Privacy Preserving Data Imputation via Multi-party Computation for Medical Applications
2405.18878
0
0
Abstract
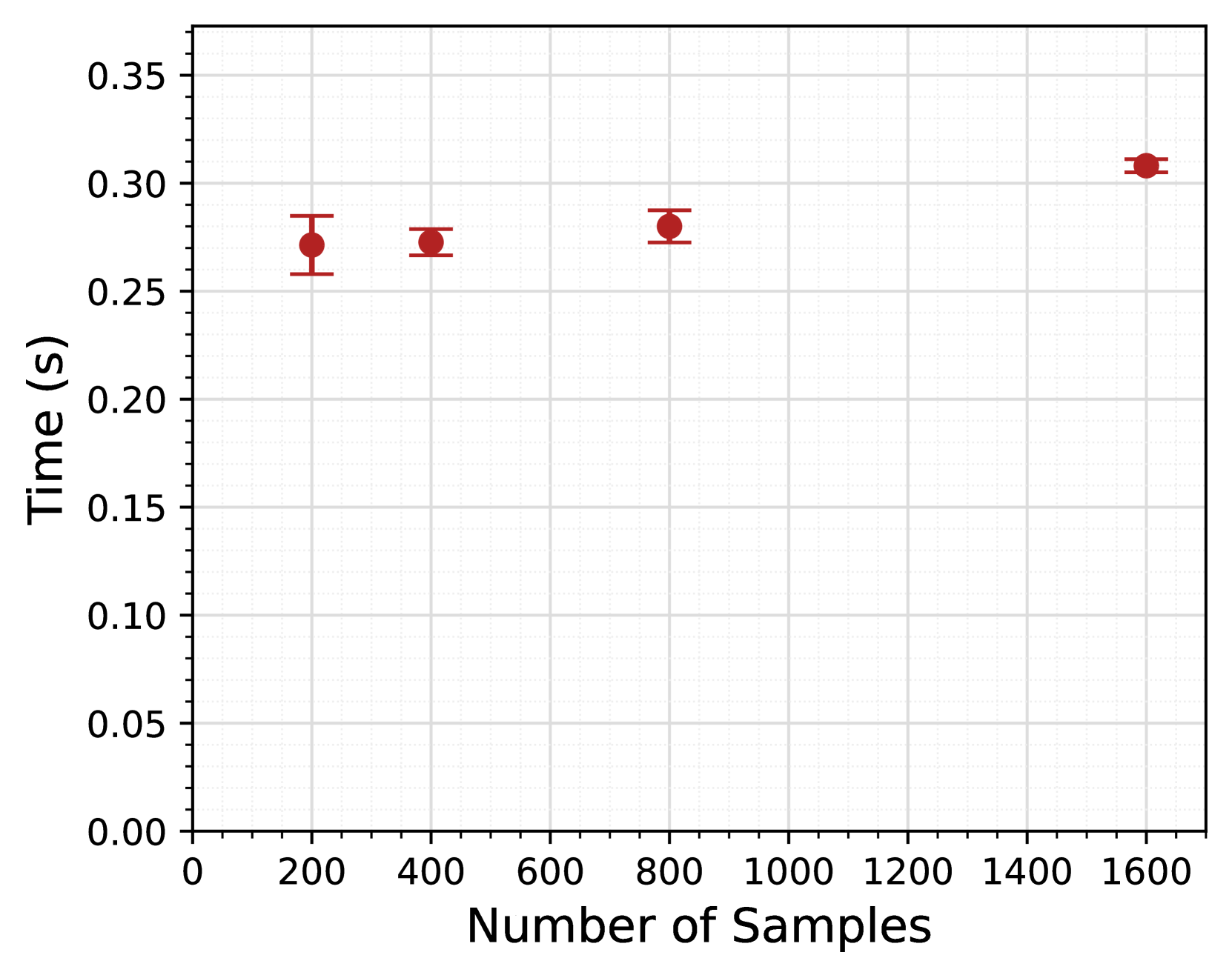
Handling missing data is crucial in machine learning, but many datasets contain gaps due to errors or non-response. Unlike traditional methods such as listwise deletion, which are simple but inadequate, the literature offers more sophisticated and effective methods, thereby improving sample size and accuracy. However, these methods require accessing the whole dataset, which contradicts the privacy regulations when the data is distributed among multiple sources. Especially in the medical and healthcare domain, such access reveals sensitive information about patients. This study addresses privacy-preserving imputation methods for sensitive data using secure multi-party computation, enabling secure computations without revealing any party's sensitive information. In this study, we realized the mean, median, regression, and kNN imputation methods in a privacy-preserving way. We specifically target the medical and healthcare domains considering the significance of protection of the patient data, showcasing our methods on a diabetes dataset. Experiments on the diabetes dataset validated the correctness of our privacy-preserving imputation methods, yielding the largest error around $3 times 10^{-3}$, closely matching plaintext methods. We also analyzed the scalability of our methods to varying numbers of samples, showing their applicability to real-world healthcare problems. Our analysis demonstrated that all our methods scale linearly with the number of samples. Except for kNN, the runtime of all our methods indicates that they can be utilized for large datasets.
Create account to get full access
Overview
- This paper proposes a privacy-preserving data imputation method using multi-party computation (MPC) for medical applications.
- The goal is to enable data imputation while preserving the privacy of sensitive medical data.
- The authors develop a secure MPC protocol for data imputation and evaluate its performance on real-world medical datasets.
Plain English Explanation
Medical data is often incomplete, with missing values that need to be filled in (imputed) for analysis. However, medical data is highly sensitive, and traditional data imputation approaches may compromise patient privacy.
To address this, the researchers have developed a new technique that allows data imputation to be done in a privacy-preserving way using multi-party computation (MPC). MPC is a cryptographic technique that enables multiple parties to jointly compute a function over their private inputs without revealing those inputs to each other.
In this case, the MPC protocol allows the medical data to be imputed without any party (e.g., a hospital, research lab, etc.) seeing the complete, unencrypted data. The imputed data can then be used for medical research or other applications while still protecting patient privacy.
The researchers tested their MPC-based imputation approach on real-world medical datasets and found that it performed well, producing imputed data that was nearly as accurate as traditional imputation methods, but with the key advantage of preserving patient privacy.
Technical Explanation
The paper first provides background on data imputation and the privacy challenges in medical applications. It then introduces the concept of multi-party computation (MPC) and how it can be leveraged for privacy-preserving data imputation.
The authors propose a secure MPC protocol for data imputation. In this protocol, the medical data is distributed across multiple parties, each holding a portion of the data. The parties then collaboratively perform the imputation computations using MPC techniques, without any party ever seeing the complete, unencrypted dataset.
The key steps of the MPC-based imputation protocol are:
- Data preprocessing and encoding
- Secure computation of imputation statistics
- Secure data imputation
- Aggregation of imputed data
The authors evaluate their MPC-based imputation approach on several real-world medical datasets, comparing its performance to traditional imputation methods in terms of imputation accuracy, computational cost, and communication overhead.
The results show that the MPC-based approach achieves imputation accuracy comparable to non-private methods, while providing strong privacy guarantees by preventing any party from accessing the complete, unencrypted dataset.
Critical Analysis
The paper provides a novel and promising approach to addressing the tension between data utility and privacy in medical applications. By leveraging MPC, the proposed technique allows for effective data imputation without compromising patient confidentiality.
One potential limitation is the computational and communication overhead associated with the MPC protocol, which could limit its scalability for very large datasets. The authors note that further optimizations may be needed to improve the efficiency of the approach.
Additionally, the paper does not explore the robustness of the MPC-based imputation to adversarial attacks or the potential for information leakage through the imputed data. These are important considerations that could be addressed in future research.
Conclusion
This paper presents a privacy-preserving data imputation method using multi-party computation for medical applications. By distributing the data and performing the imputation computations securely, the approach enables effective data imputation while preserving patient privacy.
The results demonstrate the feasibility and potential of this MPC-based approach, opening up new possibilities for medical research and analysis that can harness the value of data without compromising individual privacy. Further research is needed to address the challenges of scalability and security, but this work represents an important step forward in the quest for privacy-preserving data solutions.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🛠️
Multilevel Stochastic Optimization for Imputation in Massive Medical Data Records
Wenrui Li, Xiaoyu Wang, Yuetian Sun, Snezana Milanovic, Mark Kon, Julio Enrique Castrillon-Candas
0
0
It has long been a recognized problem that many datasets contain significant levels of missing numerical data. A potentially critical predicate for application of machine learning methods to datasets involves addressing this problem. However, this is a challenging task. In this paper, we apply a recently developed multi-level stochastic optimization approach to the problem of imputation in massive medical records. The approach is based on computational applied mathematics techniques and is highly accurate. In particular, for the Best Linear Unbiased Predictor (BLUP) this multi-level formulation is exact, and is significantly faster and more numerically stable. This permits practical application of Kriging methods to data imputation problems for massive datasets. We test this approach on data from the National Inpatient Sample (NIS) data records, Healthcare Cost and Utilization Project (HCUP), Agency for Healthcare Research and Quality. Numerical results show that the multi-level method significantly outperforms current approaches and is numerically robust. It has superior accuracy as compared with methods recommended in the recent report from HCUP. Benchmark tests show up to 75% reductions in error. Furthermore, the results are also superior to recent state of the art methods such as discriminative deep learning.
4/4/2024
🤯
Resampling methods for Private Statistical Inference
Karan Chadha, John Duchi, Rohith Kuditipudi
0
0
We consider the task of constructing confidence intervals with differential privacy. We propose two private variants of the non-parametric bootstrap, which privately compute the median of the results of multiple little bootstraps run on partitions of the data and give asymptotic bounds on the coverage error of the resulting confidence intervals. For a fixed differential privacy parameter $epsilon$, our methods enjoy the same error rates as that of the non-private bootstrap to within logarithmic factors in the sample size $n$. We empirically validate the performance of our methods for mean estimation, median estimation, and logistic regression with both real and synthetic data. Our methods achieve similar coverage accuracy to existing methods (and non-private baselines) while providing notably shorter ($gtrsim 10$ times) confidence intervals than previous approaches.
6/5/2024
📊
Data Imputation by Pursuing Better Classification: A Supervised Kernel-Based Method
Ruikai Yang, Fan He, Mingzhen He, Kaijie Wang, Xiaolin Huang
0
0
Data imputation, the process of filling in missing feature elements for incomplete data sets, plays a crucial role in data-driven learning. A fundamental belief is that data imputation is helpful for learning performance, and it follows that the pursuit of better classification can guide the data imputation process. While some works consider using label information to assist in this task, their simplistic utilization of labels lacks flexibility and may rely on strict assumptions. In this paper, we propose a new framework that effectively leverages supervision information to complete missing data in a manner conducive to classification. Specifically, this framework operates in two stages. Firstly, it leverages labels to supervise the optimization of similarity relationships among data, represented by the kernel matrix, with the goal of enhancing classification accuracy. To mitigate overfitting that may occur during this process, a perturbation variable is introduced to improve the robustness of the framework. Secondly, the learned kernel matrix serves as additional supervision information to guide data imputation through regression, utilizing the block coordinate descent method. The superiority of the proposed method is evaluated on four real-world data sets by comparing it with state-of-the-art imputation methods. Remarkably, our algorithm significantly outperforms other methods when the data is missing more than 60% of the features
5/14/2024
📊
Imputation of missing values in multi-view data
Wouter van Loon, Marjolein Fokkema, Frank de Vos, Marisa Koini, Reinhold Schmidt, Mark de Rooij
0
0
Data for which a set of objects is described by multiple distinct feature sets (called views) is known as multi-view data. When missing values occur in multi-view data, all features in a view are likely to be missing simultaneously. This may lead to very large quantities of missing data which, especially when combined with high-dimensionality, can make the application of conditional imputation methods computationally infeasible. However, the multi-view structure could be leveraged to reduce the complexity and computational load of imputation. We introduce a new imputation method based on the existing stacked penalized logistic regression (StaPLR) algorithm for multi-view learning. It performs imputation in a dimension-reduced space to address computational challenges inherent to the multi-view context. We compare the performance of the new imputation method with several existing imputation algorithms in simulated data sets and a real data application. The results show that the new imputation method leads to competitive results at a much lower computational cost, and makes the use of advanced imputation algorithms such as missForest and predictive mean matching possible in settings where they would otherwise be computationally infeasible.
6/21/2024