Boosting Reward Model with Preference-Conditional Multi-Aspect Synthetic Data Generation

0

Sign in to get full access
Overview
- This paper presents a method for boosting reward models by generating preference-conditional multi-aspect synthetic data.
- The goal is to improve the ability of reward models to capture complex human preferences.
- The approach uses generative models to create diverse synthetic critique examples tailored to specific preferences.
- These synthetic examples are used to fine-tune and expand the reward model, leading to better performance.
Plain English Explanation
The paper explores a way to make reward models better at understanding human preferences. Reward models are used in AI systems to evaluate how well the system is doing at achieving its goals. However, human preferences can be complex and nuanced, which can be difficult for reward models to capture.
The key idea is to generate synthetic examples that match specific preferences, and then use these examples to fine-tune and improve the reward model. The researchers use machine learning models to create these synthetic examples, tailoring them to different types of preferences.
By exposing the reward model to this diverse set of preference-conditional examples, the hope is that it will become better able to recognize and evaluate complex human preferences in real-world situations. This could lead to AI systems that are more aligned with human values and priorities.
Technical Explanation
The paper proposes a multi-aspect synthetic data generation approach to boost the performance of reward models. The key components are:
-
Preference Modeling: The researchers develop a preference modeling framework that captures different aspects of human preferences, such as aesthetics, safety, and ethics.
-
Synthetic Data Generation: Conditional generative models are used to create diverse synthetic examples that reflect specific preference profiles. This allows the generation of a large and diverse dataset of preference-conditioned examples.
-
Reward Model Fine-Tuning: The synthetic dataset is used to fine-tune and expand the reward model, with the goal of improving its ability to accurately capture complex human preferences.
The authors evaluate their approach on several benchmark tasks, including reward model benchmarking, and demonstrate significant performance improvements compared to baseline methods.
Critical Analysis
The paper presents a promising approach for boosting reward models and addressing the challenge of capturing complex human preferences. However, there are a few potential limitations and areas for further research:
-
Preference Modeling Complexity: The paper focuses on a limited set of preference aspects, and it's unclear how well the approach would scale to modeling more comprehensive and nuanced preference profiles.
-
Synthetic Data Quality: The quality and realism of the synthetic data generated by the conditional models could be a limiting factor, as unrealistic examples may not effectively transfer to improving the reward model.
-
Generalization to Real-World Scenarios: The evaluation is primarily done on benchmark tasks, and more research is needed to understand how well the approach would perform in real-world, high-stakes decision-making scenarios.
-
Potential Biases: The process of preference modeling and synthetic data generation could inadvertently introduce biases, which would need to be carefully studied and mitigated.
Overall, the paper presents an interesting and promising approach, but further research and validation would be needed to fully assess its practical implications and limitations.
Conclusion
This paper introduces a novel method for boosting reward models by generating preference-conditional synthetic data. The key idea is to use generative models to create diverse examples that capture different aspects of human preferences, and then use these examples to fine-tune and improve the reward model.
The researchers demonstrate promising results on benchmark tasks, suggesting that this approach could be a valuable tool for developing AI systems that better align with human values and preferences. However, further research is needed to address potential limitations and ensure the approach is robust and scalable to real-world scenarios.
Overall, this work represents an important step forward in the ongoing effort to create AI systems that are more attuned to the nuances of human decision-making and better serve the needs and priorities of society.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Boosting Reward Model with Preference-Conditional Multi-Aspect Synthetic Data Generation
Jiaming Shen, Ran Xu, Yennie Jun, Zhen Qin, Tianqi Liu, Carl Yang, Yi Liang, Simon Baumgartner, Michael Bendersky
Reward models (RMs) are crucial for aligning large language models (LLMs) with human preferences. They are trained using preference datasets where each example consists of one input prompt, two responses, and a preference label. As curating a high-quality human labeled preference dataset is both time-consuming and expensive, people often rely on existing powerful LLMs for preference label generation. This can potentially introduce noise and impede RM training. In this work, we present RMBoost, a novel synthetic preference data generation paradigm to boost reward model quality. Unlike traditional methods, which generate two responses before obtaining the preference label, RMBoost first generates one response and selects a preference label, followed by generating the second more (or less) preferred response conditioned on the pre-selected preference label and the first response. This approach offers two main advantages. First, RMBoost reduces labeling noise since preference pairs are constructed intentionally. Second, RMBoost facilitates the creation of more diverse responses by incorporating various quality aspects (e.g., helpfulness, relevance, completeness) into the prompts. We conduct extensive experiments across three diverse datasets and demonstrate that RMBoost outperforms other synthetic preference data generation techniques and significantly boosts the performance of four distinct reward models.
Read more7/24/2024
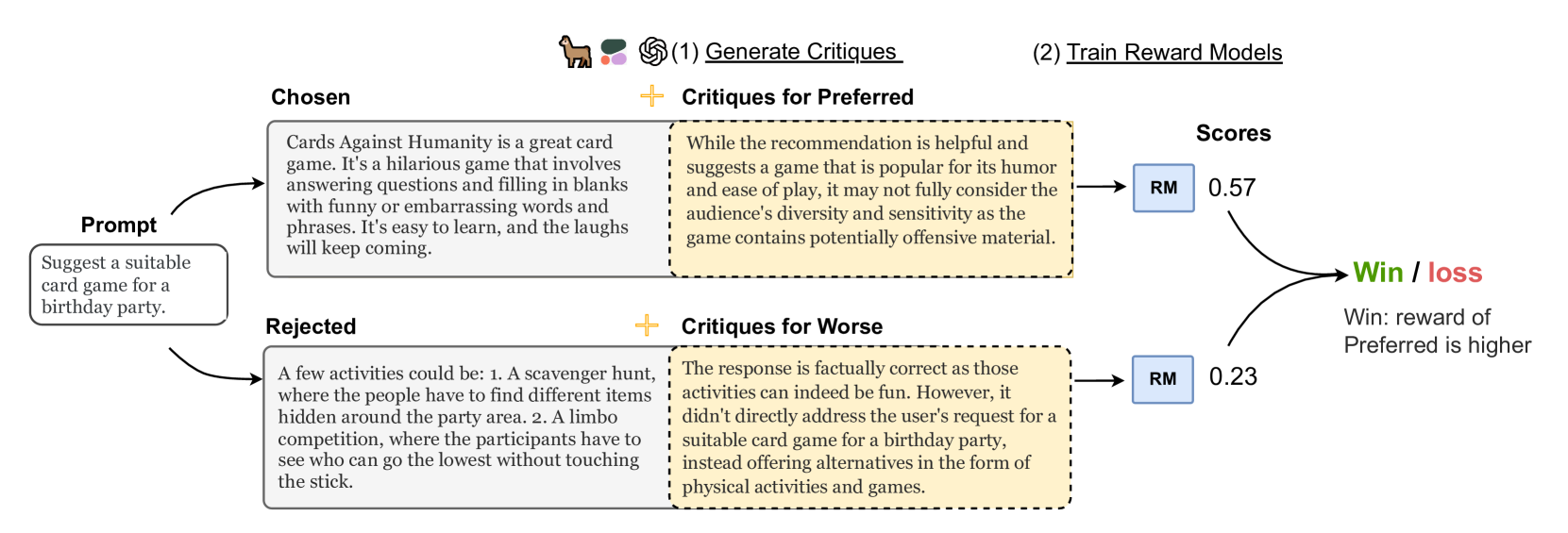
0
Improving Reward Models with Synthetic Critiques
Zihuiwen Ye, Fraser Greenlee-Scott, Max Bartolo, Phil Blunsom, Jon Ander Campos, Matthias Gall'e
Reward models (RM) play a critical role in aligning language models through the process of reinforcement learning from human feedback. RMs are trained to predict a score reflecting human preference, which requires significant time and cost for human annotation. Additionally, RMs tend to quickly overfit on superficial features in the training set, hindering their generalization performance on unseen distributions. We propose a novel approach using synthetic natural language critiques generated by large language models to provide additional feedback, evaluating aspects such as instruction following, correctness, and style. This offers richer signals and more robust features for RMs to assess and score on. We demonstrate that high-quality critiques improve the performance and data efficiency of RMs initialized from different pretrained models. Conversely, we also show that low-quality critiques negatively impact performance. Furthermore, incorporating critiques enhances the interpretability and robustness of RM training.
Read more6/3/2024

0
Towards Comprehensive Preference Data Collection for Reward Modeling
Yulan Hu, Qingyang Li, Sheng Ouyang, Ge Chen, Kaihui Chen, Lijun Mei, Xucheng Ye, Fuzheng Zhang, Yong Liu
Reinforcement Learning from Human Feedback (RLHF) facilitates the alignment of large language models (LLMs) with human preferences, thereby enhancing the quality of responses generated. A critical component of RLHF is the reward model, which is trained on preference data and outputs a scalar reward during the inference stage. However, the collection of preference data still lacks thorough investigation. Recent studies indicate that preference data is collected either by AI or humans, where chosen and rejected instances are identified among pairwise responses. We question whether this process effectively filters out noise and ensures sufficient diversity in collected data. To address these concerns, for the first time, we propose a comprehensive framework for preference data collection, decomposing the process into four incremental steps: Prompt Generation, Response Generation, Response Filtering, and Human Labeling. This structured approach ensures the collection of high-quality preferences while reducing reliance on human labor. We conducted comprehensive experiments based on the data collected at different stages, demonstrating the effectiveness of the proposed data collection method.
Read more6/26/2024
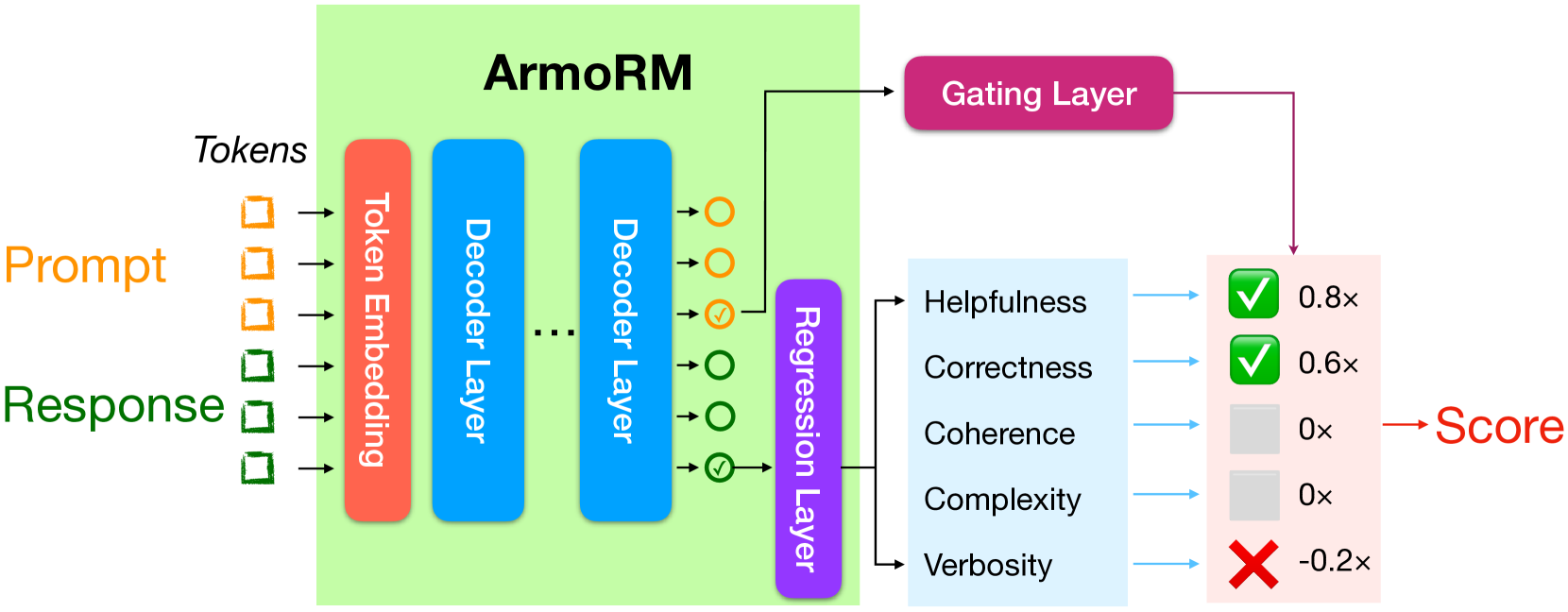
0
Interpretable Preferences via Multi-Objective Reward Modeling and Mixture-of-Experts
Haoxiang Wang, Wei Xiong, Tengyang Xie, Han Zhao, Tong Zhang
Reinforcement learning from human feedback (RLHF) has emerged as the primary method for aligning large language models (LLMs) with human preferences. The RLHF process typically starts by training a reward model (RM) using human preference data. Conventional RMs are trained on pairwise responses to the same user request, with relative ratings indicating which response humans prefer. The trained RM serves as a proxy for human preferences. However, due to the black-box nature of RMs, their outputs lack interpretability, as humans cannot intuitively understand why an RM thinks a response is good or not. As RMs act as human preference proxies, we believe they should be human-interpretable to ensure that their internal decision processes are consistent with human preferences and to prevent reward hacking in LLM alignment. To build RMs with interpretable preferences, we propose a two-stage approach: i) train an Absolute-Rating Multi-Objective Reward Model (ArmoRM) with multi-dimensional absolute-rating data, each dimension corresponding to a human-interpretable objective (e.g., honesty, verbosity, safety); ii) employ a Mixture-of-Experts (MoE) strategy with a gating network that automatically selects the most suitable reward objectives based on the context. We efficiently trained an ArmoRM with Llama-3 8B and a gating network consisting of a shallow MLP on top of the ArmoRM. Our trained model, ArmoRM-Llama3-8B, obtains state-of-the-art performance on RewardBench, a benchmark evaluating RMs for language modeling. Notably, the performance of our model surpasses the LLM-as-a-judge method with GPT-4 judges by a margin, and approaches the performance of the much larger Nemotron-4 340B reward model.
Read more6/19/2024