Calibrating Where It Matters: Constrained Temperature Scaling

0
Sign in to get full access
Overview
- This paper proposes a novel method for calibrating machine learning models, called Constrained Temperature Scaling (CTS), which aims to improve the reliability of model predictions in critical applications like medical decision-making.
- The authors demonstrate that CTS outperforms standard temperature scaling on various benchmarks, particularly in scenarios where accurate calibration is crucial in the high-risk regions of the prediction space.
- The paper also provides insights into the factors that influence model calibration, offering guidance for practitioners on optimizing model performance in safety-critical domains.
Plain English Explanation
Calibrating Where It Matters: Constrained Temperature Scaling addresses a critical challenge in machine learning: ensuring that model predictions are well-calibrated, meaning that the model's confidence in its predictions reflects the true likelihood of the predicted outcome.
This is especially important in high-stakes applications, like medical diagnosis, where overconfident or unreliable predictions can have serious consequences. The authors propose a new technique called Constrained Temperature Scaling (CTS) that aims to improve model calibration, particularly in the most critical regions of the prediction space.
The key idea behind CTS is to focus the calibration process on the areas of the prediction space that are most important for the given application. For example, in medical diagnosis, correctly identifying high-risk cases may be more crucial than accurately predicting low-risk cases. CTS allows the model to be fine-tuned to prioritize calibration in these high-risk regions, ensuring that the model's confidence levels are well-aligned with the true likelihood of the predicted outcomes.
The paper demonstrates that CTS outperforms standard temperature scaling, a widely used calibration technique, on several benchmarks. This suggests that CTS could be a valuable tool for practitioners working on safety-critical applications, helping to build more trustworthy and reliable machine learning models.
Technical Explanation
Calibrating Where It Matters: Constrained Temperature Scaling introduces a novel approach to post-hoc model calibration called Constrained Temperature Scaling (CTS). The key innovation of CTS is its ability to focus the calibration process on the most critical regions of the prediction space, rather than treating all predictions equally.
The authors first provide an overview of the importance of model calibration, particularly in safety-critical domains like medical decision-making. They then describe the CTS method, which builds on the well-known temperature scaling technique. CTS adds a constraint that prioritizes calibration accuracy in the high-risk regions of the prediction space, ensuring that the model's confidence levels are well-aligned with the true likelihood of the predicted outcomes in these critical areas.
To evaluate CTS, the authors conduct experiments on several benchmark datasets, including medical diagnosis and natural language understanding tasks. They compare the performance of CTS to standard temperature scaling, as well as other calibration methods like Isotonic Regression and Platt Scaling.
The results demonstrate that CTS outperforms these alternative techniques, particularly in scenarios where accurate calibration is crucial in the high-risk regions of the prediction space. The authors also provide insights into the factors that influence model calibration, such as dataset size, model capacity, and the distribution of ground truth labels.
The paper concludes by discussing the potential implications of their work for practitioners working on safety-critical applications, and suggests future research directions, such as exploring the use of CTS in online learning settings or investigating the interplay between model architecture and calibration performance.
Critical Analysis
The Calibrating Where It Matters: Constrained Temperature Scaling paper presents a novel and promising approach to model calibration, with a focus on critical high-risk regions of the prediction space. The authors' emphasis on improving calibration accuracy in these crucial areas is well-justified, as overconfident or unreliable predictions in safety-critical domains can have severe consequences.
One potential limitation of the CTS method is its reliance on a predefined notion of "high-risk" regions, which may not always be straightforward to determine. In some applications, the definition of risk may be more nuanced or context-dependent. The authors acknowledge this challenge and suggest that future work could explore methods for automatically identifying the most critical regions of the prediction space.
Additionally, the paper's experiments are conducted on a relatively limited set of benchmark datasets, primarily in the medical and natural language understanding domains. It would be valuable to see the performance of CTS evaluated on a wider range of applications, including other safety-critical domains, to better understand its generalizability and robustness.
The authors also note that the CTS approach may incur additional computational overhead compared to standard temperature scaling, which could be a consideration for practitioners with strict performance requirements. Exploring ways to optimize the efficiency of CTS or develop more computationally-efficient variants could be an area for future research.
Overall, the Calibrating Where It Matters: Constrained Temperature Scaling paper presents a compelling and well-executed approach to improving model calibration in critical applications. The authors' focus on the high-risk regions of the prediction space is a valuable contribution, and the CTS method shows promising results that could have significant implications for safety-critical machine learning systems.
Conclusion
Calibrating Where It Matters: Constrained Temperature Scaling addresses a crucial challenge in machine learning: ensuring that model predictions are well-calibrated, especially in high-stakes applications like medical diagnosis. The authors propose a novel technique called Constrained Temperature Scaling (CTS) that prioritizes calibration accuracy in the most critical regions of the prediction space.
The paper's empirical results demonstrate that CTS outperforms standard calibration methods, particularly in scenarios where accurate calibration is vital. This suggests that CTS could be a valuable tool for practitioners working on safety-critical applications, helping to build more trustworthy and reliable machine learning models.
While the paper presents a promising approach, it also highlights the need for further research to address potential limitations, such as the challenge of automatically identifying high-risk regions and optimizing the computational efficiency of the CTS method. Nonetheless, the Calibrating Where It Matters: Constrained Temperature Scaling paper represents an important contribution to the field of model calibration, with the potential to have a significant impact on the development of safe and reliable AI systems for critical real-world applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Calibrating Where It Matters: Constrained Temperature Scaling
Stephen McKenna, Jacob Carse
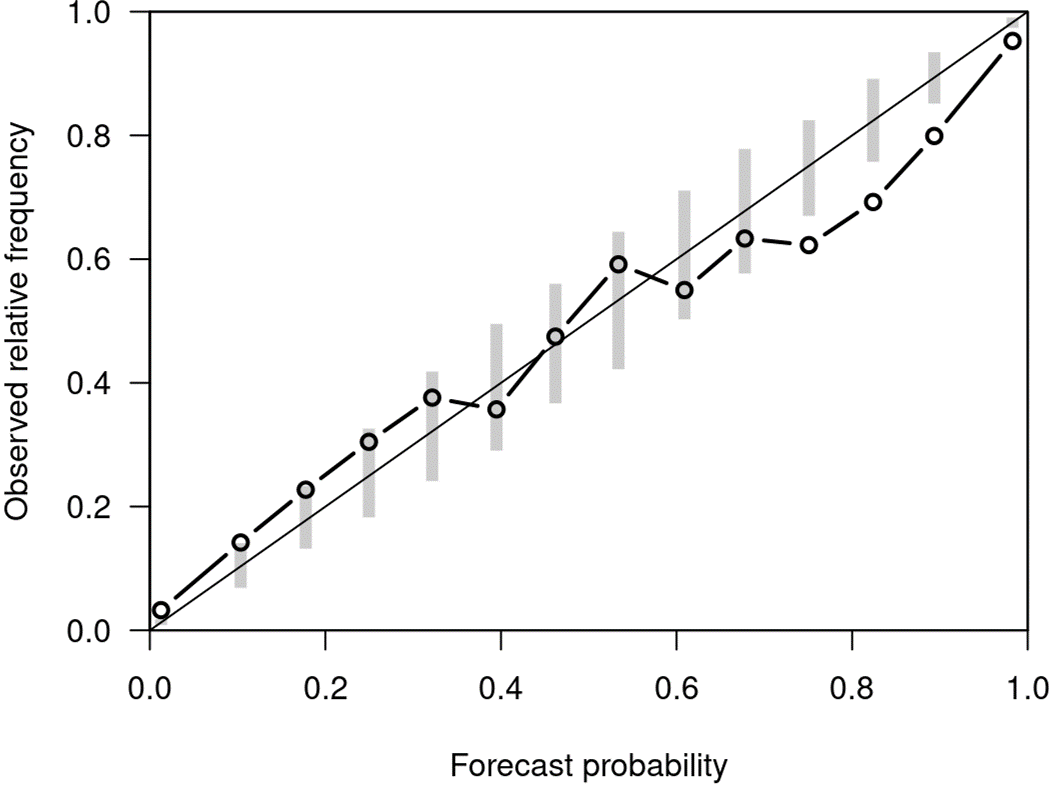
We consider calibration of convolutional classifiers for diagnostic decision making. Clinical decision makers can use calibrated classifiers to minimise expected costs given their own cost function. Such functions are usually unknown at training time. If minimising expected costs is the primary aim, algorithms should focus on tuning calibration in regions of probability simplex likely to effect decisions. We give an example, modifying temperature scaling calibration, and demonstrate improved calibration where it matters using convnets trained to classify dermoscopy images.
Read more6/18/2024
🔮
0
On Temperature Scaling and Conformal Prediction of Deep Classifiers
Lahav Dabah, Tom Tirer
In many classification applications, the prediction of a deep neural network (DNN) based classifier needs to be accompanied by some confidence indication. Two popular approaches for that aim are: 1) Calibration: modifies the classifier's softmax values such that the maximal value better estimates the correctness probability; and 2) Conformal Prediction (CP): produces a prediction set of candidate labels that contains the true label with a user-specified probability, guaranteeing marginal coverage, rather than, e.g., per class coverage. In practice, both types of indications are desirable, yet, so far the interplay between them has not been investigated. We start this paper with an extensive empirical study of the effect of the popular Temperature Scaling (TS) calibration on prominent CP methods and reveal that while it improves the class-conditional coverage of adaptive CP methods, surprisingly, it negatively affects their prediction set sizes. Subsequently, we explore the effect of TS beyond its calibration application and offer simple guidelines for practitioners to trade prediction set size and conditional coverage of adaptive CP methods while effectively combining them with calibration. Finally, we present a theoretical analysis of the effect of TS on the prediction set sizes, revealing several mathematical properties of the procedure, according to which we provide reasoning for this unintuitive phenomenon.
Read more7/8/2024

0
Improving Calibration by Relating Focal Loss, Temperature Scaling, and Properness
Viacheslav Komisarenko, Meelis Kull
Proper losses such as cross-entropy incentivize classifiers to produce class probabilities that are well-calibrated on the training data. Due to the generalization gap, these classifiers tend to become overconfident on the test data, mandating calibration methods such as temperature scaling. The focal loss is not proper, but training with it has been shown to often result in classifiers that are better calibrated on test data. Our first contribution is a simple explanation about why focal loss training often leads to better calibration than cross-entropy training. For this, we prove that focal loss can be decomposed into a confidence-raising transformation and a proper loss. This is why focal loss pushes the model to provide under-confident predictions on the training data, resulting in being better calibrated on the test data, due to the generalization gap. Secondly, we reveal a strong connection between temperature scaling and focal loss through its confidence-raising transformation, which we refer to as the focal calibration map. Thirdly, we propose focal temperature scaling - a new post-hoc calibration method combining focal calibration and temperature scaling. Our experiments on three image classification datasets demonstrate that focal temperature scaling outperforms standard temperature scaling.
Read more8/22/2024
🏷️
0
Calibrated Selective Classification
Adam Fisch, Tommi Jaakkola, Regina Barzilay
Selective classification allows models to abstain from making predictions (e.g., say I don't know) when in doubt in order to obtain better effective accuracy. While typical selective models can be effective at producing more accurate predictions on average, they may still allow for wrong predictions that have high confidence, or skip correct predictions that have low confidence. Providing calibrated uncertainty estimates alongside predictions -- probabilities that correspond to true frequencies -- can be as important as having predictions that are simply accurate on average. However, uncertainty estimates can be unreliable for certain inputs. In this paper, we develop a new approach to selective classification in which we propose a method for rejecting examples with uncertain uncertainties. By doing so, we aim to make predictions with {well-calibrated} uncertainty estimates over the distribution of accepted examples, a property we call selective calibration. We present a framework for learning selectively calibrated models, where a separate selector network is trained to improve the selective calibration error of a given base model. In particular, our work focuses on achieving robust calibration, where the model is intentionally designed to be tested on out-of-domain data. We achieve this through a training strategy inspired by distributionally robust optimization, in which we apply simulated input perturbations to the known, in-domain training data. We demonstrate the empirical effectiveness of our approach on multiple image classification and lung cancer risk assessment tasks.
Read more6/24/2024