Improving Factuality in Large Language Models via Decoding-Time Hallucinatory and Truthful Comparators

0

Sign in to get full access
Overview
- This paper presents a novel approach to improve the factuality of large language models (LLMs) during the decoding process.
- The proposed method introduces "hallucinatory" and "truthful" comparators that help the model distinguish between factual and hallucinatory outputs.
- The approach is designed to mitigate the problem of LLMs generating plausible-sounding but factually incorrect information, known as "hallucination."
Plain English Explanation
The paper addresses a common issue with large language models (LLMs) - their tendency to generate text that sounds convincing but is not actually true. This problem, known as "hallucination," can be problematic when these models are used for tasks like question-answering or content generation.
The researchers' solution is to introduce two new components during the decoding process:
- Hallucinatory comparators - These help the model identify when it is generating text that is likely to be factually incorrect or made up.
- Truthful comparators - These guide the model towards generating text that is more grounded in facts and reality.
By incorporating these comparators, the researchers aim to improve the factuality of the model's outputs without significantly impacting its performance on other tasks. This could make LLMs more reliable and trustworthy for applications where factual accuracy is important.
Technical Explanation
The paper proposes a novel decoding-time approach to improve the factuality of large language models (LLMs). The key components are:
-
Hallucinatory comparators: These are models trained to identify when the LLM is generating hallucinatory (i.e., factually incorrect) outputs. During decoding, the hallucinatory comparator scores are used to penalize the LLM's likelihood of generating such outputs.
-
Truthful comparators: These are models trained to identify when the LLM is generating truthful, factually correct outputs. The truthful comparator scores are used to positively reinforce the LLM's likelihood of generating factual outputs.
The researchers experiment with different ways of incorporating these comparators, including using them to directly modify the LLM's logits during decoding, as well as using them to rerank the model's top-k predicted tokens.
The paper evaluates the approach on a range of factuality-focused benchmarks, demonstrating that it can significantly improve the factuality of the LLM's outputs without substantially impacting its performance on other tasks.
Critical Analysis
The paper presents a well-designed and thorough investigation into improving the factuality of large language models. The key strengths are:
- The novel decoding-time approach, which is a practical solution to a challenging problem faced by LLMs.
- The comprehensive evaluation, which covers multiple factuality-focused benchmarks and examines the impact on other tasks.
- The clear articulation of the limitations, such as the potential for the comparator models to introduce biases or fail to generalize to all types of hallucinations.
However, some potential areas for further research include:
- Investigating the broader applicability of the approach, such as whether it can be effectively applied to different types of LLMs or tasks beyond language generation.
- Exploring more advanced techniques for training the comparator models, to improve their accuracy and generalization capabilities.
- Considering alternative approaches to mitigating hallucinations, such as directly modifying the LLM's training or architecture, and comparing their relative strengths and weaknesses.
Overall, this paper makes a valuable contribution to the ongoing efforts to make large language models more reliable and trustworthy.
Conclusion
This paper presents a novel decoding-time approach to improving the factuality of large language models. By incorporating "hallucinatory" and "truthful" comparators, the model can better distinguish between factual and hallucinatory outputs, leading to more reliable and trustworthy text generation.
The comprehensive evaluation demonstrates the effectiveness of this approach, and the researchers' clear articulation of the limitations and potential areas for future research make this a valuable contribution to the field. As LLMs continue to advance and find wider real-world applications, addressing issues like hallucination will be increasingly important, and this work provides a promising direction for further exploration.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Improving Factuality in Large Language Models via Decoding-Time Hallucinatory and Truthful Comparators
Dingkang Yang, Dongling Xiao, Jinjie Wei, Mingcheng Li, Zhaoyu Chen, Ke Li, Lihua Zhang
Despite their remarkable capabilities, Large Language Models (LLMs) are prone to generate responses that contradict verifiable facts, i.e., unfaithful hallucination content. Existing efforts generally focus on optimizing model parameters or editing semantic representations, which compromise the internal factual knowledge of target LLMs. In addition, hallucinations typically exhibit multifaceted patterns in downstream tasks, limiting the model's holistic performance across tasks. In this paper, we propose a Comparator-driven Decoding-Time (CDT) framework to alleviate the response hallucination. Firstly, we construct hallucinatory and truthful comparators with multi-task fine-tuning samples. In this case, we present an instruction prototype-guided mixture of experts strategy to enhance the ability of the corresponding comparators to capture different hallucination or truthfulness patterns in distinct task instructions. CDT constrains next-token predictions to factuality-robust distributions by contrasting the logit differences between the target LLMs and these comparators. Systematic experiments on multiple downstream tasks show that our framework can significantly improve the model performance and response factuality.
Read more9/10/2024
0
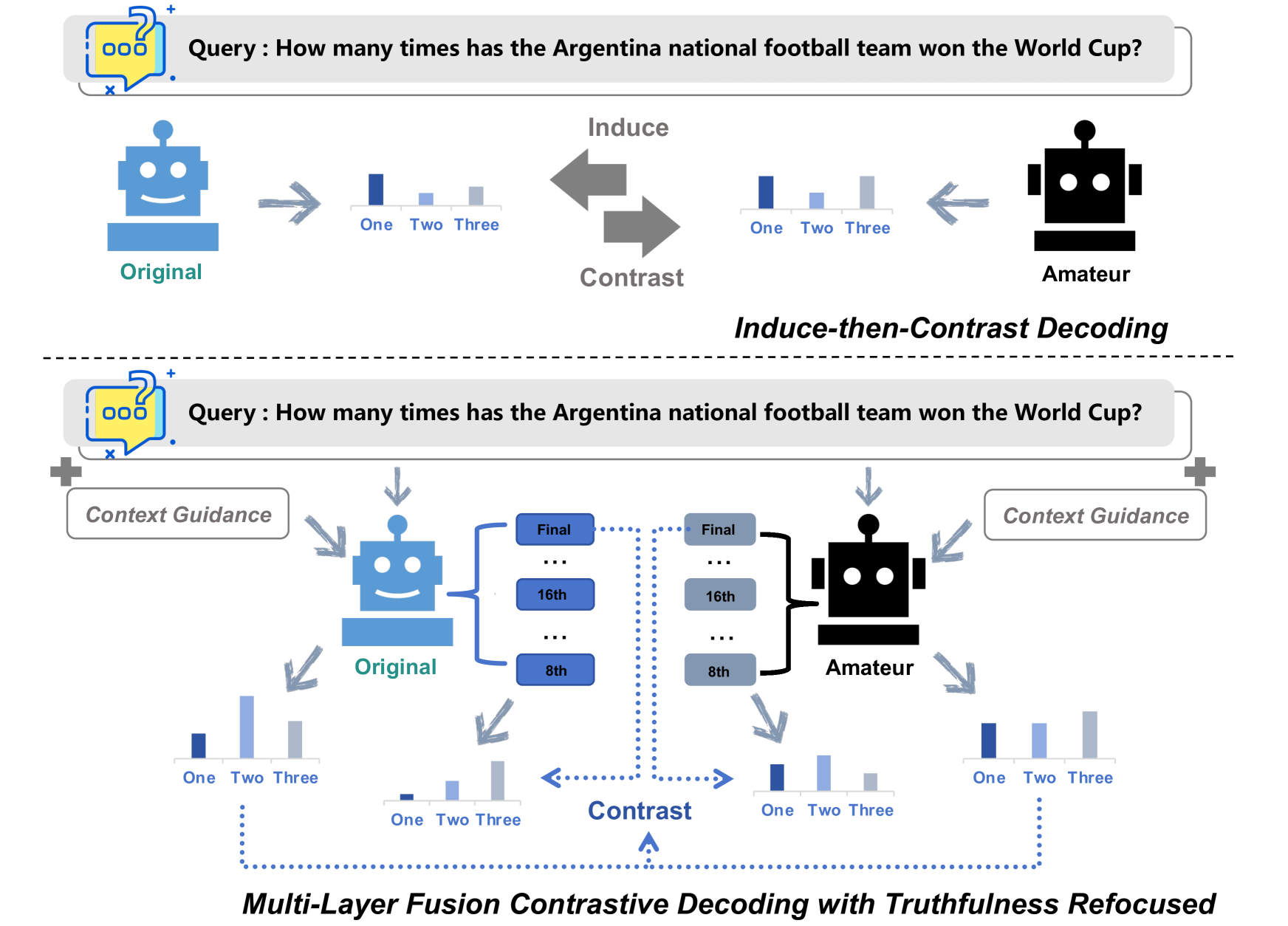
Lower Layer Matters: Alleviating Hallucination via Multi-Layer Fusion Contrastive Decoding with Truthfulness Refocused
Dingwei Chen, Feiteng Fang, Shiwen Ni, Feng Liang, Ruifeng Xu, Min Yang, Chengming Li
Large Language Models (LLMs) have demonstrated exceptional performance across various natural language processing tasks, yet they occasionally tend to yield content that factually inaccurate or discordant with the expected output, a phenomenon empirically referred to as hallucination. To tackle this issue, recent works have investigated contrastive decoding between the original model and an amateur model with induced hallucination, which has shown promising results. Nonetheless, this method may undermine the output distribution of the original LLM caused by its coarse contrast and simplistic subtraction operation, potentially leading to errors in certain cases. In this paper, we introduce a novel contrastive decoding framework termed LOL (LOwer Layer Matters). Our approach involves concatenating the contrastive decoding of both the final and lower layers between the original model and the amateur model, thereby achieving multi-layer fusion to aid in the mitigation of hallucination. Additionally, we incorporate a truthfulness refocused module that leverages contextual guidance to enhance factual encoding, further capturing truthfulness during contrastive decoding. Extensive experiments conducted on two publicly available datasets illustrate that our proposed LOL framework can substantially alleviate hallucination while surpassing existing baselines in most cases. Compared with the best baseline, we improve by average 4.5 points on all metrics of TruthfulQA. The source code is coming soon.
Read more8/19/2024

0
FactCHD: Benchmarking Fact-Conflicting Hallucination Detection
Xiang Chen, Duanzheng Song, Honghao Gui, Chenxi Wang, Ningyu Zhang, Yong Jiang, Fei Huang, Chengfei Lv, Dan Zhang, Huajun Chen
Despite their impressive generative capabilities, LLMs are hindered by fact-conflicting hallucinations in real-world applications. The accurate identification of hallucinations in texts generated by LLMs, especially in complex inferential scenarios, is a relatively unexplored area. To address this gap, we present FactCHD, a dedicated benchmark designed for the detection of fact-conflicting hallucinations from LLMs. FactCHD features a diverse dataset that spans various factuality patterns, including vanilla, multi-hop, comparison, and set operation. A distinctive element of FactCHD is its integration of fact-based evidence chains, significantly enhancing the depth of evaluating the detectors' explanations. Experiments on different LLMs expose the shortcomings of current approaches in detecting factual errors accurately. Furthermore, we introduce Truth-Triangulator that synthesizes reflective considerations by tool-enhanced ChatGPT and LoRA-tuning based on Llama2, aiming to yield more credible detection through the amalgamation of predictive results and evidence. The benchmark dataset is available at https://github.com/zjunlp/FactCHD.
Read more5/28/2024

0
TruthX: Alleviating Hallucinations by Editing Large Language Models in Truthful Space
Shaolei Zhang, Tian Yu, Yang Feng
Large Language Models (LLMs) sometimes suffer from producing hallucinations, especially LLMs may generate untruthful responses despite knowing the correct knowledge. Activating the truthfulness within LLM is the key to fully unlocking LLM's knowledge potential. In this paper, we propose TruthX, an inference-time intervention method to activate the truthfulness of LLM by identifying and editing the features within LLM's internal representations that govern the truthfulness. TruthX employs an auto-encoder to map LLM's representations into semantic and truthful latent spaces respectively, and applies contrastive learning to identify a truthful editing direction within the truthful space. During inference, by editing LLM's internal representations in truthful space, TruthX effectively enhances the truthfulness of LLM. Experiments show that TruthX improves the truthfulness of 13 advanced LLMs by an average of 20% on TruthfulQA benchmark. Further analyses suggest that TruthX can control LLM to produce truthful or hallucinatory responses via editing only one vector in LLM's internal representations.
Read more6/6/2024