Data Imputation by Pursuing Better Classification: A Supervised Kernel-Based Method
2405.07800
0
0
📊
Abstract
Data imputation, the process of filling in missing feature elements for incomplete data sets, plays a crucial role in data-driven learning. A fundamental belief is that data imputation is helpful for learning performance, and it follows that the pursuit of better classification can guide the data imputation process. While some works consider using label information to assist in this task, their simplistic utilization of labels lacks flexibility and may rely on strict assumptions. In this paper, we propose a new framework that effectively leverages supervision information to complete missing data in a manner conducive to classification. Specifically, this framework operates in two stages. Firstly, it leverages labels to supervise the optimization of similarity relationships among data, represented by the kernel matrix, with the goal of enhancing classification accuracy. To mitigate overfitting that may occur during this process, a perturbation variable is introduced to improve the robustness of the framework. Secondly, the learned kernel matrix serves as additional supervision information to guide data imputation through regression, utilizing the block coordinate descent method. The superiority of the proposed method is evaluated on four real-world data sets by comparing it with state-of-the-art imputation methods. Remarkably, our algorithm significantly outperforms other methods when the data is missing more than 60% of the features
Create account to get full access
Overview
- Data imputation, the process of filling in missing feature elements for incomplete data sets, is crucial for data-driven learning.
- The paper proposes a new framework that leverages supervision information, such as labels, to enhance the data imputation process and improve classification accuracy.
- The framework operates in two stages: first, it optimizes the similarity relationships among data represented by the kernel matrix to enhance classification accuracy; second, it uses the learned kernel matrix to guide data imputation through regression.
Plain English Explanation
When working with real-world data, it's common to have missing information or incomplete data sets. Data imputation is the process of filling in these missing elements, and it's an important step in data-driven learning.
The researchers in this paper propose a new approach that uses the information we already have about the data, such as its labels or classifications, to help guide the imputation process. The idea is that by using this supervisory information, we can improve the accuracy of the final classification model.
The framework works in two main steps:
-
First, it looks at the relationships between the data points, represented by a "kernel matrix," and tries to optimize these relationships in a way that enhances the classification accuracy. To prevent the system from overfitting, the researchers introduce a "perturbation variable" to make the process more robust.
-
Second, the framework uses the optimized kernel matrix as additional information to guide the imputation of the missing data through a regression process. This helps ensure that the imputed data is well-aligned with the ultimate goal of accurate classification.
The researchers tested this approach on several real-world data sets and found that it significantly outperformed other state-of-the-art imputation methods, especially when a large portion of the data was missing.
Technical Explanation
The paper proposes a novel framework that leverages supervisory information, such as training labels, to enhance the data imputation process and improve classification performance.
The framework operates in two stages:
-
Kernel Optimization: In the first stage, the framework optimizes the similarity relationships among data, represented by the kernel matrix, with the goal of enhancing classification accuracy. This is achieved by formulating an optimization problem that seeks to maximize the classification performance while minimizing the deviation from the original kernel matrix. To mitigate overfitting that may occur during this process, a perturbation variable is introduced to improve the robustness of the framework.
-
Imputation via Regression: In the second stage, the learned kernel matrix serves as additional supervision information to guide the data imputation process through regression. The framework utilizes the block coordinate descent method to efficiently solve the imputation problem.
The superiority of the proposed method is evaluated on four real-world data sets by comparing it with state-of-the-art imputation methods. The results demonstrate that the algorithm significantly outperforms other methods, especially when the data is missing more than 60% of the features.
Critical Analysis
The paper presents a promising approach to data imputation that effectively leverages supervision information, such as training labels, to improve classification performance.
One potential limitation of the framework is its reliance on the availability of label information. In scenarios where label data is scarce or unavailable, the effectiveness of the method may be reduced. Additionally, the paper does not discuss the computational complexity of the proposed algorithm, which could be an important consideration for large-scale or real-time applications.
Further research could explore the performance of the framework in the presence of more complex data structures, such as multimodal data or graph-structured data. Investigating the framework's robustness to various types of missing data patterns and the impact of different perturbation strategies on the imputation quality could also be valuable areas for future research.
Conclusion
This paper introduces a novel framework that effectively leverages supervision information, such as training labels, to enhance the data imputation process and improve classification performance. The two-stage approach, which optimizes the kernel matrix and then uses it to guide the imputation, demonstrates significant improvements over state-of-the-art methods, particularly when dealing with highly incomplete data sets.
While the framework shows promising results, further research is needed to explore its applicability in more complex data settings and to investigate its computational efficiency. Nonetheless, this work represents an important step towards developing more robust and effective data imputation techniques that can unlock the full potential of data-driven learning.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Imputation using training labels and classification via label imputation
Thu Nguyen, Tuan L. Vo, P{aa}l Halvorsen, Michael A. Riegler
0
0
Missing data is a common problem in practical settings. Various imputation methods have been developed to deal with missing data. However, even though the label is usually available in the training data, the common practice of imputation usually only relies on the input and ignores the label. In this work, we illustrate how stacking the label into the input can significantly improve the imputation of the input. In addition, we propose a classification strategy that initializes the predicted test label with missing values and stacks the label with the input for imputation. This allows imputing the label and the input at the same time. Also, the technique is capable of handling data training with missing labels without any prior imputation and is applicable to continuous, categorical, or mixed-type data. Experiments show promising results in terms of accuracy.
4/24/2024
📊
SEGAN: semi-supervised learning approach for missing data imputation
Xiaohua Pan, Weifeng Wu, Peiran Liu, Zhen Li, Peng Lu, Peijian Cao, Jianfeng Zhang, Xianfei Qiu, YangYang Wu
0
0
In many practical real-world applications, data missing is a very common phenomenon, making the development of data-driven artificial intelligence theory and technology increasingly difficult. Data completion is an important method for missing data preprocessing. Most existing miss-ing data completion models directly use the known information in the missing data set but ignore the impact of the data label information contained in the data set on the missing data completion model. To this end, this paper proposes a missing data completion model SEGAN based on semi-supervised learning, which mainly includes three important modules: generator, discriminator and classifier. In the SEGAN model, the classifier enables the generator to make more full use of known data and its label information when predicting missing data values. In addition, the SE-GAN model introduces a missing hint matrix to allow the discriminator to more effectively distinguish between known data and data filled by the generator. This paper theoretically proves that the SEGAN model that introduces a classifier and a missing hint matrix can learn the real known data distribution characteristics when reaching Nash equilibrium. Finally, a large number of experiments were conducted in this article, and the experimental results show that com-pared with the current state-of-the-art multivariate data completion method, the performance of the SEGAN model is improved by more than 3%.
6/13/2024
🛠️
Multilevel Stochastic Optimization for Imputation in Massive Medical Data Records
Wenrui Li, Xiaoyu Wang, Yuetian Sun, Snezana Milanovic, Mark Kon, Julio Enrique Castrillon-Candas
0
0
It has long been a recognized problem that many datasets contain significant levels of missing numerical data. A potentially critical predicate for application of machine learning methods to datasets involves addressing this problem. However, this is a challenging task. In this paper, we apply a recently developed multi-level stochastic optimization approach to the problem of imputation in massive medical records. The approach is based on computational applied mathematics techniques and is highly accurate. In particular, for the Best Linear Unbiased Predictor (BLUP) this multi-level formulation is exact, and is significantly faster and more numerically stable. This permits practical application of Kriging methods to data imputation problems for massive datasets. We test this approach on data from the National Inpatient Sample (NIS) data records, Healthcare Cost and Utilization Project (HCUP), Agency for Healthcare Research and Quality. Numerical results show that the multi-level method significantly outperforms current approaches and is numerically robust. It has superior accuracy as compared with methods recommended in the recent report from HCUP. Benchmark tests show up to 75% reductions in error. Furthermore, the results are also superior to recent state of the art methods such as discriminative deep learning.
4/4/2024
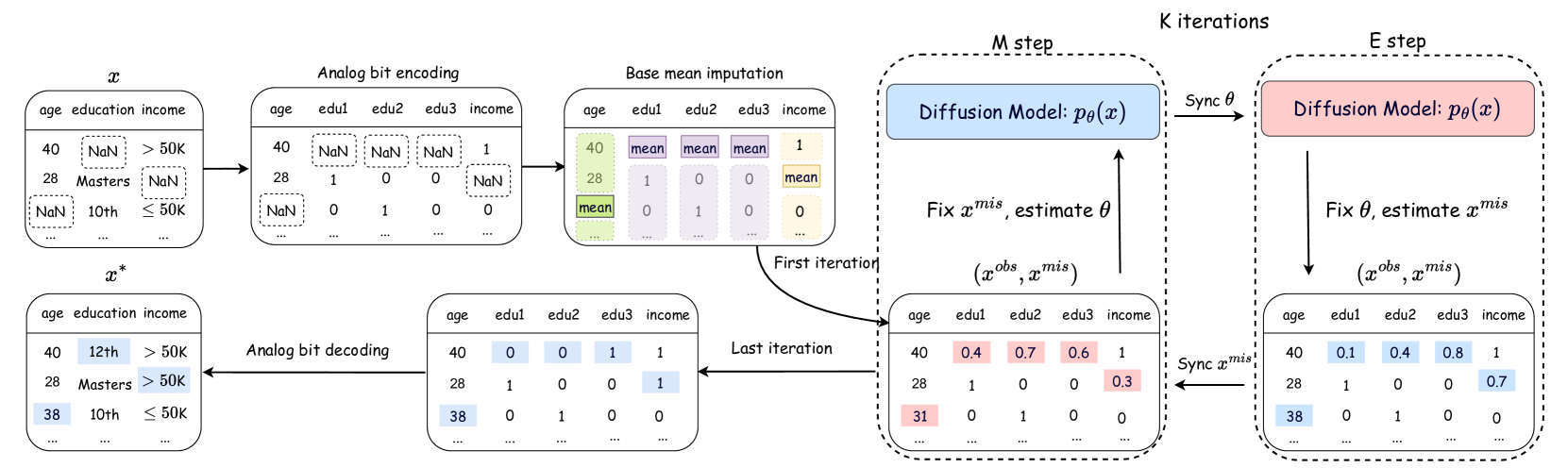
Unleashing the Potential of Diffusion Models for Incomplete Data Imputation
Hengrui Zhang, Liancheng Fang, Philip S. Yu
0
0
This paper introduces DiffPuter, an iterative method for missing data imputation that leverages the Expectation-Maximization (EM) algorithm and Diffusion Models. By treating missing data as hidden variables that can be updated during model training, we frame the missing data imputation task as an EM problem. During the M-step, DiffPuter employs a diffusion model to learn the joint distribution of both the observed and currently estimated missing data. In the E-step, DiffPuter re-estimates the missing data based on the conditional probability given the observed data, utilizing the diffusion model learned in the M-step. Starting with an initial imputation, DiffPuter alternates between the M-step and E-step until convergence. Through this iterative process, DiffPuter progressively refines the complete data distribution, yielding increasingly accurate estimations of the missing data. Our theoretical analysis demonstrates that the unconditional training and conditional sampling processes of the diffusion model align precisely with the objectives of the M-step and E-step, respectively. Empirical evaluations across 10 diverse datasets and comparisons with 16 different imputation methods highlight DiffPuter's superior performance. Notably, DiffPuter achieves an average improvement of 8.10% in MAE and 5.64% in RMSE compared to the most competitive existing method.
6/3/2024