Lower Layer Matters: Alleviating Hallucination via Multi-Layer Fusion Contrastive Decoding with Truthfulness Refocused

0
Sign in to get full access
Overview
- The paper proposes a new technique called "Multi-Layer Fusion Contrastive Decoding with Truthfulness Refocused" to mitigate hallucination in large language models.
- Hallucination refers to the model generating plausible-sounding but false or nonsensical information.
- The technique aims to improve the truthfulness and faithfulness of model outputs by fusing representations from multiple model layers during decoding.
Plain English Explanation
The paper focuses on an important issue with large language models - their tendency to hallucinate or generate text that sounds convincing but is factually incorrect or nonsensical. To address this, the researchers developed a new approach called "Multi-Layer Fusion Contrastive Decoding with Truthfulness Refocused."
The key idea is to leverage information from multiple layers of the language model, rather than just relying on the final output layer. By fusing representations from different layers during the decoding process, the model can better distinguish truthful, grounded outputs from hallucinated ones. This "multi-layer fusion" helps the model stay more faithful to the actual information in its training data.
Additionally, the technique includes a "contrastive decoding" step that encourages the model to choose outputs that are more truthful and aligned with the input, rather than outputs that sound plausible but are disconnected from reality. This "truthfulness refocused" approach further reduces the model's tendency to hallucinate.
Technical Explanation
The paper presents a new technique called "Multi-Layer Fusion Contrastive Decoding with Truthfulness Refocused" to mitigate hallucination in large language models.
The core of the approach is to fuse representations from multiple layers of the language model during the decoding process, rather than just relying on the final output layer. This allows the model to better distinguish truthful, grounded outputs from hallucinated ones.
Specifically, the technique involves:
- Extracting representations from multiple layers of the pre-trained language model.
- Fusing these multi-layer representations using a learned fusion module.
- Performing a "contrastive decoding" step that encourages the model to choose outputs that are more truthful and aligned with the input, rather than plausible but disconnected from reality.
This "truthfulness refocused" approach helps reduce the model's tendency to hallucinate, as it can better leverage the information in its training data to generate faithful outputs.
The paper evaluates the technique on several language modeling benchmarks and shows it outperforms previous hallucination mitigation approaches in terms of faithfulness and truthfulness of the generated text.
Critical Analysis
The paper presents a well-designed and thorough approach to addressing the important issue of hallucination in large language models. The multi-layer fusion and contrastive decoding techniques are novel and show promising results.
However, the paper does not fully address the underlying reasons why language models tend to hallucinate in the first place. While the techniques can mitigate the issue, further research is needed to understand the fundamental causes and develop more comprehensive solutions.
Additionally, the paper only evaluates the approach on language modeling tasks. It would be interesting to see how the techniques perform on other applications, such as vision-language models or instruction-following models, where hallucination can also be a significant problem.
Conclusion
The "Multi-Layer Fusion Contrastive Decoding with Truthfulness Refocused" approach presented in this paper is a valuable contribution to the ongoing efforts to mitigate hallucination in large language models. By leveraging information from multiple model layers and encouraging truthful outputs, the technique can help improve the reliability and trustworthiness of model-generated text.
While further research is needed to fully understand and address the root causes of hallucination, this work represents an important step forward in developing more faithful and trustworthy language AI systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Lower Layer Matters: Alleviating Hallucination via Multi-Layer Fusion Contrastive Decoding with Truthfulness Refocused
Dingwei Chen, Feiteng Fang, Shiwen Ni, Feng Liang, Ruifeng Xu, Min Yang, Chengming Li
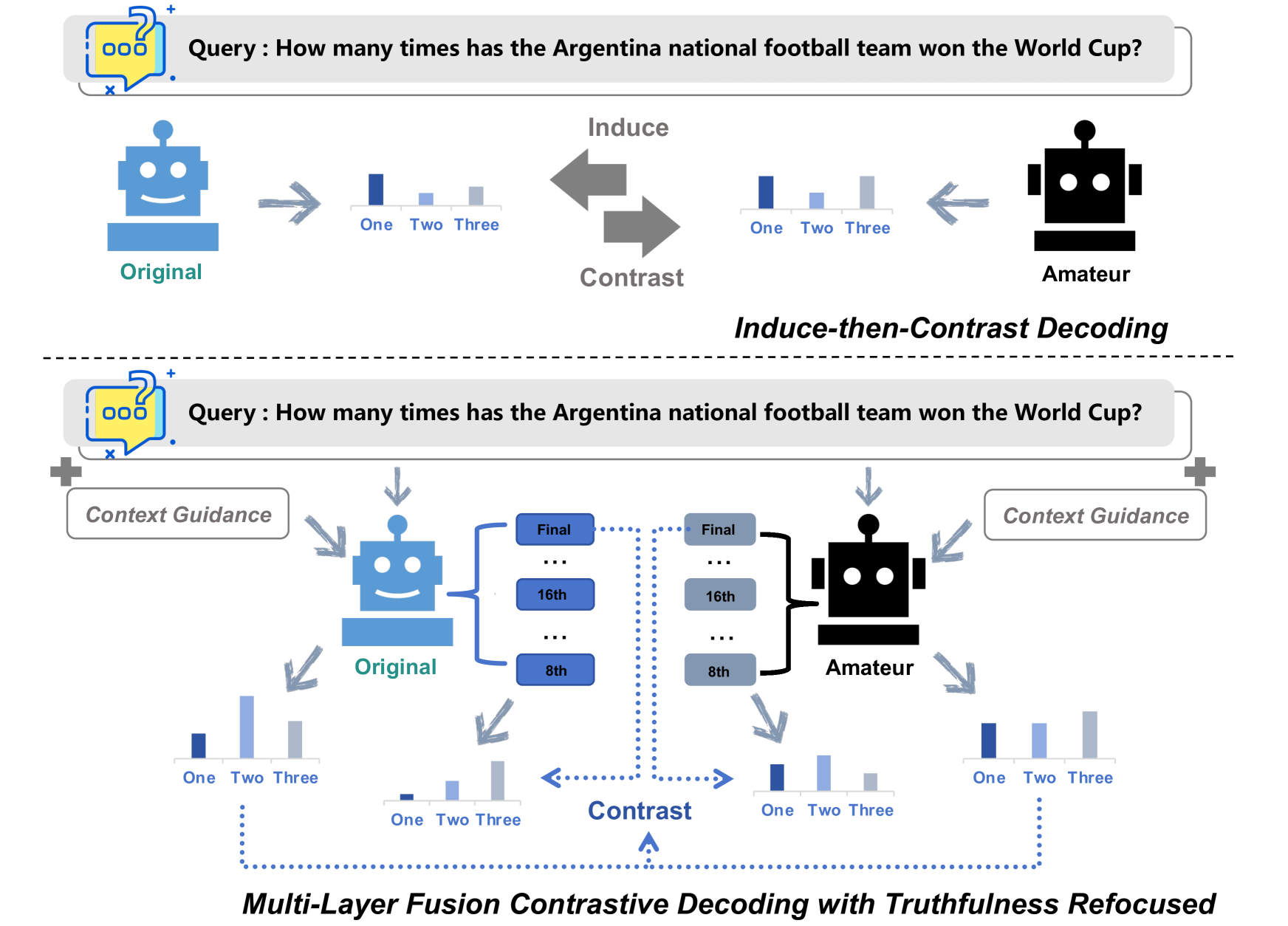
Large Language Models (LLMs) have demonstrated exceptional performance across various natural language processing tasks, yet they occasionally tend to yield content that factually inaccurate or discordant with the expected output, a phenomenon empirically referred to as hallucination. To tackle this issue, recent works have investigated contrastive decoding between the original model and an amateur model with induced hallucination, which has shown promising results. Nonetheless, this method may undermine the output distribution of the original LLM caused by its coarse contrast and simplistic subtraction operation, potentially leading to errors in certain cases. In this paper, we introduce a novel contrastive decoding framework termed LOL (LOwer Layer Matters). Our approach involves concatenating the contrastive decoding of both the final and lower layers between the original model and the amateur model, thereby achieving multi-layer fusion to aid in the mitigation of hallucination. Additionally, we incorporate a truthfulness refocused module that leverages contextual guidance to enhance factual encoding, further capturing truthfulness during contrastive decoding. Extensive experiments conducted on two publicly available datasets illustrate that our proposed LOL framework can substantially alleviate hallucination while surpassing existing baselines in most cases. Compared with the best baseline, we improve by average 4.5 points on all metrics of TruthfulQA. The source code is coming soon.
Read more8/19/2024

0
Improving Factuality in Large Language Models via Decoding-Time Hallucinatory and Truthful Comparators
Dingkang Yang, Dongling Xiao, Jinjie Wei, Mingcheng Li, Zhaoyu Chen, Ke Li, Lihua Zhang
Despite their remarkable capabilities, Large Language Models (LLMs) are prone to generate responses that contradict verifiable facts, i.e., unfaithful hallucination content. Existing efforts generally focus on optimizing model parameters or editing semantic representations, which compromise the internal factual knowledge of target LLMs. In addition, hallucinations typically exhibit multifaceted patterns in downstream tasks, limiting the model's holistic performance across tasks. In this paper, we propose a Comparator-driven Decoding-Time (CDT) framework to alleviate the response hallucination. Firstly, we construct hallucinatory and truthful comparators with multi-task fine-tuning samples. In this case, we present an instruction prototype-guided mixture of experts strategy to enhance the ability of the corresponding comparators to capture different hallucination or truthfulness patterns in distinct task instructions. CDT constrains next-token predictions to factuality-robust distributions by contrasting the logit differences between the target LLMs and these comparators. Systematic experiments on multiple downstream tasks show that our framework can significantly improve the model performance and response factuality.
Read more9/10/2024

0
Mitigating Large Language Model Hallucination with Faithful Finetuning
Minda Hu, Bowei He, Yufei Wang, Liangyou Li, Chen Ma, Irwin King
Large language models (LLMs) have demonstrated remarkable performance on various natural language processing tasks. However, they are prone to generating fluent yet untruthful responses, known as hallucinations. Hallucinations can lead to the spread of misinformation and cause harm in critical applications. Mitigating hallucinations is challenging as they arise from factors such as noisy data, model overconfidence, lack of knowledge, and the generation process itself. Recent efforts have attempted to address this issue through representation editing and decoding algorithms, reducing hallucinations without major structural changes or retraining. However, these approaches either implicitly edit LLMs' behavior in latent space or suppress the tendency to output unfaithful results during decoding instead of explicitly modeling on hallucination. In this work, we introduce Faithful Finetuning (F2), a novel method that explicitly models the process of faithful question answering through carefully designed loss functions during fine-tuning. We conduct extensive experiments on popular datasets and demonstrate that F2 achieves significant improvements over vanilla models and baselines.
Read more6/18/2024

0
Mitigating Hallucinations in Large Vision-Language Models (LVLMs) via Language-Contrastive Decoding (LCD)
Avshalom Manevich, Reut Tsarfaty
Large Vision-Language Models (LVLMs) are an extension of Large Language Models (LLMs) that facilitate processing both image and text inputs, expanding AI capabilities. However, LVLMs struggle with object hallucinations due to their reliance on text cues and learned object co-occurrence biases. While most research quantifies these hallucinations, mitigation strategies are still lacking. Our study introduces a Language Contrastive Decoding (LCD) algorithm that adjusts LVLM outputs based on LLM distribution confidence levels, effectively reducing object hallucinations. We demonstrate the advantages of LCD in leading LVLMs, showing up to %4 improvement in POPE F1 scores and up to %36 reduction in CHAIR scores on the COCO validation set, while also improving captioning quality scores. Our method effectively improves LVLMs without needing complex post-processing or retraining, and is easily applicable to different models. Our findings highlight the potential of further exploration of LVLM-specific decoding algorithms.
Read more8/12/2024