FreeVA: Offline MLLM as Training-Free Video Assistant

0
🧪
Sign in to get full access
Overview
- This paper presents an empirical study on the latest advancements in Multimodal Large Language Models (MLLMs) for video understanding, focusing on a technique called FreeVA.
- FreeVA aims to extend existing image-based MLLMs to the video domain without additional training, providing an essential baseline for video question-answering tasks.
- The study makes several surprising findings, including that FreeVA outperforms state-of-the-art methods that involve video instruction tuning, and that common video MLLM training approaches may not actually improve performance over using the image-based model alone.
- The paper also highlights issues with the current evaluation metrics used in video MLLM research, which can be influenced by changes in the GPT API over time.
Plain English Explanation
The researchers in this paper wanted to investigate the latest progress in using large language models that can handle both text and visual information (called Multimodal Large Language Models or MLLMs) to understand and answer questions about videos. They developed a new technique called FreeVA, which can use existing MLLM models trained on images to work with videos, without needing any additional training.
The key findings from their study are:
- FreeVA, which doesn't require any extra training, is able to answer questions about videos better than state-of-the-art methods that do involve training the models on video-specific data.
- The common approach of taking an image-based MLLM and then further training it on video-related data doesn't actually improve performance compared to just using the original image-based model.
- The way researchers have been evaluating the performance of video MLLMs is flawed, as the metrics can change over time due to updates to the underlying language models. This makes it hard to fairly compare different methods.
Overall, this work provides a simple but effective baseline for using existing image-based MLLMs, like LLaVA, to understand videos, without needing extensive additional training. It also raises important questions about the current state of video MLLM research and how it should be evaluated going forward.
Technical Explanation
The paper presents an empirical study on Multimodal Large Language Models (MLLMs) for video understanding, focusing on a technique called FreeVA. FreeVA aims to extend existing image-based MLLMs, such as LLaVA, to the video domain in a training-free manner, providing an essential baseline for video question-answering tasks.
The key findings from the study are:
- FreeVA, without any additional training, is able to outperform state-of-the-art video MLLM methods that involve video instruction tuning on various video question-answering benchmarks, including MSVD-QA, ActivityNet-QA, and MSRVTT-QA.
- The common approach of initializing video-based MLLMs with an image-based MLLM (e.g., LLaVA) and then fine-tuning using video instruction tuning (e.g., using the VideoInstruct-100K dataset) does not actually lead to better performance compared to not training at all.
- The widely used evaluation metrics in existing video MLLM works are significantly influenced by changes in the GPT API version over time, which can affect the fairness and uniformity of comparisons between different methods.
The paper argues that this work can serve as a plug-and-play, simple yet effective baseline for directly evaluating existing MLLMs in the video domain, while also helping to standardize the field of video conversational models. The authors also encourage researchers to reconsider whether current video MLLM methods have truly acquired knowledge beyond what can be obtained from image-based MLLMs alone.
Critical Analysis
The paper provides a comprehensive and insightful analysis of the current state of video MLLM research, highlighting several important caveats and limitations. One key concern raised is the potential issue with the evaluation metrics used in existing works, which can be influenced by changes in the underlying GPT API over time. This raises questions about the fairness and consistency of comparisons between different methods, potentially leading to flawed conclusions and analyses in the field.
Additionally, the finding that using video-specific training data (e.g., VideoInstruct-100K) does not actually improve performance compared to simply using the image-based MLLM is quite surprising and challenges the common assumption that further training is necessary to extend MLLMs to the video domain. This suggests that current video MLLM methods may not have truly acquired knowledge beyond what can be obtained from image-based models, a point that the authors rightly encourage researchers to reconsider.
While the paper provides a compelling baseline with FreeVA, it would be valuable to see further investigation into the generalizability and limitations of this approach, as well as more detailed analysis of the differences between image-based and video-based MLLM performance. Additionally, exploring alternative evaluation metrics or strategies that are less susceptible to API changes could help strengthen the field's ability to make robust and reliable assessments of video MLLM progress.
Conclusion
This paper presents an important and timely study on the state of Multimodal Large Language Models (MLLMs) for video understanding. The key findings, including the surprising performance of the training-free FreeVA approach and the issues with current evaluation metrics, challenge the assumptions and practices in the field of video MLLM research.
By providing a simple yet effective baseline, the authors encourage the direct evaluation of existing MLLMs in the video domain, potentially leading to more standardized and rigorous assessments of progress. The study also raises critical questions about the true capabilities of current video MLLM methods, urging researchers to reconsider whether these models have acquired knowledge beyond what can be obtained from image-based MLLMs alone.
Overall, this work serves as an essential contribution to the rapidly advancing field of multimodal language models, highlighting the need for more careful evaluation and a deeper understanding of the underlying abilities and limitations of these powerful AI systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🧪
0
FreeVA: Offline MLLM as Training-Free Video Assistant
Wenhao Wu
This paper undertakes an empirical study to revisit the latest advancements in Multimodal Large Language Models (MLLMs): Video Assistant. This study, namely FreeVA, aims to extend existing image-based MLLM to the video domain in a training-free manner. The study provides an essential, yet must-know baseline, and reveals several surprising findings: 1) FreeVA, leveraging only offline image-based MLLM without additional training, excels in zero-shot video question-answering (e.g., MSVD-QA, ActivityNet-QA, and MSRVTT-QA), even surpassing state-of-the-art methods that involve video instruction tuning. 2) While mainstream video-based MLLMs typically initialize with an image-based MLLM (e.g., LLaVA) and then fine-tune using video instruction tuning, the study indicates that utilizing the widely adopted VideoInstruct-100K for video instruction tuning doesn't actually lead to better performance compared to not training at all. 3) The commonly used evaluation metrics in existing works are significantly influenced by changes in the GPT API version over time. If ignored, this could affect the fairness and uniformity of comparisons between different methods and impact the analysis and judgment of researchers in the field. The advancement of MLLMs is currently thriving, drawing numerous researchers into the field. We aim for this work to serve as a plug-and-play, simple yet effective baseline, encouraging the direct evaluation of existing MLLMs in video domain while also standardizing the field of video conversational models to a certain extent. Also, we encourage researchers to reconsider: Have current video MLLM methods truly acquired knowledge beyond image MLLM? Code is available at https://github.com/whwu95/FreeVA
Read more6/11/2024

0
VideoLLM-online: Online Video Large Language Model for Streaming Video
Joya Chen, Zhaoyang Lv, Shiwei Wu, Kevin Qinghong Lin, Chenan Song, Difei Gao, Jia-Wei Liu, Ziteng Gao, Dongxing Mao, Mike Zheng Shou
Recent Large Language Models have been enhanced with vision capabilities, enabling them to comprehend images, videos, and interleaved vision-language content. However, the learning methods of these large multimodal models typically treat videos as predetermined clips, making them less effective and efficient at handling streaming video inputs. In this paper, we propose a novel Learning-In-Video-Stream (LIVE) framework, which enables temporally aligned, long-context, and real-time conversation within a continuous video stream. Our LIVE framework comprises comprehensive approaches to achieve video streaming dialogue, encompassing: (1) a training objective designed to perform language modeling for continuous streaming inputs, (2) a data generation scheme that converts offline temporal annotations into a streaming dialogue format, and (3) an optimized inference pipeline to speed up the model responses in real-world video streams. With our LIVE framework, we built VideoLLM-online model upon Llama-2/Llama-3 and demonstrate its significant advantages in processing streaming videos. For instance, on average, our model can support streaming dialogue in a 5-minute video clip at over 10 FPS on an A100 GPU. Moreover, it also showcases state-of-the-art performance on public offline video benchmarks, such as recognition, captioning, and forecasting. The code, model, data, and demo have been made available at https://showlab.github.io/videollm-online.
Read more6/18/2024
0
Fewer Tokens and Fewer Videos: Extending Video Understanding Abilities in Large Vision-Language Models
Shimin Chen, Yitian Yuan, Shaoxiang Chen, Zequn Jie, Lin Ma
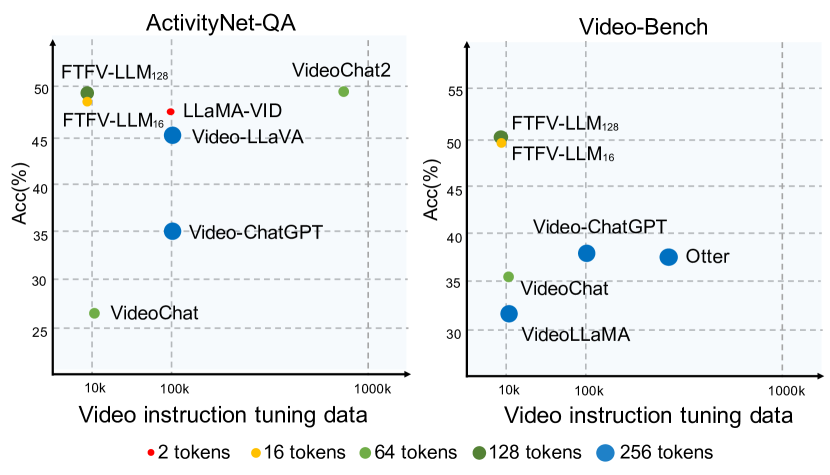
Amidst the advancements in image-based Large Vision-Language Models (image-LVLM), the transition to video-based models (video-LVLM) is hindered by the limited availability of quality video data. This paper addresses the challenge by leveraging the visual commonalities between images and videos to efficiently evolve image-LVLMs into video-LVLMs. We present a cost-effective video-LVLM that enhances model architecture, introduces innovative training strategies, and identifies the most effective types of video instruction data. Our innovative weighted token sampler significantly compresses the visual token numbers of each video frame, effectively cutting computational expenses. We also find that judiciously using just 10% of the video data, compared to prior video-LVLMs, yields impressive results during various training phases. Moreover, we delve into the influence of video instruction data in limited-resource settings, highlighting the significance of incorporating video training data that emphasizes temporal understanding to enhance model performance. The resulting Fewer Tokens and Fewer Videos LVLM (FTFV-LVLM) exhibits exceptional performance across video and image benchmarks, validating our model's design and training approaches.
Read more6/13/2024
0
Interpolating Video-LLMs: Toward Longer-sequence LMMs in a Training-free Manner
Yuzhang Shang, Bingxin Xu, Weitai Kang, Mu Cai, Yuheng Li, Zehao Wen, Zhen Dong, Kurt Keutzer, Yong Jae Lee, Yan Yan
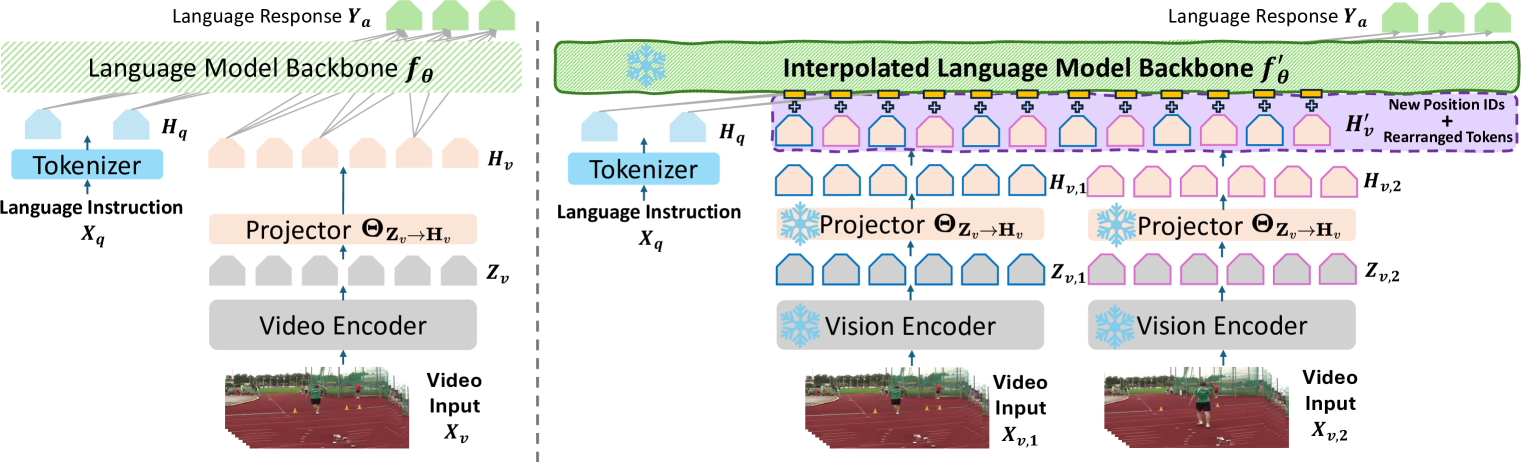
Advancements in Large Language Models (LLMs) inspire various strategies for integrating video modalities. A key approach is Video-LLMs, which incorporate an optimizable interface linking sophisticated video encoders to LLMs. However, due to computation and data limitations, these Video-LLMs are typically pre-trained to process only short videos, limiting their broader application for understanding longer video content. Additionally, fine-tuning Video-LLMs to handle longer videos is cost-prohibitive. Consequently, it becomes essential to explore the interpolation of Video-LLMs under a completely training-free setting. In this paper, we first identify the primary challenges in interpolating Video-LLMs: (1) the video encoder and modality alignment projector are fixed, preventing the integration of additional frames into Video-LLMs, and (2) the LLM backbone is limited in its content length capabilities, which complicates the processing of an increased number of video tokens. To address these challenges, we propose a specific INTerPolation method for Video-LLMs (INTP-Video-LLMs). We introduce an alternative video token rearrangement technique that circumvents limitations imposed by the fixed video encoder and alignment projector. Furthermore, we introduce a training-free LLM context window extension method to enable Video-LLMs to understand a correspondingly increased number of visual tokens.
Read more9/20/2024