description pairs, with descriptions that are significantly more detailed and comprehensive than existing benchmarks.
- The authors use this dataset to train and evaluate state-of-the-art vision-language models, exploring their ability to generate fine-grained, multi-sentence descriptions of images.
Plain English Explanation
The ImageInWords dataset is a new, large collection of images paired with very detailed, multi-sentence descriptions. This aims to advance the field of image captioning, where computers try to automatically generate text descriptions of images.
Most existing image captioning datasets have relatively short, simple descriptions. In contrast, the ImageInWords dataset contains much more comprehensive and nuanced descriptions, covering a wide range of visual elements in great detail. For example, a description might go into depth about the specific colors, textures, and arrangements of objects in an image, rather than just naming the main objects.
By training powerful vision-language models on this rich dataset, the researchers hope to push the boundaries of what these models can do. They want to see if the models can learn to generate hyper-detailed, multi-sentence descriptions that capture the full complexity of an image, going well beyond basic captioning.
This could have important applications in areas like accessibility, where detailed image descriptions are crucial for the visually impaired. It could also aid tasks like visual question answering, where a model needs to understand and reason about images in depth to answer complex questions about them.
Technical Explanation
The ImageInWords dataset contains over 2.5 million image-description pairs, with descriptions that are significantly more detailed and comprehensive than existing benchmarks like COCO and Flickr30k.
The dataset was collected by crowdsourcing detailed, multi-sentence descriptions for a diverse set of images. The descriptions cover a wide range of visual elements, including objects, materials, colors, textures, spatial relationships, and higher-level scene semantics.
The authors use this dataset to train and evaluate state-of-the-art vision-language models, such as CLIP and LXMERT, exploring their ability to generate fine-grained, multi-sentence descriptions of images. They find that these models can indeed learn to produce significantly more detailed and comprehensive descriptions when trained on the ImageInWords dataset, compared to standard captioning benchmarks.
Critical Analysis
The ImageInWords dataset represents an important step forward in image captioning and visual understanding, providing a new benchmark to push the limits of what vision-language models can do. By focusing on hyper-detailed descriptions, the dataset encourages models to move beyond simply naming the main objects in an image and instead develop a deeper, more nuanced understanding of visual scenes.
However, the dataset also has some potential limitations. The crowdsourcing process used to collect the descriptions may introduce biases, and it's unclear how well the descriptions generalize to a broader range of images beyond the specific set included in the dataset.
Additionally, while the detailed descriptions are valuable, it's not yet clear how they might be best utilized in practical applications. Further research is needed to understand how these rich, multi-sentence descriptions can be integrated into real-world systems for tasks like accessibility, visual question answering, and beyond.
Conclusion
The ImageInWords dataset represents an important advance in the field of image captioning and visual understanding. By providing a large-scale dataset of hyper-detailed image descriptions, it challenges vision-language models to move beyond basic object recognition and develop a more comprehensive understanding of visual scenes.
While the dataset has some potential limitations, it opens up new avenues for research and innovation in areas like accessibility, visual question answering, and the broader goal of building AI systems that can truly understand and reason about the visual world. As the field continues to progress, the ImageInWords dataset and similar efforts will play a crucial role in pushing the boundaries of what's possible.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
ImageInWords: Unlocking Hyper-Detailed Image Descriptions
Roopal Garg, Andrea Burns, Burcu Karagol Ayan, Yonatan Bitton, Ceslee Montgomery, Yasumasa Onoe, Andrew Bunner, Ranjay Krishna, Jason Baldridge, Radu Soricut
Despite the longstanding adage an image is worth a thousand words, creating accurate and hyper-detailed image descriptions for training Vision-Language models remains challenging. Current datasets typically have web-scraped descriptions that are short, low-granularity, and often contain details unrelated to the visual content. As a result, models trained on such data generate descriptions replete with missing information, visual inconsistencies, and hallucinations. To address these issues, we introduce ImageInWords (IIW), a carefully designed human-in-the-loop annotation framework for curating hyper-detailed image descriptions and a new dataset resulting from this process. We validate the framework through evaluations focused on the quality of the dataset and its utility for fine-tuning with considerations for readability, comprehensiveness, specificity, hallucinations, and human-likeness. Our dataset significantly improves across these dimensions compared to recently released datasets (+66%) and GPT-4V outputs (+48%). Furthermore, models fine-tuned with IIW data excel by +31% against prior work along the same human evaluation dimensions. Given our fine-tuned models, we also evaluate text-to-image generation and vision-language reasoning. Our model's descriptions can generate images closest to the original, as judged by both automated and human metrics. We also find our model produces more compositionally rich descriptions, outperforming the best baseline by up to 6% on ARO, SVO-Probes, and Winoground datasets.
Read more5/7/2024

0
Image Textualization: An Automatic Framework for Creating Accurate and Detailed Image Descriptions
Renjie Pi, Jianshu Zhang, Jipeng Zhang, Rui Pan, Zhekai Chen, Tong Zhang
Image description datasets play a crucial role in the advancement of various applications such as image understanding, text-to-image generation, and text-image retrieval. Currently, image description datasets primarily originate from two sources. One source is the scraping of image-text pairs from the web. Despite their abundance, these descriptions are often of low quality and noisy. Another is through human labeling. Datasets such as COCO are generally very short and lack details. Although detailed image descriptions can be annotated by humans, the high annotation cost limits the feasibility. These limitations underscore the need for more efficient and scalable methods to generate accurate and detailed image descriptions. In this paper, we propose an innovative framework termed Image Textualization (IT), which automatically produces high-quality image descriptions by leveraging existing multi-modal large language models (MLLMs) and multiple vision expert models in a collaborative manner, which maximally convert the visual information into text. To address the current lack of benchmarks for detailed descriptions, we propose several benchmarks for comprehensive evaluation, which verifies the quality of image descriptions created by our framework. Furthermore, we show that LLaVA-7B, benefiting from training on IT-curated descriptions, acquire improved capability to generate richer image descriptions, substantially increasing the length and detail of their output with less hallucination.
Read more6/12/2024
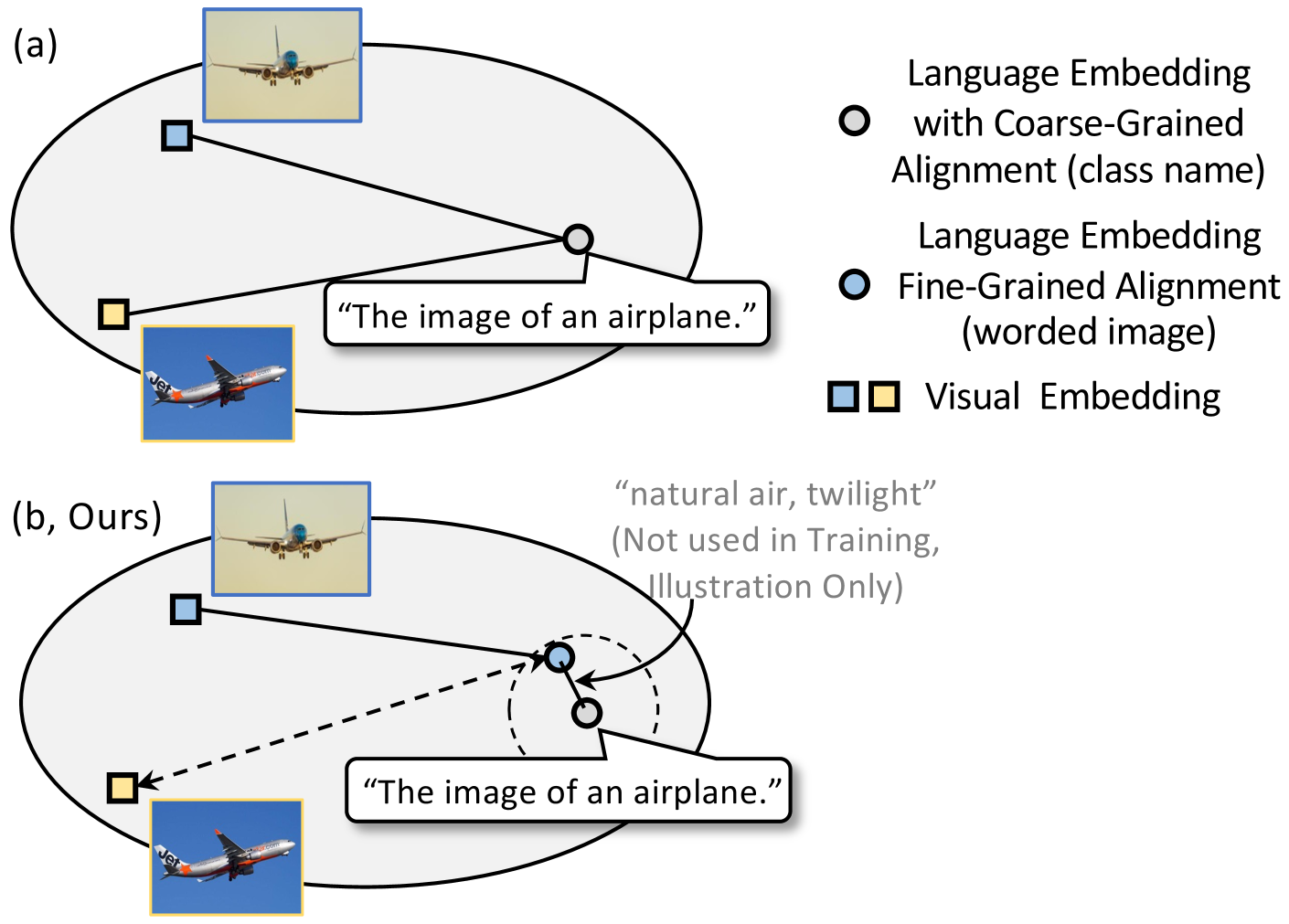
0
WIDIn: Wording Image for Domain-Invariant Representation in Single-Source Domain Generalization
Jiawei Ma, Yulei Niu, Shiyuan Huang, Guangxing Han, Shih-Fu Chang
Language has been useful in extending the vision encoder to data from diverse distributions without empirical discovery in training domains. However, as the image description is mostly at coarse-grained level and ignores visual details, the resulted embeddings are still ineffective in overcoming complexity of domains at inference time. We present a self-supervision framework WIDIn, Wording Images for Domain-Invariant representation, to disentangle discriminative visual representation, by only leveraging data in a single domain and without any test prior. Specifically, for each image, we first estimate the language embedding with fine-grained alignment, which can be consequently used to adaptively identify and then remove domain-specific counterpart from the raw visual embedding. WIDIn can be applied to both pretrained vision-language models like CLIP, and separately trained uni-modal models like MoCo and BERT. Experimental studies on three domain generalization datasets demonstrate the effectiveness of our approach.
Read more5/29/2024

0
A Picture is Worth More Than 77 Text Tokens: Evaluating CLIP-Style Models on Dense Captions
Jack Urbanek, Florian Bordes, Pietro Astolfi, Mary Williamson, Vasu Sharma, Adriana Romero-Soriano
Curation methods for massive vision-language datasets trade off between dataset size and quality. However, even the highest quality of available curated captions are far too short to capture the rich visual detail in an image. To show the value of dense and highly-aligned image-text pairs, we collect the Densely Captioned Images (DCI) dataset, containing 7805 natural images human-annotated with mask-aligned descriptions averaging above 1000 words each. With precise and reliable captions associated with specific parts of an image, we can evaluate vision-language models' (VLMs) understanding of image content with a novel task that matches each caption with its corresponding subcrop. As current models are often limited to 77 text tokens, we also introduce a summarized version (sDCI) in which each caption length is limited. We show that modern techniques that make progress on standard benchmarks do not correspond with significant improvement on our sDCI based benchmark. Lastly, we finetune CLIP using sDCI and show significant improvements over the baseline despite a small training set. By releasing the first human annotated dense image captioning dataset, we hope to enable the development of new benchmarks or fine-tuning recipes for the next generation of VLMs to come.
Read more6/18/2024