Improving Calibration by Relating Focal Loss, Temperature Scaling, and Properness

0

Sign in to get full access
Overview
- The paper explores the relationship between focal loss, temperature scaling, and properness to improve model calibration.
- It provides theoretical and empirical insights into how these concepts are connected and how they can be used to enhance the reliability of model predictions.
- The research aims to help develop more trustworthy and well-calibrated machine learning models.
Plain English Explanation
The paper looks at three important concepts in machine learning: [object Object], [object Object], and [object Object]. These concepts are all related to how well a machine learning model can estimate the probability of its predictions being correct.
Focal loss is a type of loss function that helps models focus more on harder-to-classify examples during training. Temperature scaling is a way to adjust the model's confidence scores after training to make them better aligned with the true probability of correctness. And properness is a property of a probability distribution that ensures the model is incentivized to provide accurate probability estimates.
The paper shows how these three concepts are connected and how understanding these connections can help improve the overall calibration of a machine learning model. Calibration refers to how well a model's confidence scores match the true probability of correctness. Well-calibrated models are important for building trustworthy and reliable AI systems.
Technical Explanation
The paper starts by relating focal loss to temperature scaling and showing that focal loss can be viewed as a particular form of temperature scaling. It then explores the connection between temperature scaling and properness, demonstrating that temperature scaling can be used to transform an improper model (one that does not provide accurate probability estimates) into a proper one.
Through theoretical analysis and empirical experiments, the paper establishes several key insights:
- Focal loss can be interpreted as a temperature scaling approach that adaptively adjusts the temperature for each example based on the model's confidence.
- Temperature scaling can be used to transform an improperly trained model into a proper one, improving its calibration.
- There is a trade-off between the model's discriminative performance and its calibration, and temperature scaling can be used to find the right balance.
The paper also discusses potential limitations and future research directions, such as the need to better understand the relationship between model architecture, training objectives, and calibration.
Critical Analysis
The paper provides valuable insights into the connections between focal loss, temperature scaling, and properness, which can help researchers and practitioners develop more reliable and trustworthy machine learning models. However, it's important to note that the paper focuses on the theoretical and empirical analysis of these concepts, and doesn't necessarily address all the practical challenges involved in applying these techniques in real-world scenarios.
For example, the paper doesn't delve into the computational complexity or scalability of the proposed approaches, which could be important considerations when working with large-scale models or datasets. Additionally, the paper doesn't explore the potential for these techniques to be combined with other calibration methods or to be adapted for specific domains or applications.
Further research may be needed to understand the broader implications of these findings and to explore how they can be effectively integrated into practical machine learning workflows.
Conclusion
This paper offers a deep dive into the theoretical and empirical connections between focal loss, temperature scaling, and properness, and how these concepts can be leveraged to improve the calibration of machine learning models. By establishing these relationships, the research provides a valuable framework for developing more trustworthy and reliable AI systems, which is of growing importance as machine learning models become increasingly pervasive in our lives.
The insights from this paper could have far-reaching implications for a wide range of applications, from medical diagnosis to autonomous decision-making, where accurate and well-calibrated predictions are crucial. As the field of machine learning continues to evolve, this work serves as an important contribution to our understanding of model calibration and the tools available to enhance the reliability and trustworthiness of AI systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Improving Calibration by Relating Focal Loss, Temperature Scaling, and Properness
Viacheslav Komisarenko, Meelis Kull
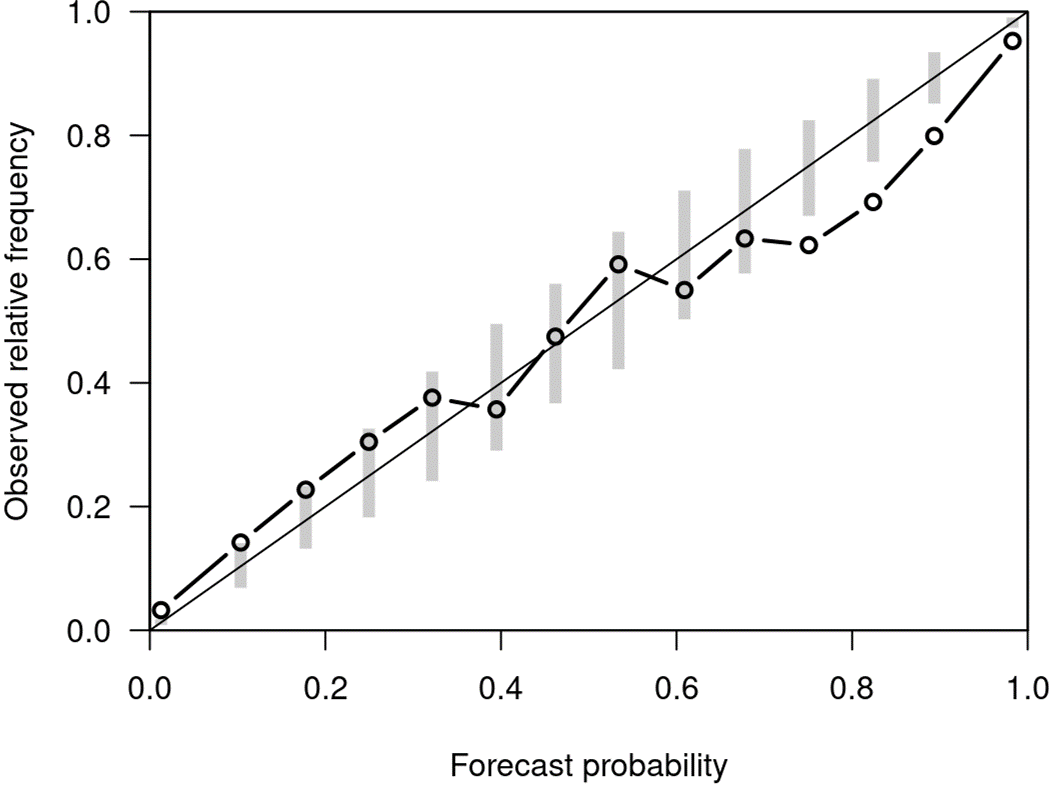
Proper losses such as cross-entropy incentivize classifiers to produce class probabilities that are well-calibrated on the training data. Due to the generalization gap, these classifiers tend to become overconfident on the test data, mandating calibration methods such as temperature scaling. The focal loss is not proper, but training with it has been shown to often result in classifiers that are better calibrated on test data. Our first contribution is a simple explanation about why focal loss training often leads to better calibration than cross-entropy training. For this, we prove that focal loss can be decomposed into a confidence-raising transformation and a proper loss. This is why focal loss pushes the model to provide under-confident predictions on the training data, resulting in being better calibrated on the test data, due to the generalization gap. Secondly, we reveal a strong connection between temperature scaling and focal loss through its confidence-raising transformation, which we refer to as the focal calibration map. Thirdly, we propose focal temperature scaling - a new post-hoc calibration method combining focal calibration and temperature scaling. Our experiments on three image classification datasets demonstrate that focal temperature scaling outperforms standard temperature scaling.
Read more8/22/2024
📈
0
Geometric Insights into Focal Loss: Reducing Curvature for Enhanced Model Calibration
Masanari Kimura, Hiroki Naganuma
The key factor in implementing machine learning algorithms in decision-making situations is not only the accuracy of the model but also its confidence level. The confidence level of a model in a classification problem is often given by the output vector of a softmax function for convenience. However, these values are known to deviate significantly from the actual expected model confidence. This problem is called model calibration and has been studied extensively. One of the simplest techniques to tackle this task is focal loss, a generalization of cross-entropy by introducing one positive parameter. Although many related studies exist because of the simplicity of the idea and its formalization, the theoretical analysis of its behavior is still insufficient. In this study, our objective is to understand the behavior of focal loss by reinterpreting this function geometrically. Our analysis suggests that focal loss reduces the curvature of the loss surface in training the model. This indicates that curvature may be one of the essential factors in achieving model calibration. We design numerical experiments to support this conjecture to reveal the behavior of focal loss and the relationship between calibration performance and curvature.
Read more5/2/2024
0
Calibrating Where It Matters: Constrained Temperature Scaling
Stephen McKenna, Jacob Carse
We consider calibration of convolutional classifiers for diagnostic decision making. Clinical decision makers can use calibrated classifiers to minimise expected costs given their own cost function. Such functions are usually unknown at training time. If minimising expected costs is the primary aim, algorithms should focus on tuning calibration in regions of probability simplex likely to effect decisions. We give an example, modifying temperature scaling calibration, and demonstrate improved calibration where it matters using convnets trained to classify dermoscopy images.
Read more6/18/2024
0
Optimizing Calibration by Gaining Aware of Prediction Correctness
Yuchi Liu, Lei Wang, Yuli Zou, James Zou, Liang Zheng
Model calibration aims to align confidence with prediction correctness. The Cross-Entropy (CE) loss is widely used for calibrator training, which enforces the model to increase confidence on the ground truth class. However, we find the CE loss has intrinsic limitations. For example, for a narrow misclassification, a calibrator trained by the CE loss often produces high confidence on the wrongly predicted class (e.g., a test sample is wrongly classified and its softmax score on the ground truth class is around 0.4), which is undesirable. In this paper, we propose a new post-hoc calibration objective derived from the aim of calibration. Intuitively, the proposed objective function asks that the calibrator decrease model confidence on wrongly predicted samples and increase confidence on correctly predicted samples. Because a sample itself has insufficient ability to indicate correctness, we use its transformed versions (e.g., rotated, greyscaled and color-jittered) during calibrator training. Trained on an in-distribution validation set and tested with isolated, individual test samples, our method achieves competitive calibration performance on both in-distribution and out-of-distribution test sets compared with the state of the art. Further, our analysis points out the difference between our method and commonly used objectives such as CE loss and mean square error loss, where the latters sometimes deviates from the calibration aim.
Read more4/26/2024