Multilevel Stochastic Optimization for Imputation in Massive Medical Data Records
2110.09680
0
0
🛠️
Abstract
It has long been a recognized problem that many datasets contain significant levels of missing numerical data. A potentially critical predicate for application of machine learning methods to datasets involves addressing this problem. However, this is a challenging task. In this paper, we apply a recently developed multi-level stochastic optimization approach to the problem of imputation in massive medical records. The approach is based on computational applied mathematics techniques and is highly accurate. In particular, for the Best Linear Unbiased Predictor (BLUP) this multi-level formulation is exact, and is significantly faster and more numerically stable. This permits practical application of Kriging methods to data imputation problems for massive datasets. We test this approach on data from the National Inpatient Sample (NIS) data records, Healthcare Cost and Utilization Project (HCUP), Agency for Healthcare Research and Quality. Numerical results show that the multi-level method significantly outperforms current approaches and is numerically robust. It has superior accuracy as compared with methods recommended in the recent report from HCUP. Benchmark tests show up to 75% reductions in error. Furthermore, the results are also superior to recent state of the art methods such as discriminative deep learning.
Create account to get full access
Overview
- Many datasets have significant amounts of missing numerical data, which is a challenge for applying machine learning methods.
- The paper presents a new approach to addressing this problem of data imputation (filling in missing values) using a multi-level stochastic optimization technique.
- The approach is highly accurate and efficient, significantly outperforming current methods in terms of error reduction.
Plain English Explanation
Missing data is a common problem when working with real-world datasets, especially large datasets like medical records. Machine learning models need complete data to make accurate predictions, so filling in or "imputing" these missing values is an important step.
The researchers developed a new mathematical technique to impute missing data that is both very precise and computationally efficient. It works by breaking down the problem into multiple levels, allowing the imputation to be calculated quickly and accurately.
When the researchers tested this method on a large dataset of hospital records, they found it significantly outperformed other recommended approaches. It reduced errors in the imputed data by up to 75% compared to current methods. The new technique was also better than using advanced deep learning models for this task.
Technical Explanation
The paper applies a multi-level stochastic optimization approach to the problem of data imputation. This technique is based on computational applied mathematics and provides a highly accurate solution, particularly for the Best Linear Unbiased Predictor (BLUP) method.
The multi-level formulation is exact for BLUP, and it is also much faster and more numerically stable than previous approaches. This allows Kriging methods, a powerful class of statistical models, to be practically applied to large-scale data imputation problems.
The researchers tested this new imputation method on data from the National Inpatient Sample (NIS), a large medical records database. The results show the multi-level approach significantly outperforms current recommended techniques, with benchmark tests demonstrating up to 75% reductions in error. The method also outperforms recent state-of-the-art deep learning approaches for data imputation.
Critical Analysis
The paper provides a thorough evaluation of the new imputation method and compares it extensively to other techniques. However, it does not delve into potential limitations or caveats of the approach.
For example, the method assumes the data is missing at random, which may not always be the case in real-world datasets. Additionally, the computational efficiency gains may diminish for extremely large datasets that don't fit in memory.
Further research could explore the robustness of the method to different types of missing data patterns, as well as its scalability to truly massive datasets. Comparisons to a wider range of imputation techniques, including more advanced deep learning models, would also help establish the broader applicability of this approach.
Conclusion
This paper presents a highly effective new technique for imputing missing numerical data in large datasets. The multi-level stochastic optimization approach is shown to significantly outperform current recommended methods in terms of accuracy, with benchmark improvements of up to 75%.
The efficiency and numerical stability of this new imputation method opens the door for practical application of advanced statistical modeling techniques to real-world problems involving incomplete data. This could have important implications for fields like healthcare, where making the best use of large datasets is crucial for driving insights and improving outcomes.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Privacy Preserving Data Imputation via Multi-party Computation for Medical Applications
Julia Jentsch, Ali Burak Unal, c{S}eyma Selcan Mau{g}ara, Mete Akgun
0
0
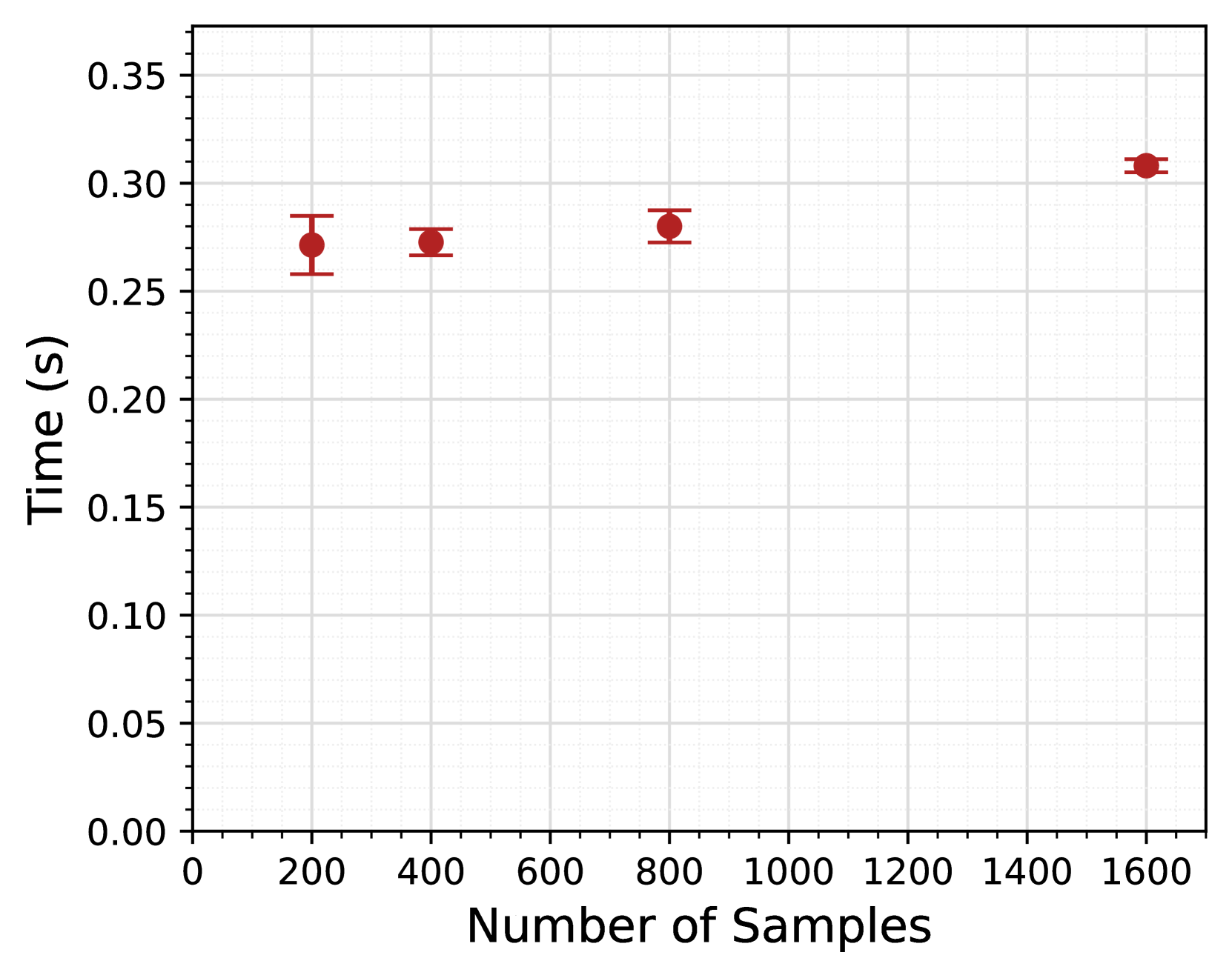
Handling missing data is crucial in machine learning, but many datasets contain gaps due to errors or non-response. Unlike traditional methods such as listwise deletion, which are simple but inadequate, the literature offers more sophisticated and effective methods, thereby improving sample size and accuracy. However, these methods require accessing the whole dataset, which contradicts the privacy regulations when the data is distributed among multiple sources. Especially in the medical and healthcare domain, such access reveals sensitive information about patients. This study addresses privacy-preserving imputation methods for sensitive data using secure multi-party computation, enabling secure computations without revealing any party's sensitive information. In this study, we realized the mean, median, regression, and kNN imputation methods in a privacy-preserving way. We specifically target the medical and healthcare domains considering the significance of protection of the patient data, showcasing our methods on a diabetes dataset. Experiments on the diabetes dataset validated the correctness of our privacy-preserving imputation methods, yielding the largest error around $3 times 10^{-3}$, closely matching plaintext methods. We also analyzed the scalability of our methods to varying numbers of samples, showing their applicability to real-world healthcare problems. Our analysis demonstrated that all our methods scale linearly with the number of samples. Except for kNN, the runtime of all our methods indicates that they can be utilized for large datasets.
5/30/2024
📊
Imputation of missing values in multi-view data
Wouter van Loon, Marjolein Fokkema, Frank de Vos, Marisa Koini, Reinhold Schmidt, Mark de Rooij
0
0
Data for which a set of objects is described by multiple distinct feature sets (called views) is known as multi-view data. When missing values occur in multi-view data, all features in a view are likely to be missing simultaneously. This may lead to very large quantities of missing data which, especially when combined with high-dimensionality, can make the application of conditional imputation methods computationally infeasible. However, the multi-view structure could be leveraged to reduce the complexity and computational load of imputation. We introduce a new imputation method based on the existing stacked penalized logistic regression (StaPLR) algorithm for multi-view learning. It performs imputation in a dimension-reduced space to address computational challenges inherent to the multi-view context. We compare the performance of the new imputation method with several existing imputation algorithms in simulated data sets and a real data application. The results show that the new imputation method leads to competitive results at a much lower computational cost, and makes the use of advanced imputation algorithms such as missForest and predictive mean matching possible in settings where they would otherwise be computationally infeasible.
6/21/2024
📊
Data Imputation by Pursuing Better Classification: A Supervised Kernel-Based Method
Ruikai Yang, Fan He, Mingzhen He, Kaijie Wang, Xiaolin Huang
0
0
Data imputation, the process of filling in missing feature elements for incomplete data sets, plays a crucial role in data-driven learning. A fundamental belief is that data imputation is helpful for learning performance, and it follows that the pursuit of better classification can guide the data imputation process. While some works consider using label information to assist in this task, their simplistic utilization of labels lacks flexibility and may rely on strict assumptions. In this paper, we propose a new framework that effectively leverages supervision information to complete missing data in a manner conducive to classification. Specifically, this framework operates in two stages. Firstly, it leverages labels to supervise the optimization of similarity relationships among data, represented by the kernel matrix, with the goal of enhancing classification accuracy. To mitigate overfitting that may occur during this process, a perturbation variable is introduced to improve the robustness of the framework. Secondly, the learned kernel matrix serves as additional supervision information to guide data imputation through regression, utilizing the block coordinate descent method. The superiority of the proposed method is evaluated on four real-world data sets by comparing it with state-of-the-art imputation methods. Remarkably, our algorithm significantly outperforms other methods when the data is missing more than 60% of the features
5/14/2024
Rethinking the Diffusion Models for Numerical Tabular Data Imputation from the Perspective of Wasserstein Gradient Flow
Zhichao Chen, Haoxuan Li, Fangyikang Wang, Odin Zhang, Hu Xu, Xiaoyu Jiang, Zhihuan Song, Eric H. Wang
0
0
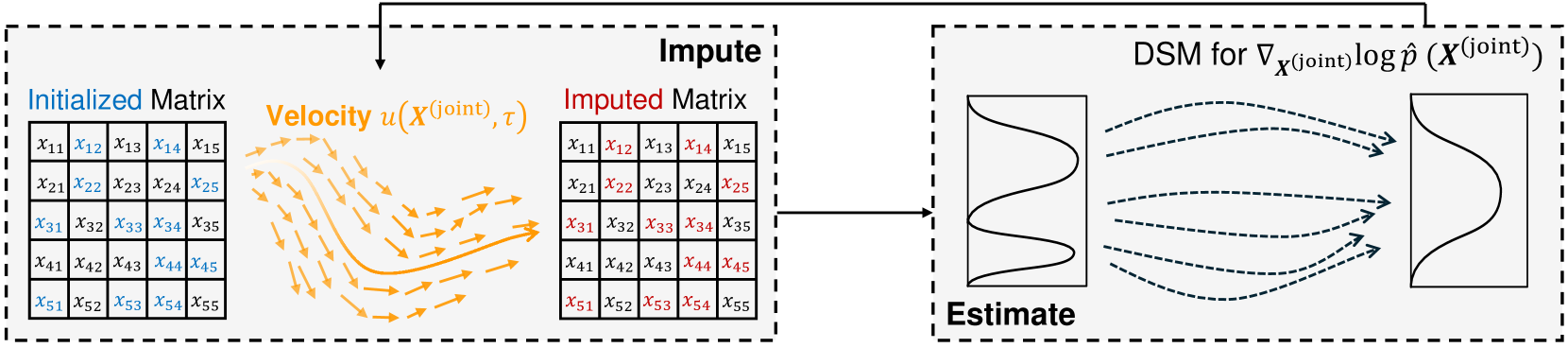
Diffusion models (DMs) have gained attention in Missing Data Imputation (MDI), but there remain two long-neglected issues to be addressed: (1). Inaccurate Imputation, which arises from inherently sample-diversification-pursuing generative process of DMs. (2). Difficult Training, which stems from intricate design required for the mask matrix in model training stage. To address these concerns within the realm of numerical tabular datasets, we introduce a novel principled approach termed Kernelized Negative Entropy-regularized Wasserstein gradient flow Imputation (KnewImp). Specifically, based on Wasserstein gradient flow (WGF) framework, we first prove that issue (1) stems from the cost functionals implicitly maximized in DM-based MDI are equivalent to the MDI's objective plus diversification-promoting non-negative terms. Based on this, we then design a novel cost functional with diversification-discouraging negative entropy and derive our KnewImp approach within WGF framework and reproducing kernel Hilbert space. After that, we prove that the imputation procedure of KnewImp can be derived from another cost functional related to the joint distribution, eliminating the need for the mask matrix and hence naturally addressing issue (2). Extensive experiments demonstrate that our proposed KnewImp approach significantly outperforms existing state-of-the-art methods.
6/26/2024