Improving Faithfulness of Large Language Models in Summarization via Sliding Generation and Self-Consistency

0

Sign in to get full access
Overview
- Explores ways to improve the faithfulness of large language models in summarization tasks
- Proposes two techniques: sliding generation and self-consistency
- Demonstrates effectiveness on several summarization datasets
Plain English Explanation
The research paper discusses methods to improve the accuracy and reliability of large language models when generating summaries of text. Large language models, which are AI systems trained on vast amounts of text data, have become powerful tools for tasks like text summarization. However, these models can sometimes produce summaries that don't fully capture the meaning or factual content of the original text.
The researchers propose two techniques to address this issue:
-
Sliding Generation: Instead of generating the entire summary at once, this method generates the summary in smaller, overlapping segments. This helps the model maintain a stronger connection to the original text and produce more faithful summaries.
-
Self-Consistency: This technique encourages the model to generate summaries that are internally consistent. By evaluating the model's own outputs and favoring consistent summaries, the researchers were able to improve the factual accuracy and coherence of the generated text.
Through experiments on several popular summarization datasets, the researchers demonstrated that these techniques can lead to significant improvements in the faithfulness and quality of the summaries produced by large language models. This work has important implications for making these powerful AI systems more reliable and trustworthy in real-world applications.
Technical Explanation
The paper introduces two novel techniques to improve the faithfulness of large language models in summarization tasks:
-
Sliding Generation: Conventional summarization models generate the entire summary at once, which can lead to a lack of faithfulness to the source text. The sliding generation approach instead generates the summary in smaller, overlapping segments. This helps the model maintain a stronger connection to the original text and produce more faithful summaries.
-
Self-Consistency: Large language models can sometimes generate summaries that are internally inconsistent or factually inaccurate. The self-consistency technique addresses this by evaluating the model's own outputs and favoring summaries that are more self-consistent. This helps improve the factual accuracy and coherence of the generated text.
The researchers evaluate these techniques on several summarization datasets, including CNN/Daily Mail, XSum, and SAMSum. They find that the sliding generation and self-consistency approaches lead to significant improvements in faithfulness, as measured by metrics like FEQA (Fact Extraction and Verification for Question Answering) and SummaC (Summarization Consistency).
The paper provides a detailed description of the experimental setup, including the model architectures, training procedures, and evaluation metrics. The results demonstrate the effectiveness of the proposed techniques, with the combined sliding generation and self-consistency approach outperforming strong baselines across multiple datasets.
Critical Analysis
The paper presents a compelling approach to improving the faithfulness of large language models in summarization tasks. The sliding generation and self-consistency techniques seem to effectively address some of the key challenges faced by these models, such as producing summaries that are disconnected from the source text or internally inconsistent.
One potential limitation of the work is the reliance on relatively small-scale summarization datasets, which may not fully capture the diversity and complexity of real-world summarization scenarios. Additionally, the paper does not provide a detailed analysis of the types of factual errors or inconsistencies that the proposed techniques are able to address, which could be valuable for understanding the broader implications and limitations of the approach.
Further research could also explore the interplay between faithfulness and other desirable properties of summaries, such as conciseness, readability, and relevance. It would be interesting to see how the sliding generation and self-consistency techniques affect these other aspects of summarization performance.
Overall, the paper presents a promising step towards making large language models more reliable and trustworthy in practical applications that require accurate and faithful text summarization.
Conclusion
This research paper introduces two novel techniques, sliding generation and self-consistency, to improve the faithfulness of large language models in text summarization tasks. The experiments demonstrate that these approaches can significantly enhance the factual accuracy and coherence of the generated summaries, addressing some of the key limitations of conventional summarization models.
The findings of this work have important implications for the development of more reliable and trustworthy AI systems, particularly in applications where the factual integrity of generated text is crucial. As large language models continue to advance, techniques like those proposed in this paper will be increasingly important for ensuring these powerful systems produce outputs that are both informative and truthful.
The paper's contributions lay the groundwork for further research and development in this area, pointing to potential avenues for improving the faithfulness, robustness, and real-world applicability of large-scale language models in summarization and beyond.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Improving Faithfulness of Large Language Models in Summarization via Sliding Generation and Self-Consistency
Taiji Li, Zhi Li, Yin Zhang
Despite large language models (LLMs) have demonstrated impressive performance in various tasks, they are still suffering from the factual inconsistency problem called hallucinations. For instance, LLMs occasionally generate content that diverges from source article, and prefer to extract information that appears at the beginning and end of the context, especially in long document summarization. Inspired by these findings, we propose to improve the faithfulness of LLMs in summarization by impelling them to process the entire article more fairly and faithfully. We present a novel summary generation strategy, namely SliSum, which exploits the ideas of sliding windows and self-consistency. Specifically, SliSum divides the source article into overlapping windows, and utilizes LLM to generate local summaries for the content in the windows. Finally, SliSum aggregates all local summaries using clustering and majority voting algorithm to produce more faithful summary of entire article. Extensive experiments demonstrate that SliSum significantly improves the faithfulness of diverse LLMs including LLaMA-2, Claude-2 and GPT-3.5 in both short and long text summarization, while maintaining their fluency and informativeness and without additional fine-tuning and resources. We further conduct qualitative and quantitative studies to investigate why SliSum works and impacts of hyperparameters in SliSum on performance.
Read more8/1/2024
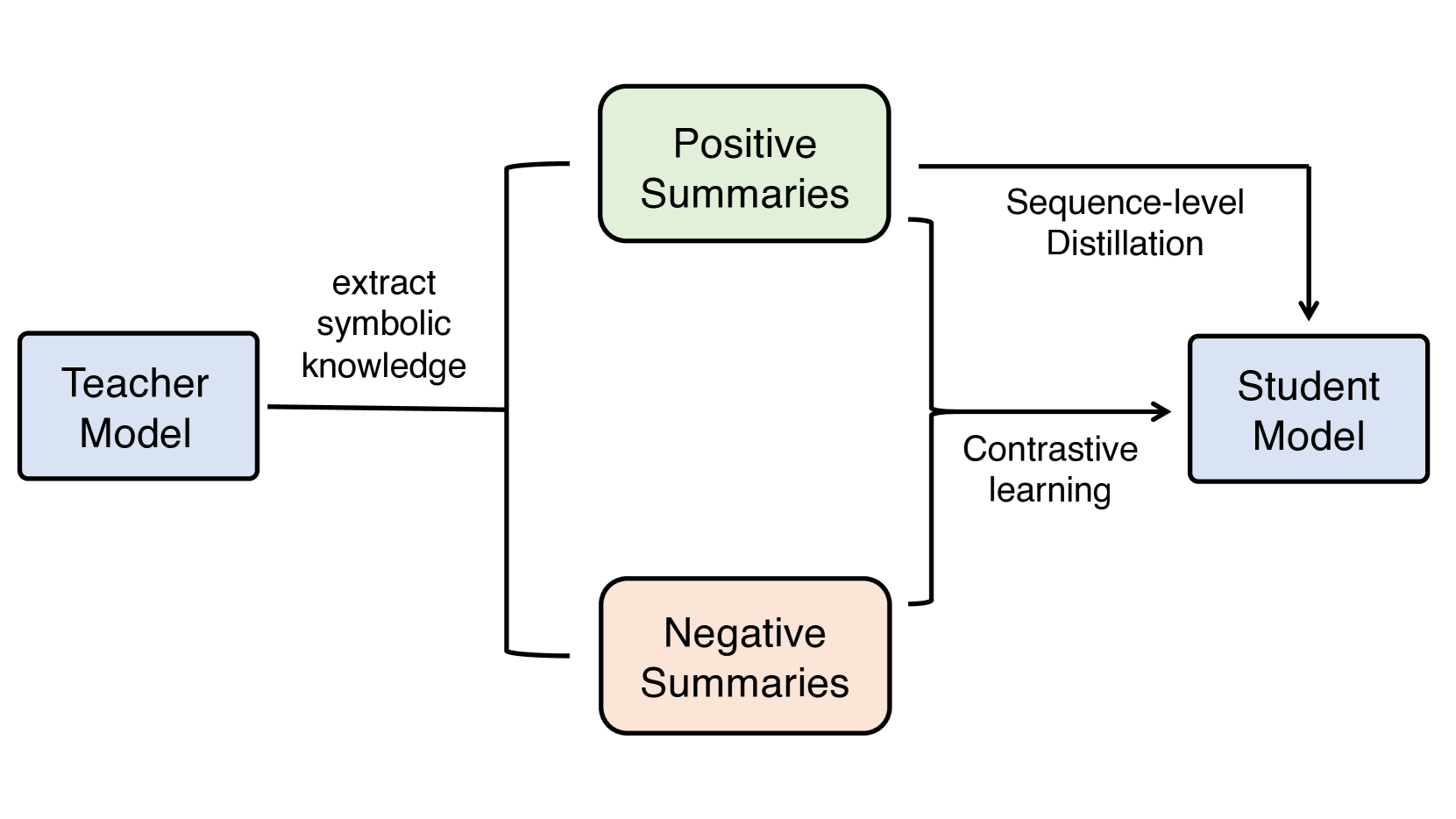
0
Factual Dialogue Summarization via Learning from Large Language Models
Rongxin Zhu, Jey Han Lau, Jianzhong Qi
Factual consistency is an important quality in dialogue summarization. Large language model (LLM)-based automatic text summarization models generate more factually consistent summaries compared to those by smaller pretrained language models, but they face deployment challenges in real-world applications due to privacy or resource constraints. In this paper, we investigate the use of symbolic knowledge distillation to improve the factual consistency of smaller pretrained models for dialogue summarization. We employ zero-shot learning to extract symbolic knowledge from LLMs, generating both factually consistent (positive) and inconsistent (negative) summaries. We then apply two contrastive learning objectives on these summaries to enhance smaller summarization models. Experiments with BART, PEGASUS, and Flan-T5 indicate that our approach surpasses strong baselines that rely on complex data augmentation strategies. Our approach achieves better factual consistency while maintaining coherence, fluency, and relevance, as confirmed by various automatic evaluation metrics. We also provide access to the data and code to facilitate future research.
Read more6/24/2024

0
Leveraging Entailment Judgements in Cross-Lingual Summarisation
Huajian Zhang, Laura Perez-Beltrachini
Synthetically created Cross-Lingual Summarisation (CLS) datasets are prone to include document-summary pairs where the reference summary is unfaithful to the corresponding document as it contains content not supported by the document (i.e., hallucinated content). This low data quality misleads model learning and obscures evaluation results. Automatic ways to assess hallucinations and improve training have been proposed for monolingual summarisation, predominantly in English. For CLS, we propose to use off-the-shelf cross-lingual Natural Language Inference (X-NLI) to evaluate faithfulness of reference and model generated summaries. Then, we study training approaches that are aware of faithfulness issues in the training data and propose an approach that uses unlikelihood loss to teach a model about unfaithful summary sequences. Our results show that it is possible to train CLS models that yield more faithful summaries while maintaining comparable or better informativess.
Read more8/2/2024
💬
0
Can Large Language Model Summarizers Adapt to Diverse Scientific Communication Goals?
Marcio Fonseca, Shay B. Cohen
In this work, we investigate the controllability of large language models (LLMs) on scientific summarization tasks. We identify key stylistic and content coverage factors that characterize different types of summaries such as paper reviews, abstracts, and lay summaries. By controlling stylistic features, we find that non-fine-tuned LLMs outperform humans in the MuP review generation task, both in terms of similarity to reference summaries and human preferences. Also, we show that we can improve the controllability of LLMs with keyword-based classifier-free guidance (CFG) while achieving lexical overlap comparable to strong fine-tuned baselines on arXiv and PubMed. However, our results also indicate that LLMs cannot consistently generate long summaries with more than 8 sentences. Furthermore, these models exhibit limited capacity to produce highly abstractive lay summaries. Although LLMs demonstrate strong generic summarization competency, sophisticated content control without costly fine-tuning remains an open problem for domain-specific applications.
Read more6/28/2024