Imputation for prediction: beware of diminishing returns

0
🔗
Sign in to get full access
Overview
- Missing values are common in various fields, which can create challenges for training and deploying predictive models.
- Imputation, the process of filling in missing values, is a common practice to address this issue, with the hope of improving prediction accuracy.
- Recent studies suggest that simple constant imputation can be effective, raising questions about the benefits of advanced imputation methods.
Plain English Explanation
Missing data is a common problem in many areas, such as healthcare, finance, and scientific research. When data has missing values, it can be difficult to train accurate predictive models that can make reliable predictions.
To address this, researchers often use a technique called imputation to fill in the missing values. The idea is that by having a complete dataset, the predictive model will be able to learn better and make more accurate predictions.
However, recent studies have shown that sometimes a simple approach, like just filling in the missing values with a constant number, can work just as well as more complex imputation methods. This raises the question of whether investing time and resources in developing advanced imputation techniques is really worth it if it doesn't significantly improve the final predictions.
Technical Explanation
This empirical study investigates whether investing in advanced imputation methods leads to significantly better predictions. The researchers examined the relationship between imputation accuracy and predictive performance across various combinations of imputation and predictive models on 20 different datasets.
The key findings are:
-
Expressive models: When using more powerful predictive models, the impact of imputation accuracy on prediction performance is reduced.
-
Missingness indicators: Incorporating missingness indicators as complementary inputs to the predictive model can help mitigate the importance of imputation accuracy.
-
Linear vs. real-world outcomes: Imputation accuracy matters much more for predicting linear outcomes than for real-world, non-linear outcomes.
Interestingly, the researchers also found that using missingness indicators can improve prediction performance, even in scenarios where the missing values are completely random (MCAR).
Critical Analysis
The study provides valuable insights into the relationship between imputation accuracy and predictive performance. The researchers acknowledge that the findings may be specific to the datasets and models used in the experiments, and further research is needed to generalize the conclusions.
One potential limitation is that the study focuses on overall predictive performance and does not delve into the impact of imputation on specific use cases or decision-making scenarios. It would be interesting to explore how imputation accuracy affects the reliability and trustworthiness of predictive models in real-world applications.
Additionally, the study does not address the potential trade-offs between imputation accuracy and computational complexity or model interpretability. In some applications, simpler imputation methods may be preferable if they can provide a reasonable balance between prediction performance and other important factors.
Conclusion
This study suggests that, in many real-world scenarios, investing significant resources in developing advanced imputation methods may not always lead to substantial improvements in predictive performance, especially when using powerful predictive models and incorporating missingness indicators.
The findings challenge the common assumption that more accurate imputation will necessarily result in better predictions. Instead, they highlight the importance of carefully evaluating the potential benefits of imputation in the context of the specific problem and the available modeling techniques.
These insights can help researchers and practitioners make more informed decisions about their approach to handling missing data and optimizing their predictive models for real-world applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🔗
0
Imputation for prediction: beware of diminishing returns
Marine Le Morvan (SODA), Gael Varoquaux
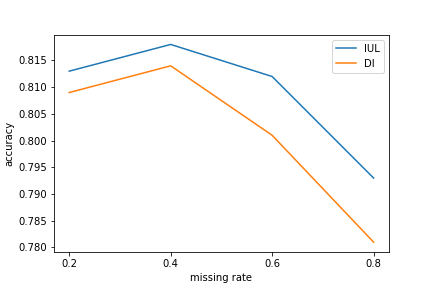
Missing values are prevalent across various fields, posing challenges for training and deploying predictive models. In this context, imputation is a common practice, driven by the hope that accurate imputations will enhance predictions. However, recent theoretical and empirical studies indicate that simple constant imputation can be consistent and competitive. This empirical study aims at clarifying if and when investing in advanced imputation methods yields significantly better predictions. Relating imputation and predictive accuracies across combinations of imputation and predictive models on 20 datasets, we show that imputation accuracy matters less i) when using expressive models, ii) when incorporating missingness indicators as complementary inputs, iii) matters much more for generated linear outcomes than for real-data outcomes. Interestingly, we also show that the use of the missingness indicator is beneficial to the prediction performance, even in MCAR scenarios. Overall, on real-data with powerful models, improving imputation only has a minor effect on prediction performance. Thus, investing in better imputations for improved predictions often offers limited benefits.
Read more7/30/2024
0
Imputation using training labels and classification via label imputation
Thu Nguyen, Tuan L. Vo, P{aa}l Halvorsen, Michael A. Riegler
Missing data is a common problem in practical settings. Various imputation methods have been developed to deal with missing data. However, even though the label is usually available in the training data, the common practice of imputation usually only relies on the input and ignores the label. In this work, we illustrate how stacking the label into the input can significantly improve the imputation of the input. In addition, we propose a classification strategy that initializes the predicted test label with missing values and stacks the label with the input for imputation. This allows imputing the label and the input at the same time. Also, the technique is capable of handling data training with missing labels without any prior imputation and is applicable to continuous, categorical, or mixed-type data. Experiments show promising results in terms of accuracy.
Read more4/24/2024

0
Explainability of Machine Learning Models under Missing Data
Tuan L. Vo, Thu Nguyen, Hugo L. Hammer, Michael A. Riegler, Pal Halvorsen
Missing data is a prevalent issue that can significantly impair model performance and interpretability. This paper briefly summarizes the development of the field of missing data with respect to Explainable Artificial Intelligence and experimentally investigates the effects of various imputation methods on the calculation of Shapley values, a popular technique for interpreting complex machine learning models. We compare different imputation strategies and assess their impact on feature importance and interaction as determined by Shapley values. Moreover, we also theoretically analyze the effects of missing values on Shapley values. Importantly, our findings reveal that the choice of imputation method can introduce biases that could lead to changes in the Shapley values, thereby affecting the interpretability of the model. Moreover, and that a lower test prediction mean square error (MSE) may not imply a lower MSE in Shapley values and vice versa. Also, while Xgboost is a method that could handle missing data directly, using Xgboost directly on missing data can seriously affect interpretability compared to imputing the data before training Xgboost. This study provides a comprehensive evaluation of imputation methods in the context of model interpretation, offering practical guidance for selecting appropriate techniques based on dataset characteristics and analysis objectives. The results underscore the importance of considering imputation effects to ensure robust and reliable insights from machine learning models.
Read more7/2/2024
0
Robust prediction under missingness shifts
Patrick Rockenschaub, Zhicong Xian, Alireza Zamanian, Marta Piperno, Octavia-Andreea Ciora, Elisabeth Pachl, Narges Ahmidi
Prediction becomes more challenging with missing covariates. What method is chosen to handle missingness can greatly affect how models perform. In many real-world problems, the best prediction performance is achieved by models that can leverage the informative nature of a value being missing. Yet, the reasons why a covariate goes missing can change once a model is deployed in practice. If such a missingness shift occurs, the conditional probability of a value being missing differs in the target data. Prediction performance in the source data may no longer be a good selection criterion, and approaches that do not rely on informative missingness may be preferable. However, we show that the Bayes predictor remains unchanged by ignorable shifts for which the probability of missingness only depends on observed data. Any consistent estimator of the Bayes predictor may therefore result in robust prediction under those conditions, although we show empirically that different methods appear robust to different types of shifts. If the missingness shift is non-ignorable, the Bayes predictor may change due to the shift. While neither approach recovers the Bayes predictor in this case, we found empirically that disregarding missingness was most beneficial when it was highly informative.
Read more6/26/2024