Improving Real-Time Music Accompaniment Separation with MMDenseNet

0

Sign in to get full access
Overview
- This paper presents a novel deep learning model called MMDenseNet for improving real-time music accompaniment separation.
- The model combines a dense convolutional neural network architecture with multi-scale feature extraction to better separate the vocal and accompaniment components of music signals.
- The authors evaluate the model's performance on several music source separation benchmarks and demonstrate significant improvements over existing state-of-the-art methods.
Plain English Explanation
In the world of music, there is often a need to separate the different instrumental and vocal elements that make up a song. This process, known as source separation, can be useful for a variety of applications, such as remixing music, removing vocals, or enhancing audio quality.
The authors of this paper have developed a new deep learning model called MMDenseNet that is particularly good at separating the accompaniment (the instrumental parts) from the vocals in real-time. The model uses a dense convolutional neural network architecture, which means it has a lot of interconnected layers that can learn complex patterns in the audio data. It also incorporates multiple scales of feature extraction, allowing it to capture both high-level and low-level information about the music.
Through extensive testing on various music source separation benchmarks, the researchers demonstrate that their MMDenseNet model outperforms existing state-of-the-art methods, particularly when it comes to separating the accompaniment from the vocals in real-time. This could have important implications for a wide range of music-related applications and technologies.
Technical Explanation
The key innovation in this paper is the development of the MMDenseNet architecture for real-time music accompaniment separation. The model combines several techniques to improve upon previous approaches:
-
Dense Convolutional Neural Network: The core of the model is a dense convolutional neural network, which has a highly interconnected structure that allows it to learn complex features from the audio data. This architecture has been shown to be effective for various audio processing tasks, including speech enhancement and music source separation.
-
Multi-Scale Feature Extraction: In addition to the dense connections, the model also incorporates multiple scales of feature extraction. This means it can capture both high-level information (such as overall musical structure) and low-level details (such as individual instrument timbres) simultaneously, which is crucial for accurately separating the accompaniment from the vocals.
-
Real-Time Inference: The authors pay particular attention to ensuring their model can perform inference in real-time, which is essential for many practical applications of music source separation. They achieve this through careful optimization of the model architecture and inference process.
The authors evaluate the performance of their MMDenseNet model on several established music source separation benchmarks, including Demixing Secrets and MUSDB18. Their results demonstrate significant improvements over existing state-of-the-art methods, particularly in terms of separating the accompaniment from the vocals.
Critical Analysis
The paper presents a well-designed and thoroughly evaluated approach to real-time music accompaniment separation. The authors have clearly put a lot of thought into the model architecture and optimization for real-time performance, which is an important practical consideration.
However, the paper does not address some potential limitations of the work. For instance, the model may struggle with more complex musical arrangements or genres that do not fit the typical "vocals + accompaniment" pattern. Additionally, the authors do not discuss the computational and memory requirements of their model, which could be a concern for deployment on resource-constrained devices.
Furthermore, the paper could have benefited from a more in-depth discussion of the model's failure cases and potential areas for future improvement. Exploring the model's limitations and identifying opportunities for further research would have strengthened the critical analysis.
Conclusion
In this paper, the researchers have presented a novel deep learning model called MMDenseNet that demonstrates significant improvements in real-time music accompaniment separation compared to existing state-of-the-art methods. By combining a dense convolutional neural network architecture with multi-scale feature extraction, the model is able to more accurately isolate the vocal and accompaniment components of music signals.
The strong performance of MMDenseNet on several benchmark datasets suggests that this approach could have important applications in a wide range of music-related technologies, from audio editing software to music streaming services. As the field of music source separation continues to advance, the insights and techniques developed in this work may help drive further progress and innovation.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Improving Real-Time Music Accompaniment Separation with MMDenseNet
Chun-Hsiang Wang, Chung-Che Wang, Jun-You Wang, Jyh-Shing Roger Jang, Yen-Hsun Chu
Music source separation aims to separate polyphonic music into different types of sources. Most existing methods focus on enhancing the quality of separated results by using a larger model structure, rendering them unsuitable for deployment on edge devices. Moreover, these methods may produce low-quality output when the input duration is short, making them impractical for real-time applications. Therefore, the goal of this paper is to enhance a lightweight model, MMDenstNet, to strike a balance between separation quality and latency for real-time applications. Different directions of improvement are explored or proposed in this paper, including complex ideal ratio mask, self-attention, band-merge-split method, and feature look back. Source-to-distortion ratio, real-time factor, and optimal latency are employed to evaluate the performance. To align with our application requirements, the evaluation process in this paper focuses on the separation performance of the accompaniment part. Experimental results demonstrate that our improvement achieves low real-time factor and optimal latency while maintaining acceptable separation quality.
Read more7/2/2024
👨🏫
0
Benchmarks and leaderboards for sound demixing tasks
Roman Solovyev, Alexander Stempkovskiy, Tatiana Habruseva
Music demixing is the task of separating different tracks from the given single audio signal into components, such as drums, bass, and vocals from the rest of the accompaniment. Separation of sources is useful for a range of areas, including entertainment and hearing aids. In this paper, we introduce two new benchmarks for the sound source separation tasks and compare popular models for sound demixing, as well as their ensembles, on these benchmarks. For the models' assessments, we provide the leaderboard at https://mvsep.com/quality_checker/, giving a comparison for a range of models. The new benchmark datasets are available for download. We also develop a novel approach for audio separation, based on the ensembling of different models that are suited best for the particular stem. The proposed solution was evaluated in the context of the Music Demixing Challenge 2023 and achieved top results in different tracks of the challenge. The code and the approach are open-sourced on GitHub.
Read more5/8/2024
🌐
0
The Whole Is Greater than the Sum of Its Parts: Improving Music Source Separation by Bridging Network
Ryosuke Sawata, Naoya Takahashi, Stefan Uhlich, Shusuke Takahashi, Yuki Mitsufuji
This paper presents the crossing scheme (X-scheme) for improving the performance of deep neural network (DNN)-based music source separation (MSS) with almost no increasing calculation cost. It consists of three components: (i) multi-domain loss (MDL), (ii) bridging operation, which couples the individual instrument networks, and (iii) combination loss (CL). MDL enables the taking advantage of the frequency- and time-domain representations of audio signals. We modify the target network, i.e., the network architecture of the original DNN-based MSS, by adding bridging paths for each output instrument to share their information. MDL is then applied to the combinations of the output sources as well as each independent source; hence, we called it CL. MDL and CL can easily be applied to many DNN-based separation methods as they are merely loss functions that are only used during training and do not affect the inference step. Bridging operation does not increase the number of learnable parameters in the network. Experimental results showed that the validity of Open-Unmix (UMX), densely connected dilated DenseNet (D3Net) and convolutional time-domain audio separation network (Conv-TasNet) extended with our X-scheme, respectively called X-UMX, X-D3Net and X-Conv-TasNet, by comparing them with their original versions. We also verified the effectiveness of X-scheme in a large-scale data regime, showing its generality with respect to data size. X-UMX Large (X-UMXL), which was trained on large-scale internal data and used in our experiments, is newly available at https://github.com/asteroid-team/asteroid/tree/master/egs/musdb18/X-UMX.
Read more8/7/2024
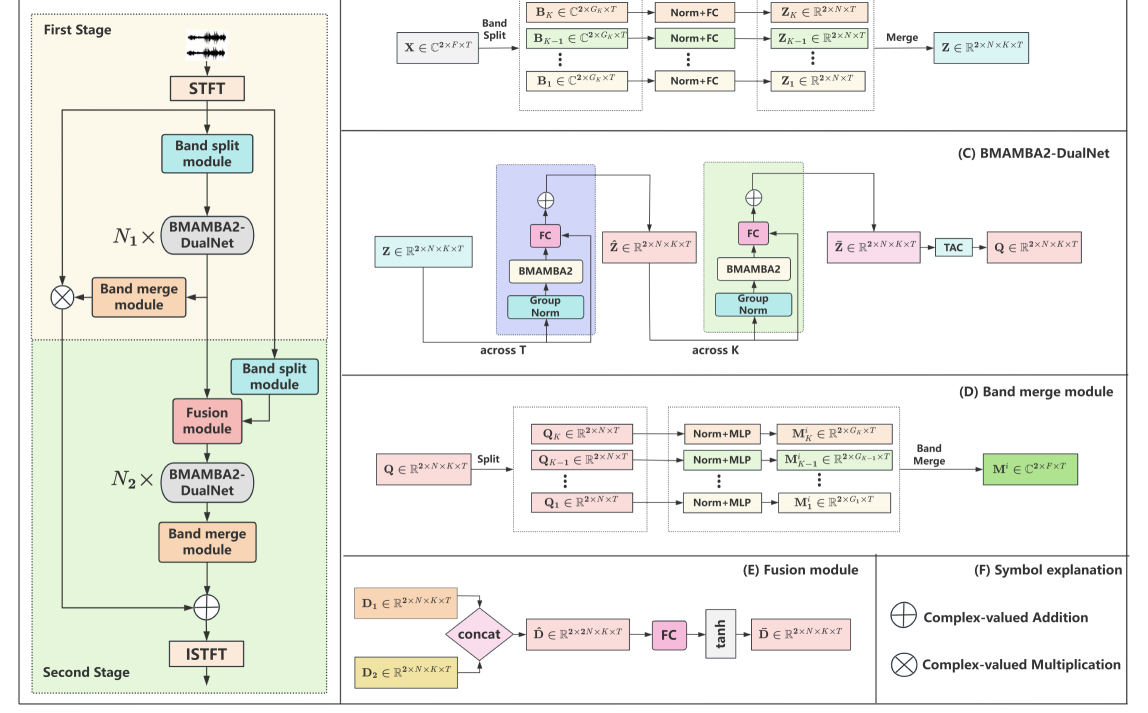
0
A Two-Stage Band-Split Mamba-2 Network for Music Separation
Jinglin Bai, Yuan Fang, Jiajie Wang, Xueliang Zhang
Music source separation (MSS) aims to separate mixed music into its distinct tracks, such as vocals, bass, drums, and more. MSS is considered to be a challenging audio separation task due to the complexity of music signals. Although the RNN and Transformer architecture are not perfect, they are commonly used to model the music sequence for MSS. Recently, Mamba-2 has already demonstrated high efficiency in various sequential modeling tasks, but its superiority has not been investigated in MSS. This paper applies Mamba-2 with a two-stage strategy, which introduces residual mapping based on the mask method, effectively compensating for the details absent in the mask and further improving separation performance. Experiments confirm the superiority of bidirectional Mamba-2 and the effectiveness of the two-stage network in MSS. The source code is publicly accessible at https://github.com/baijinglin/TS-BSmamba2.
Read more9/16/2024