The Impact of Reasoning Step Length on Large Language Models
2401.04925
2
0
Abstract
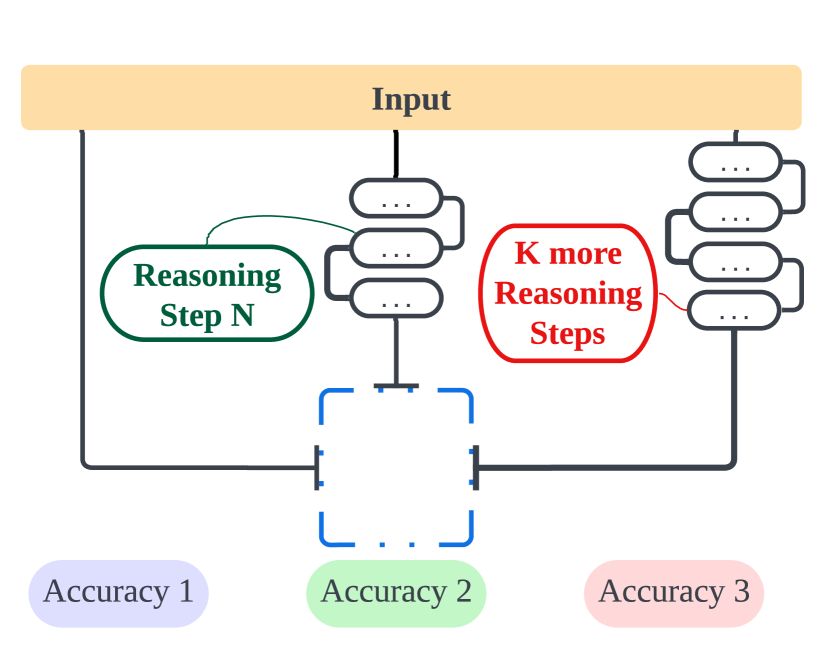
Chain of Thought (CoT) is significant in improving the reasoning abilities of large language models (LLMs). However, the correlation between the effectiveness of CoT and the length of reasoning steps in prompts remains largely unknown. To shed light on this, we have conducted several empirical experiments to explore the relations. Specifically, we design experiments that expand and compress the rationale reasoning steps within CoT demonstrations while keeping all other factors constant. We have the following key findings. First, the results indicate that lengthening the reasoning steps in prompts, even without adding new information into the prompt, considerably enhances LLMs' reasoning abilities across multiple datasets. Alternatively, shortening the reasoning steps, even while preserving the key information, significantly diminishes the reasoning abilities of models. This finding highlights the importance of the number of steps in CoT prompts and provides practical guidance to make better use of LLMs' potential in complex problem-solving scenarios. Second, we also investigated the relationship between the performance of CoT and the rationales used in demonstrations. Surprisingly, the result shows that even incorrect rationales can yield favorable outcomes if they maintain the requisite length of inference. Third, we observed that the advantages of increasing reasoning steps are task-dependent: simpler tasks require fewer steps, whereas complex tasks gain significantly from longer inference sequences. The code is available at https://github.com/MingyuJ666/The-Impact-of-Reasoning-Step-Length-on-Large-Language-Models
Create account to get full access
Overview
- This paper examines the impact of reasoning step length on the performance of large language models (LLMs) in various tasks.
- The researchers investigate how the number of reasoning steps in prompts affects the models' ability to generate accurate and coherent responses.
- The findings provide insights into the interplay between reasoning complexity and LLM capabilities, with implications for the design of effective prompting strategies.
Plain English Explanation
The paper looks at how the length of the reasoning process, or the number of steps involved, affects the performance of large language models (LLMs) - the powerful AI systems that can generate human-like text. The researchers wanted to understand how the complexity of the reasoning required in a prompt (the instructions given to the model) impacts the model's ability to produce accurate and logical responses.
For example, if you ask an LLM to solve a multi-step math problem, does it perform better when the prompt includes a detailed, step-by-step solution, or when the prompt is more concise and leaves some of the reasoning up to the model? The researchers explored this question across a range of tasks, from answering general knowledge questions to engaging in open-ended discussions.
The findings from this study provide valuable insights into the relationship between the reasoning complexity in prompts and the capabilities of large language models. This knowledge can help researchers and developers design more effective prompts and leverage LLMs more efficiently for various applications, such as assisting with complex problem-solving, verifying the reasoning of LLMs, and boosting the reasoning abilities of LLMs through prompting.
Technical Explanation
The researchers conducted a series of experiments to investigate the impact of reasoning step length on the performance of large language models (LLMs). They used prompts with varying degrees of step-by-step reasoning, from concise instructions to more detailed, multi-step solutions, and evaluated the models' responses across a range of tasks, including open-ended question answering, mathematical reasoning, and general language understanding.
The findings suggest that the optimal reasoning step length can vary depending on the task and the specific capabilities of the LLM being used. In some cases, providing more detailed, step-by-step reasoning in the prompt led to better model performance, as it helped guide the model's thought process and ensured it addressed all the necessary components of the problem. However, in other cases, a more concise prompt that left more of the reasoning up to the model resulted in better outcomes, as it allowed the LLM to leverage its own internal knowledge and problem-solving abilities.
The researchers also explored the relationship between reasoning step length and the empirical complexity of the task, finding that the optimal step length often depended on the inherent difficulty of the problem.
Critical Analysis
The paper provides a valuable contribution to the understanding of how the reasoning complexity in prompts affects the performance of large language models. The researchers have designed a thorough experimental setup and explored the topic across a range of tasks, which strengthens the reliability and generalizability of their findings.
However, the paper does not delve deeply into the potential limitations of the research or areas for further exploration. For example, the study focuses on a limited set of LLM architectures and training datasets, and it would be interesting to see how the results might vary with different model types or data sources.
Additionally, the paper does not address the potential ethical implications of these findings, such as how the use of prompting strategies that maximize model performance might impact the transparency and interpretability of LLM-powered systems. These are important considerations that could be explored in future research.
Conclusion
The findings of this paper offer important insights into the complex interplay between the reasoning complexity of prompts and the capabilities of large language models. By understanding the optimal step length for different tasks and scenarios, researchers and developers can design more effective prompting strategies to leverage the full potential of LLMs for a wide range of applications, from problem-solving to open-ended reasoning.
As the field of natural language processing continues to advance, this research contributes to our understanding of the nuances and limitations of large language models, paving the way for more robust and reliable AI systems that can tackle increasingly complex challenges.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Break the Chain: Large Language Models Can be Shortcut Reasoners
Mengru Ding, Hanmeng Liu, Zhizhang Fu, Jian Song, Wenbo Xie, Yue Zhang
0
0
Recent advancements in Chain-of-Thought (CoT) reasoning utilize complex modules but are hampered by high token consumption, limited applicability, and challenges in reproducibility. This paper conducts a critical evaluation of CoT prompting, extending beyond arithmetic to include complex logical and commonsense reasoning tasks, areas where standard CoT methods fall short. We propose the integration of human-like heuristics and shortcuts into language models (LMs) through break the chain strategies. These strategies disrupt traditional CoT processes using controlled variables to assess their efficacy. Additionally, we develop innovative zero-shot prompting strategies that encourage the use of shortcuts, enabling LMs to quickly exploit reasoning clues and bypass detailed procedural steps. Our comprehensive experiments across various LMs, both commercial and open-source, reveal that LMs maintain effective performance with break the chain strategies. We also introduce ShortcutQA, a dataset specifically designed to evaluate reasoning through shortcuts, compiled from competitive tests optimized for heuristic reasoning tasks such as forward/backward reasoning and simplification. Our analysis confirms that ShortcutQA not only poses a robust challenge to LMs but also serves as an essential benchmark for enhancing reasoning efficiency in AI.
6/12/2024
💬
Boosting Language Models Reasoning with Chain-of-Knowledge Prompting
Jianing Wang, Qiushi Sun, Xiang Li, Ming Gao
0
0
Recently, Chain-of-Thought (CoT) prompting has delivered success on complex reasoning tasks, which aims at designing a simple prompt like ``Let's think step by step'' or multiple in-context exemplars with well-designed rationales to elicit Large Language Models (LLMs) to generate intermediate reasoning steps. However, the generated rationales often come with mistakes, making unfactual and unfaithful reasoning chains. To mitigate this brittleness, we propose a novel Chain-of-Knowledge (CoK) prompting, where we aim at eliciting LLMs to generate explicit pieces of knowledge evidence in the form of structure triple. This is inspired by our human behaviors, i.e., we can draw a mind map or knowledge map as the reasoning evidence in the brain before answering a complex question. Benefiting from CoK, we additionally introduce a F^2-Verification method to estimate the reliability of the reasoning chains in terms of factuality and faithfulness. For the unreliable response, the wrong evidence can be indicated to prompt the LLM to rethink. Extensive experiments demonstrate that our method can further improve the performance of commonsense, factual, symbolic, and arithmetic reasoning tasks.
6/4/2024
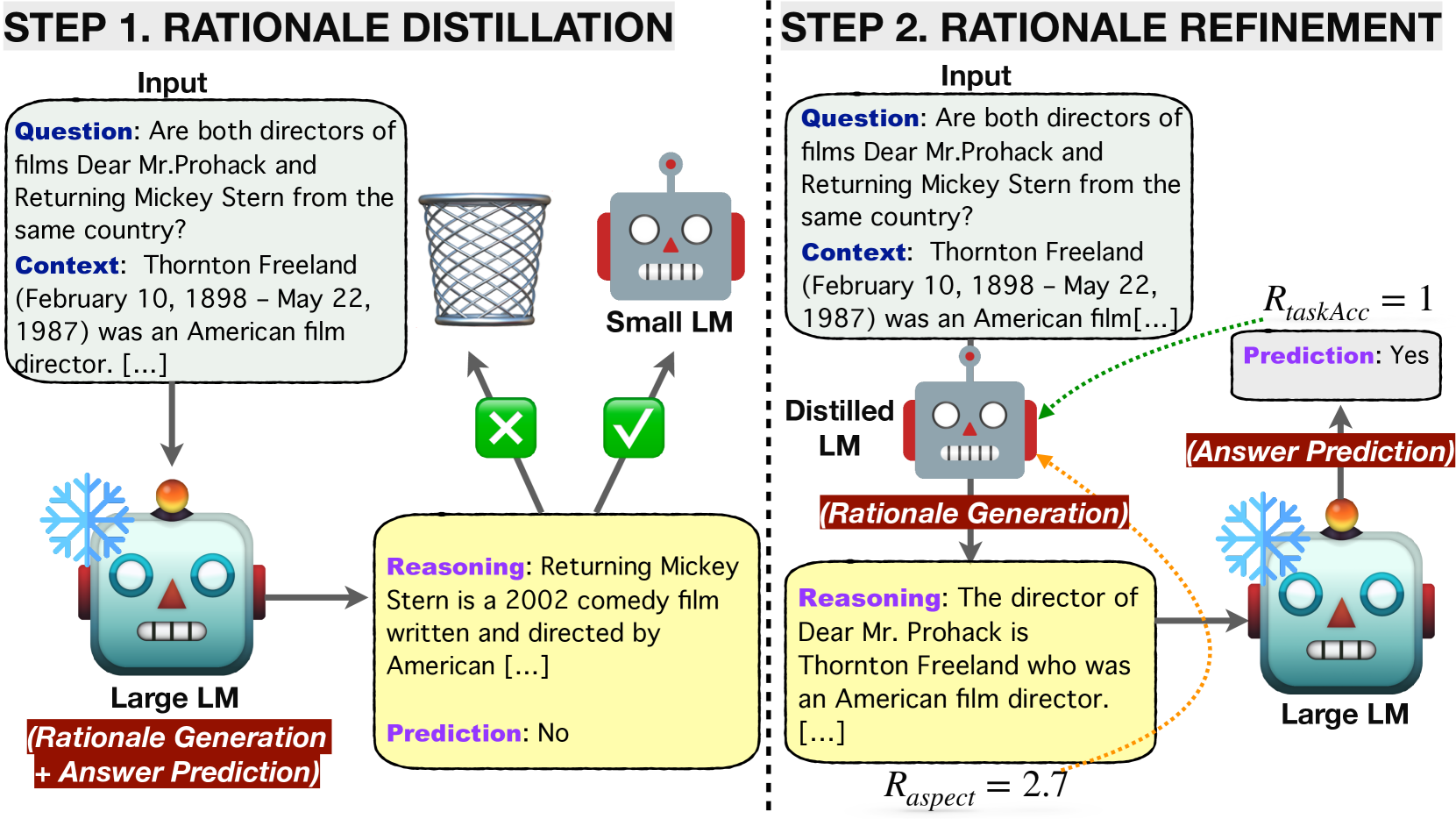
Can Small Language Models Help Large Language Models Reason Better?: LM-Guided Chain-of-Thought
Jooyoung Lee, Fan Yang, Thanh Tran, Qian Hu, Emre Barut, Kai-Wei Chang, Chengwei Su
0
0
We introduce a novel framework, LM-Guided CoT, that leverages a lightweight (i.e., 10B) LM in reasoning tasks. Specifically, the lightweight LM first generates a rationale for each input instance. The Frozen large LM is then prompted to predict a task output based on the rationale generated by the lightweight LM. Our approach is resource-efficient in the sense that it only requires training the lightweight LM. We optimize the model through 1) knowledge distillation and 2) reinforcement learning from rationale-oriented and task-oriented reward signals. We assess our method with multi-hop extractive question answering (QA) benchmarks, HotpotQA, and 2WikiMultiHopQA. Experimental results show that our approach outperforms all baselines regarding answer prediction accuracy. We also find that reinforcement learning helps the model to produce higher-quality rationales with improved QA performance.
4/5/2024

General Purpose Verification for Chain of Thought Prompting
Robert Vacareanu, Anurag Pratik, Evangelia Spiliopoulou, Zheng Qi, Giovanni Paolini, Neha Anna John, Jie Ma, Yassine Benajiba, Miguel Ballesteros
0
0
Many of the recent capabilities demonstrated by Large Language Models (LLMs) arise primarily from their ability to exploit contextual information. In this paper, we explore ways to improve reasoning capabilities of LLMs through (1) exploration of different chains of thought and (2) validation of the individual steps of the reasoning process. We propose three general principles that a model should adhere to while reasoning: (i) Relevance, (ii) Mathematical Accuracy, and (iii) Logical Consistency. We apply these constraints to the reasoning steps generated by the LLM to improve the accuracy of the final generation. The constraints are applied in the form of verifiers: the model itself is asked to verify if the generated steps satisfy each constraint. To further steer the generations towards high-quality solutions, we use the perplexity of the reasoning steps as an additional verifier. We evaluate our method on 4 distinct types of reasoning tasks, spanning a total of 9 different datasets. Experiments show that our method is always better than vanilla generation, and, in 6 out of the 9 datasets, it is better than best-of N sampling which samples N reasoning chains and picks the lowest perplexity generation.
5/2/2024