Recall Them All: Retrieval-Augmented Language Models for Long Object List Extraction from Long Documents
2405.02732
0
0
Abstract
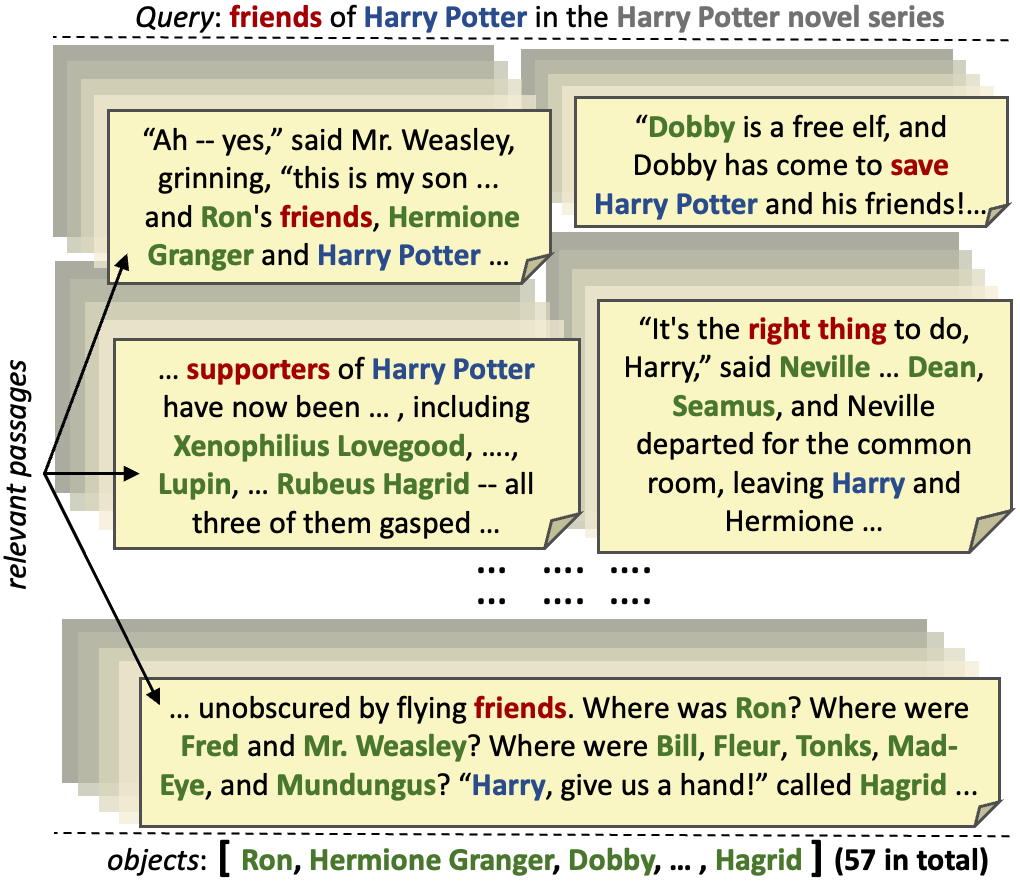
Methods for relation extraction from text mostly focus on high precision, at the cost of limited recall. High recall is crucial, though, to populate long lists of object entities that stand in a specific relation with a given subject. Cues for relevant objects can be spread across many passages in long texts. This poses the challenge of extracting long lists from long texts. We present the L3X method which tackles the problem in two stages: (1) recall-oriented generation using a large language model (LLM) with judicious techniques for retrieval augmentation, and (2) precision-oriented scrutinization to validate or prune candidates. Our L3X method outperforms LLM-only generations by a substantial margin.
Create account to get full access
Overview
- This paper presents a novel retrieval-augmented language model (RAM) approach for extracting long object lists from lengthy documents.
- The proposed method leverages large language models (LLMs) and retrieval techniques to improve the recall of object list extraction, addressing the limitations of existing methods.
- The authors conduct extensive experiments on several datasets, demonstrating the effectiveness of their RAM approach compared to baseline models.
Plain English Explanation
The paper introduces a new way to extract long lists of objects or items from lengthy documents using large language models and retrieval techniques. Existing methods often struggle to recall all the items in a long list, but the researchers' approach, called a retrieval-augmented language model (RAM), aims to improve on this.
The key idea is to combine the power of large language models, which are trained on vast amounts of text data, with targeted retrieval of relevant information from the document. This allows the model to better understand the context and extract more complete object lists, rather than missing important items.
The researchers tested their RAM approach on several different datasets and found that it outperformed baseline models in terms of the recall, or completeness, of the extracted object lists. This suggests the technique could be valuable for applications like summarizing long documents or personalizing language models to individual users' needs.
Technical Explanation
The paper presents a retrieval-augmented language model (RAM) for improving the recall of long object list extraction from lengthy documents. The authors argue that existing approaches based solely on language models struggle to fully recall all the items in long lists, due to the challenges of maintaining context and relevance over extended text.
To address this, the RAM architecture combines a large language model with a retrieval component. First, the language model processes the input document to produce an initial object list extraction. Then, the retrieval module searches the document for additional relevant information to supplement the initial list. This allows the model to iteratively refine and expand the extracted object list, improving the overall recall.
The authors evaluate their RAM approach on several benchmark datasets for long object list extraction, including BioASQ, Law, and Longform QA. They compare the RAM model to strong baselines like GPT-3 and T5, as well as previous retrieval-augmented methods like Recall, Retrieve, Reason and LLM-Augmented Retrieval. The results demonstrate that the RAM approach significantly outperforms these baselines in terms of recall, while maintaining high precision.
Critical Analysis
The paper makes a compelling case for the benefits of retrieval-augmented language models for long object list extraction. The authors thoroughly evaluate their approach and provide strong empirical evidence of its effectiveness. However, a few aspects of the research could be explored further:
The paper does not delve deeply into the potential limitations or failure modes of the RAM approach. For example, it would be valuable to understand how the model behaves on particularly challenging or ambiguous documents, or whether there are any systematic biases in the types of object lists it struggles to recall.
Additionally, the authors focus primarily on improving recall, but do not examine the potential trade-offs in terms of efficiency or inference time. As recent research has highlighted, the computational demands of retrieval-augmented models can be a concern, and this aspect could merit further investigation.
Overall, the paper presents a promising new direction for enhancing the capabilities of large language models in long-form text understanding tasks. However, continued critical analysis and exploration of the approach's limitations and practical implications will be important for assessing its real-world applicability and impact.
Conclusion
The "Recall Them All" paper introduces a novel retrieval-augmented language model (RAM) that significantly improves the recall of long object list extraction from lengthy documents. By combining the strengths of large language models and targeted retrieval, the RAM approach is able to more comprehensively extract all the relevant items in a list, overcoming the limitations of existing methods.
The authors' extensive experiments demonstrate the effectiveness of their approach, which outperforms strong baselines across multiple benchmark datasets. This suggests the RAM technique could have valuable applications in areas like document summarization, information extraction, and personalized language models that need to precisely capture a user's interests and preferences.
While the paper provides a strong technical foundation, further research is needed to fully understand the approach's limitations and practical implications. Nonetheless, the "Recall Them All" work represents an important step forward in enhancing the capabilities of large language models for long-form text understanding and information retrieval.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Improving Recall of Large Language Models: A Model Collaboration Approach for Relational Triple Extraction
Zepeng Ding, Wenhao Huang, Jiaqing Liang, Deqing Yang, Yanghua Xiao
0
0
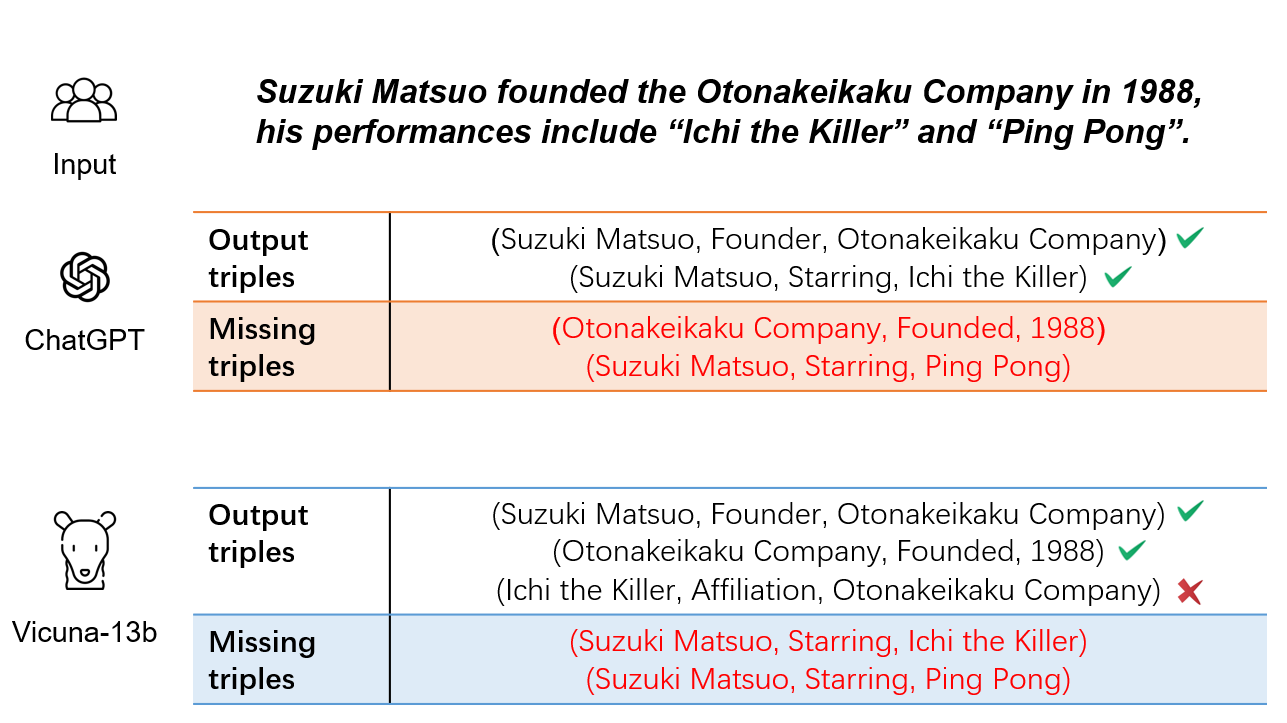
Relation triple extraction, which outputs a set of triples from long sentences, plays a vital role in knowledge acquisition. Large language models can accurately extract triples from simple sentences through few-shot learning or fine-tuning when given appropriate instructions. However, they often miss out when extracting from complex sentences. In this paper, we design an evaluation-filtering framework that integrates large language models with small models for relational triple extraction tasks. The framework includes an evaluation model that can extract related entity pairs with high precision. We propose a simple labeling principle and a deep neural network to build the model, embedding the outputs as prompts into the extraction process of the large model. We conduct extensive experiments to demonstrate that the proposed method can assist large language models in obtaining more accurate extraction results, especially from complex sentences containing multiple relational triples. Our evaluation model can also be embedded into traditional extraction models to enhance their extraction precision from complex sentences.
4/16/2024
Optimization Methods for Personalizing Large Language Models through Retrieval Augmentation
Alireza Salemi, Surya Kallumadi, Hamed Zamani
0
0
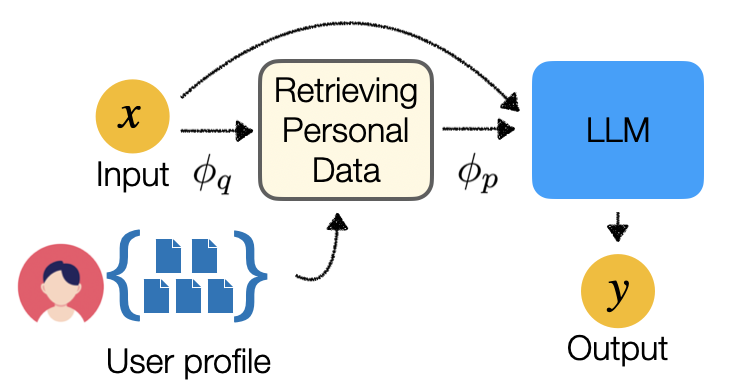
This paper studies retrieval-augmented approaches for personalizing large language models (LLMs), which potentially have a substantial impact on various applications and domains. We propose the first attempt to optimize the retrieval models that deliver a limited number of personal documents to large language models for the purpose of personalized generation. We develop two optimization algorithms that solicit feedback from the downstream personalized generation tasks for retrieval optimization--one based on reinforcement learning whose reward function is defined using any arbitrary metric for personalized generation and another based on knowledge distillation from the downstream LLM to the retrieval model. This paper also introduces a pre- and post-generation retriever selection model that decides what retriever to choose for each LLM input. Extensive experiments on diverse tasks from the language model personalization (LaMP) benchmark reveal statistically significant improvements in six out of seven datasets.
4/10/2024
Reminding Multimodal Large Language Models of Object-aware Knowledge with Retrieved Tags
Daiqing Qi, Handong Zhao, Zijun Wei, Sheng Li
0
0
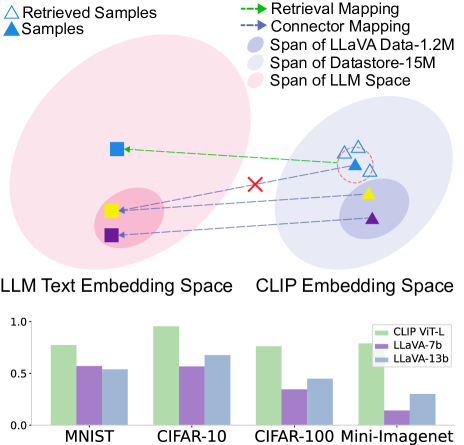
Despite recent advances in the general visual instruction-following ability of Multimodal Large Language Models (MLLMs), they still struggle with critical problems when required to provide a precise and detailed response to a visual instruction: (1) failure to identify novel objects or entities, (2) mention of non-existent objects, and (3) neglect of object's attributed details. Intuitive solutions include improving the size and quality of data or using larger foundation models. They show effectiveness in mitigating these issues, but at an expensive cost of collecting a vast amount of new data and introducing a significantly larger model. Standing at the intersection of these approaches, we examine the three object-oriented problems from the perspective of the image-to-text mapping process by the multimodal connector. In this paper, we first identify the limitations of multimodal connectors stemming from insufficient training data. Driven by this, we propose to enhance the mapping with retrieval-augmented tag tokens, which contain rich object-aware information such as object names and attributes. With our Tag-grounded visual instruction tuning with retrieval Augmentation (TUNA), we outperform baselines that share the same language model and training data on 12 benchmarks. Furthermore, we show the zero-shot capability of TUNA when provided with specific datastores.
6/18/2024
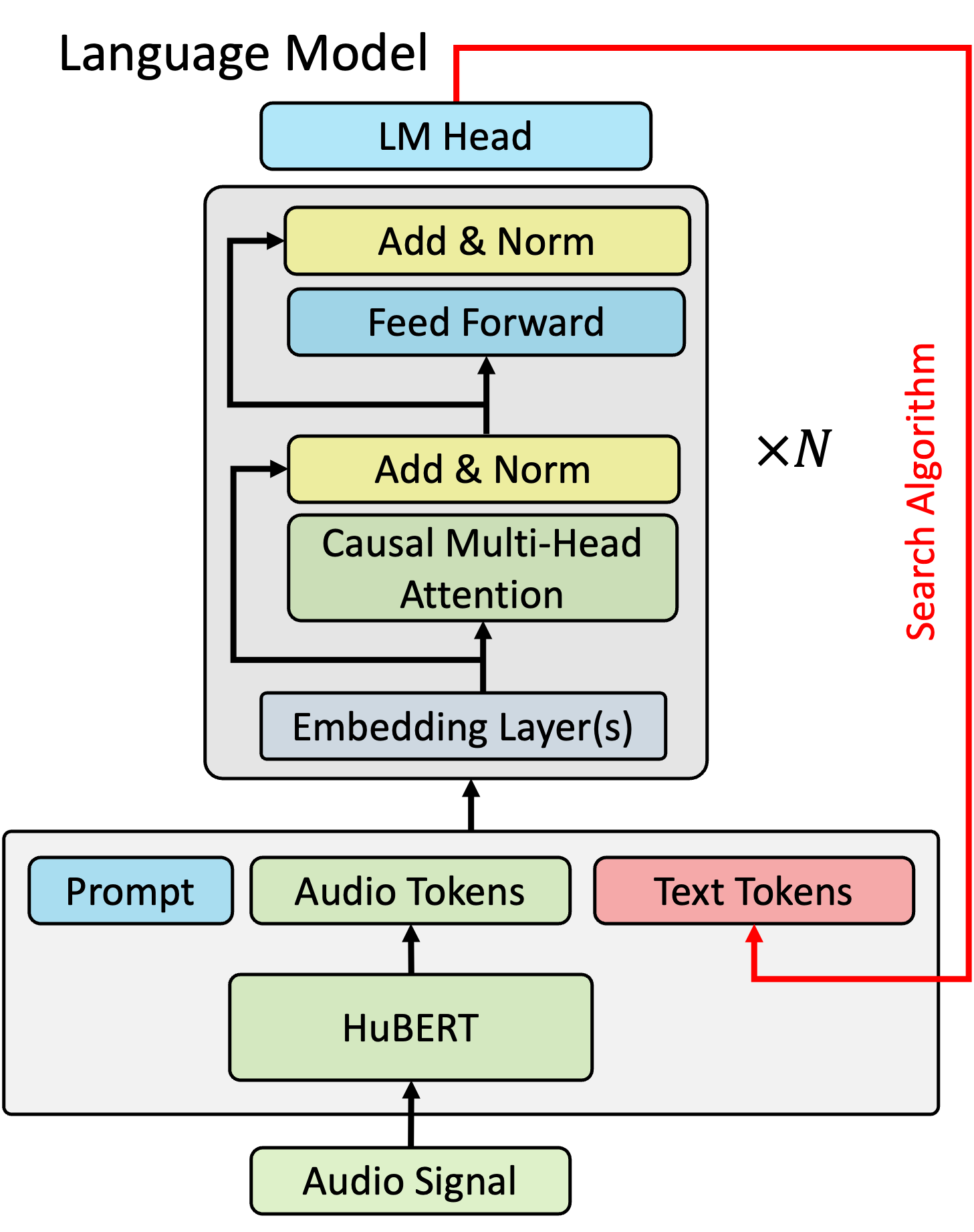
Multi-Modal Retrieval For Large Language Model Based Speech Recognition
Jari Kolehmainen, Aditya Gourav, Prashanth Gurunath Shivakumar, Yile Gu, Ankur Gandhe, Ariya Rastrow, Grant Strimel, Ivan Bulyko
0
0
Retrieval is a widely adopted approach for improving language models leveraging external information. As the field moves towards multi-modal large language models, it is important to extend the pure text based methods to incorporate other modalities in retrieval as well for applications across the wide spectrum of machine learning tasks and data types. In this work, we propose multi-modal retrieval with two approaches: kNN-LM and cross-attention techniques. We demonstrate the effectiveness of our retrieval approaches empirically by applying them to automatic speech recognition tasks with access to external information. Under this setting, we show that speech-based multi-modal retrieval outperforms text based retrieval, and yields up to 50 % improvement in word error rate over the multi-modal language model baseline. Furthermore, we achieve state-of-the-art recognition results on the Spoken-Squad question answering dataset.
6/17/2024