The Implicit Bias of Adam on Separable Data
2406.10650
0
0

Abstract
Adam has become one of the most favored optimizers in deep learning problems. Despite its success in practice, numerous mysteries persist regarding its theoretical understanding. In this paper, we study the implicit bias of Adam in linear logistic regression. Specifically, we show that when the training data are linearly separable, Adam converges towards a linear classifier that achieves the maximum $ell_infty$-margin. Notably, for a general class of diminishing learning rates, this convergence occurs within polynomial time. Our result shed light on the difference between Adam and (stochastic) gradient descent from a theoretical perspective.
Create account to get full access
Overview
- This paper examines the implicit bias of the Adam optimization algorithm on separable data, which is a common setting in machine learning.
- The authors provide theoretical insights into the dynamics and behavior of Adam, a popular optimization method used to train deep neural networks.
- They show that Adam can exhibit a bias towards sparser solutions compared to other optimization methods like Stochastic Gradient Descent (SGD) or Adagrad.
- This work contributes to the growing body of research on the implicit bias of optimization algorithms and their impact on model generalization and robustness.
Plain English Explanation
When training machine learning models, the choice of optimization algorithm can have a significant impact on the final solution. The Adam optimization algorithm is a popular choice due to its ability to adaptively adjust the learning rate for each parameter. However, this adaptive behavior can also introduce an "implicit bias" towards certain types of solutions.
In this paper, the researchers investigate the implicit bias of Adam on "separable data," which is a common setup in machine learning problems. They find that Adam can exhibit a bias towards sparser or more compact solutions compared to other optimization methods like Stochastic Gradient Descent (SGD) or Adagrad.
This bias towards sparser solutions can have implications for the generalization and robustness of the trained models. The implicit bias of optimization algorithms is an active area of research, as it helps us understand the complex dynamics and behaviors of these algorithms in different settings.
By understanding the implicit bias of Adam, researchers and practitioners can make more informed choices about which optimization algorithm to use for their specific machine learning tasks, potentially leading to models with better generalization and robustness.
Technical Explanation
The paper starts by introducing the problem setting of separable data, where the goal is to find a linear classifier that correctly separates the data points into two classes. The authors then analyze the behavior of the Adam optimization algorithm in this setting.
They show that Adam can exhibit a bias towards sparser solutions, meaning that the final model parameters tend to have fewer non-zero elements compared to other optimization methods like SGD or Adagrad. This bias is due to the adaptive nature of Adam, which adjusts the learning rate for each parameter based on the historical gradients.
The authors provide a detailed theoretical analysis of the dynamics of Adam, deriving explicit expressions for the expected update direction and the expected squared parameter values. They then use these insights to characterize the implicit bias of Adam and how it differs from other optimization algorithms.
Through numerical experiments, the researchers demonstrate that the implicit bias of Adam can lead to faster margin maximization rates on separable data compared to SGD. However, this bias can also have implications for adversarial robustness and generalization, which are discussed in the paper.
Critical Analysis
The paper provides a thorough theoretical analysis of the implicit bias of the Adam optimization algorithm, which is a valuable contribution to the understanding of this widely used method. The authors acknowledge that their analysis is limited to the separable data setting, and it would be interesting to see if similar biases exist in other problem settings.
One potential limitation of the work is that the theoretical analysis relies on several simplifying assumptions, such as the data being drawn from a Gaussian distribution. It would be worth exploring the extent to which the observed biases hold in more realistic and complex data distributions.
Additionally, while the paper discusses the implications of Adam's bias for generalization and robustness, it would be helpful to see a more in-depth analysis of the practical consequences of this bias. For example, how do the observed biases translate to real-world machine learning tasks, and what strategies can be employed to mitigate any undesirable effects?
Overall, this paper provides valuable insights into the implicit bias of the Adam optimization algorithm and serves as an important contribution to the growing body of research on the behavior of optimization methods in machine learning.
Conclusion
This paper offers a detailed theoretical analysis of the implicit bias of the Adam optimization algorithm on separable data, a common setting in machine learning. The authors demonstrate that Adam can exhibit a bias towards sparser solutions compared to other optimization methods like SGD or Adagrad.
This bias can have implications for the generalization and robustness of the trained models, as the choice of optimization algorithm can significantly impact the properties of the final solution. By understanding these biases, researchers and practitioners can make more informed decisions about which optimization method to use for their specific machine learning tasks.
The insights provided in this paper contribute to the broader understanding of the implicit biases of optimization algorithms and their impact on model performance. As the field of machine learning continues to evolve, continued research in this area will be crucial for developing more reliable and robust AI systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🔮
On the Implicit Bias of Adam
Matias D. Cattaneo, Jason M. Klusowski, Boris Shigida
0
0
In previous literature, backward error analysis was used to find ordinary differential equations (ODEs) approximating the gradient descent trajectory. It was found that finite step sizes implicitly regularize solutions because terms appearing in the ODEs penalize the two-norm of the loss gradients. We prove that the existence of similar implicit regularization in RMSProp and Adam depends on their hyperparameters and the training stage, but with a different norm involved: the corresponding ODE terms either penalize the (perturbed) one-norm of the loss gradients or, conversely, impede its reduction (the latter case being typical). We also conduct numerical experiments and discuss how the proven facts can influence generalization.
6/18/2024
🛠️
Faster Margin Maximization Rates for Generic and Adversarially Robust Optimization Methods
Guanghui Wang, Zihao Hu, Claudio Gentile, Vidya Muthukumar, Jacob Abernethy
0
0
First-order optimization methods tend to inherently favor certain solutions over others when minimizing an underdetermined training objective that has multiple global optima. This phenomenon, known as implicit bias, plays a critical role in understanding the generalization capabilities of optimization algorithms. Recent research has revealed that in separable binary classification tasks gradient-descent-based methods exhibit an implicit bias for the $ell_2$-maximal margin classifier. Similarly, generic optimization methods, such as mirror descent and steepest descent, have been shown to converge to maximal margin classifiers defined by alternative geometries. While gradient-descent-based algorithms provably achieve fast implicit bias rates, corresponding rates in the literature for generic optimization methods are relatively slow. To address this limitation, we present a series of state-of-the-art implicit bias rates for mirror descent and steepest descent algorithms. Our primary technique involves transforming a generic optimization algorithm into an online optimization dynamic that solves a regularized bilinear game, providing a unified framework for analyzing the implicit bias of various optimization methods. Our accelerated rates are derived by leveraging the regret bounds of online learning algorithms within this game framework. We then show the flexibility of this framework by analyzing the implicit bias in adversarial training, and again obtain significantly improved convergence rates.
4/9/2024
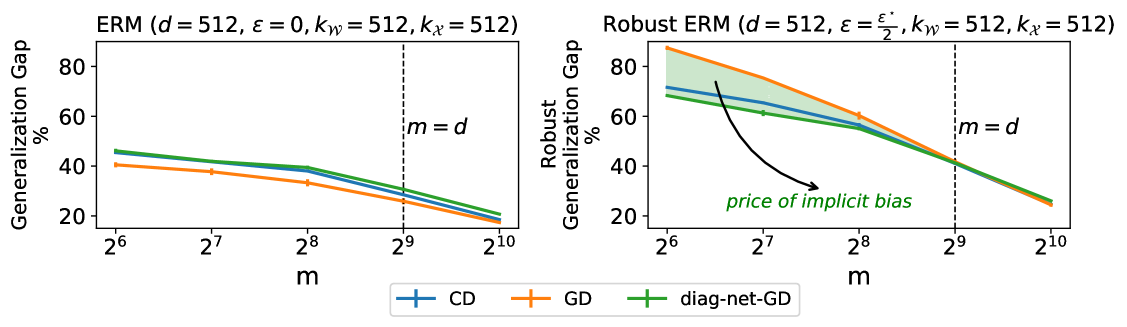
The Price of Implicit Bias in Adversarially Robust Generalization
Nikolaos Tsilivis, Natalie Frank, Nathan Srebro, Julia Kempe
0
0
We study the implicit bias of optimization in robust empirical risk minimization (robust ERM) and its connection with robust generalization. In classification settings under adversarial perturbations with linear models, we study what type of regularization should ideally be applied for a given perturbation set to improve (robust) generalization. We then show that the implicit bias of optimization in robust ERM can significantly affect the robustness of the model and identify two ways this can happen; either through the optimization algorithm or the architecture. We verify our predictions in simulations with synthetic data and experimentally study the importance of implicit bias in robust ERM with deep neural networks.
6/10/2024
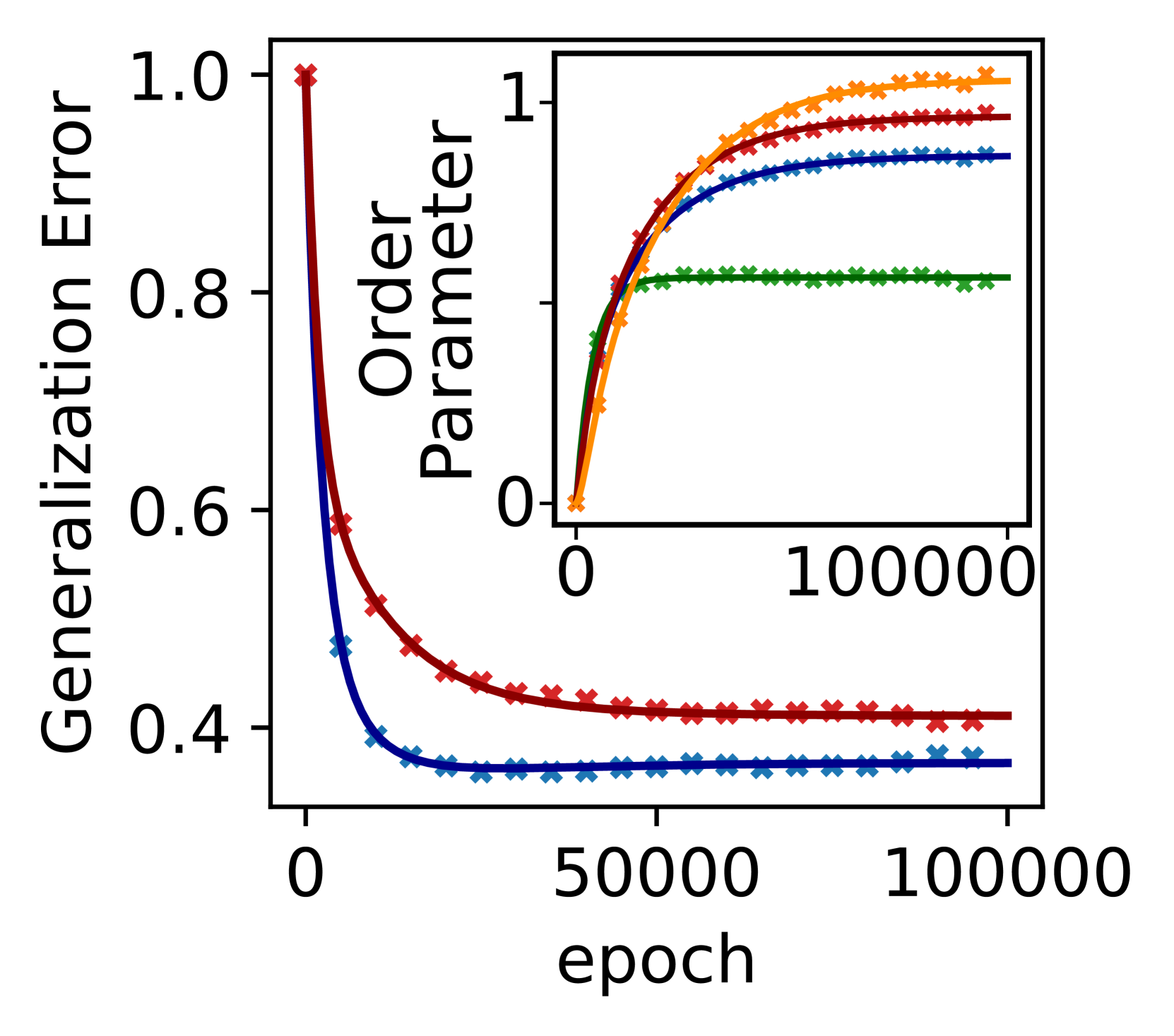
Bias in Motion: Theoretical Insights into the Dynamics of Bias in SGD Training
Anchit Jain, Rozhin Nobahari, Aristide Baratin, Stefano Sarao Mannelli
0
0
Machine learning systems often acquire biases by leveraging undesired features in the data, impacting accuracy variably across different sub-populations. Current understanding of bias formation mostly focuses on the initial and final stages of learning, leaving a gap in knowledge regarding the transient dynamics. To address this gap, this paper explores the evolution of bias in a teacher-student setup modeling different data sub-populations with a Gaussian-mixture model. We provide an analytical description of the stochastic gradient descent dynamics of a linear classifier in this setting, which we prove to be exact in high dimension. Notably, our analysis reveals how different properties of sub-populations influence bias at different timescales, showing a shifting preference of the classifier during training. Applying our findings to fairness and robustness, we delineate how and when heterogeneous data and spurious features can generate and amplify bias. We empirically validate our results in more complex scenarios by training deeper networks on synthetic and real datasets, including CIFAR10, MNIST, and CelebA.
5/29/2024