Detail-Enhanced Intra- and Inter-modal Interaction for Audio-Visual Emotion Recognition
2405.16701
0
0

Abstract
Capturing complex temporal relationships between video and audio modalities is vital for Audio-Visual Emotion Recognition (AVER). However, existing methods lack attention to local details, such as facial state changes between video frames, which can reduce the discriminability of features and thus lower recognition accuracy. In this paper, we propose a Detail-Enhanced Intra- and Inter-modal Interaction network(DE-III) for AVER, incorporating several novel aspects. We introduce optical flow information to enrich video representations with texture details that better capture facial state changes. A fusion module integrates the optical flow estimation with the corresponding video frames to enhance the representation of facial texture variations. We also design attentive intra- and inter-modal feature enhancement modules to further improve the richness and discriminability of video and audio representations. A detailed quantitative evaluation shows that our proposed model outperforms all existing methods on three benchmark datasets for both concrete and continuous emotion recognition. To encourage further research and ensure replicability, we will release our full code upon acceptance.
Create account to get full access
Overview
- This paper explores a novel approach to audio-visual emotion recognition that leverages detail-enhanced intra- and inter-modal interactions.
- The researchers propose a transformer-based model that effectively combines visual and audio cues to recognize emotions, outperforming previous state-of-the-art methods.
- The key innovations include using optical flow information to capture fine-grained details, and designing specialized transformer architectures to model both intra-modal and inter-modal relationships.
Plain English Explanation
Recognizing emotions from audio and visual data, such as a person's voice and facial expressions, is an important task with many applications, such as in virtual assistants or mental health monitoring. This paper introduces a new method that does this better than previous approaches.
The researchers noticed that existing methods often miss important details in the audio and video data that could help recognize emotions more accurately. To address this, they developed a model that pays close attention to fine-grained details, like the subtle movements of a person's face or the nuances in their voice.
The model uses a type of artificial intelligence called a "transformer" to analyze the audio and video data together, finding connections between them that reveal emotional cues. For example, it might notice that a frown on the person's face matches the worried tone in their voice.
By focusing on these detailed interactions between the audio and visual signals, the model is able to recognize emotions more reliably than previous methods. This approach could lead to improvements in applications like virtual assistants that need to understand human emotions, or mental health monitoring tools that analyze a person's voice and facial expressions.
Technical Explanation
The key innovation in this paper is the use of detail-enhanced intra- and inter-modal interaction for audio-visual emotion recognition. The authors propose a transformer-based architecture that effectively models both the fine-grained details within each modality (intra-modal) and the cross-modal relationships between audio and visual cues (inter-modal).
Specifically, the model leverages optical flow information to capture subtle movements and details in the video data. This is combined with the audio features to provide a richer representation of the emotional state. The transformer-based design allows the model to learn complex relationships between the audio and visual modalities, going beyond simple feature concatenation or early/late fusion approaches.
The authors evaluate their model on several benchmark audio-visual emotion recognition datasets and demonstrate significant performance improvements over previous state-of-the-art methods. The recursive fusion and cross-attention mechanisms introduced in this work appear to be effective at exploiting the complementary information in the two modalities.
Critical Analysis
While the proposed approach shows promising results, the paper does not deeply explore the limitations or potential issues with the method. For example, the model's performance may be sensitive to the quality and synchronization of the audio and video data, which can be challenging to obtain in real-world scenarios.
Additionally, the paper does not provide much insight into the interpretability of the model's predictions. Understanding why the model makes certain emotion recognition decisions could be important for building trust and transparency, especially in sensitive applications like mental health monitoring.
Further research is needed to better understand the generalization and robustness of this approach, as well as its applicability to more diverse datasets and real-world deployment scenarios. Exploring the model's sample efficiency and computational requirements would also be valuable for assessing its practical feasibility.
Conclusion
This paper presents a novel transformer-based approach to audio-visual emotion recognition that effectively leverages detail-enhanced intra- and inter-modal interactions. By focusing on fine-grained details in both the audio and visual modalities, the model is able to outperform previous state-of-the-art methods on benchmark datasets.
The innovations introduced in this work, such as the use of optical flow information and specialized transformer architectures, represent a promising direction for advancing the field of multimodal emotion recognition. If further developed and refined, this approach could lead to significant improvements in applications that require robust and accurate understanding of human emotional states.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Audio-Visual Person Verification based on Recursive Fusion of Joint Cross-Attention
R. Gnana Praveen, Jahangir Alam
0
0
Person or identity verification has been recently gaining a lot of attention using audio-visual fusion as faces and voices share close associations with each other. Conventional approaches based on audio-visual fusion rely on score-level or early feature-level fusion techniques. Though existing approaches showed improvement over unimodal systems, the potential of audio-visual fusion for person verification is not fully exploited. In this paper, we have investigated the prospect of effectively capturing both the intra- and inter-modal relationships across audio and visual modalities, which can play a crucial role in significantly improving the fusion performance over unimodal systems. In particular, we introduce a recursive fusion of a joint cross-attentional model, where a joint audio-visual feature representation is employed in the cross-attention framework in a recursive fashion to progressively refine the feature representations that can efficiently capture the intra-and inter-modal relationships. To further enhance the audio-visual feature representations, we have also explored BLSTMs to improve the temporal modeling of audio-visual feature representations. Extensive experiments are conducted on the Voxceleb1 dataset to evaluate the proposed model. Results indicate that the proposed model shows promising improvement in fusion performance by adeptly capturing the intra-and inter-modal relationships across audio and visual modalities.
4/29/2024
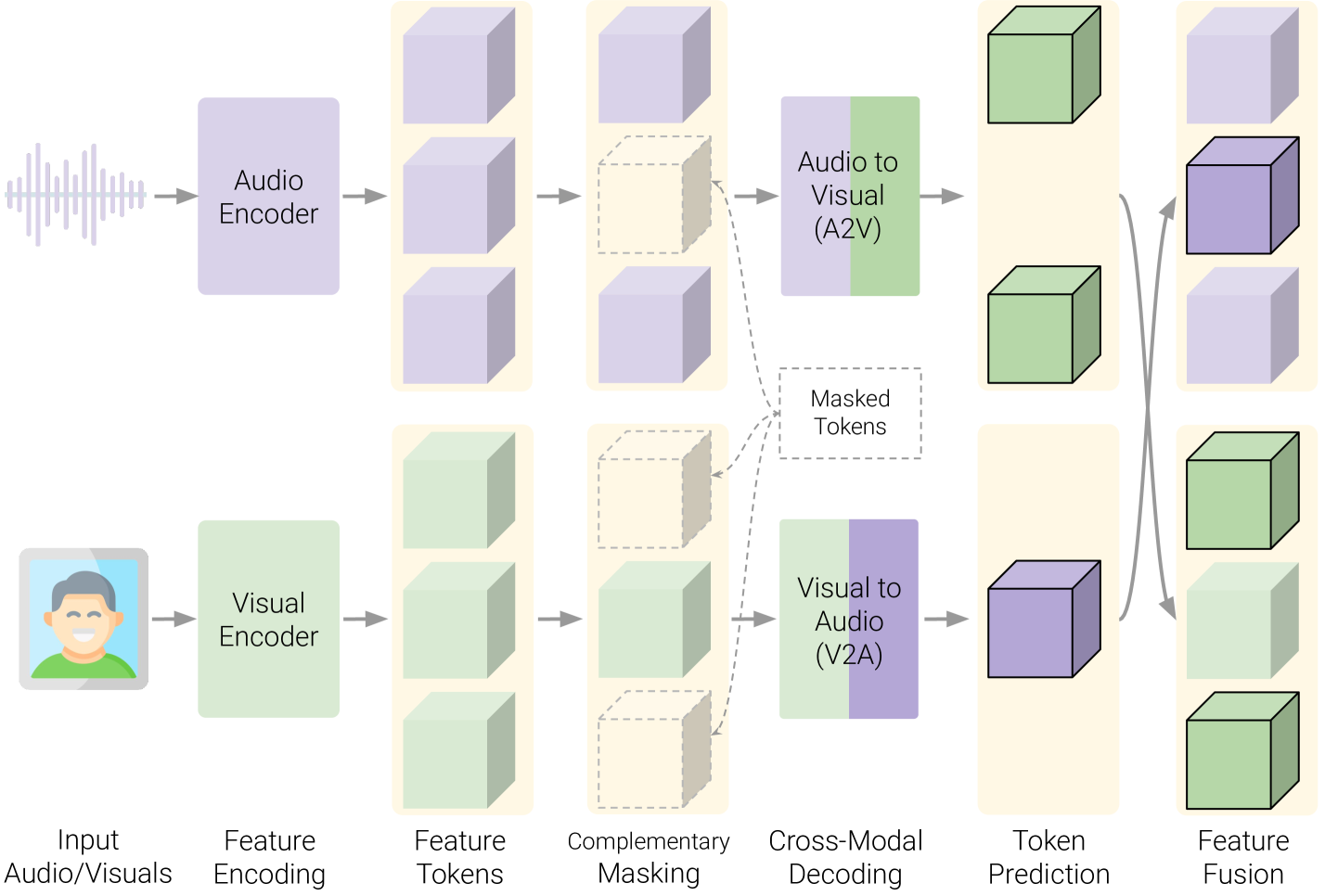
AVFF: Audio-Visual Feature Fusion for Video Deepfake Detection
Trevine Oorloff, Surya Koppisetti, Nicol`o Bonettini, Divyaraj Solanki, Ben Colman, Yaser Yacoob, Ali Shahriyari, Gaurav Bharaj
0
0
With the rapid growth in deepfake video content, we require improved and generalizable methods to detect them. Most existing detection methods either use uni-modal cues or rely on supervised training to capture the dissonance between the audio and visual modalities. While the former disregards the audio-visual correspondences entirely, the latter predominantly focuses on discerning audio-visual cues within the training corpus, thereby potentially overlooking correspondences that can help detect unseen deepfakes. We present Audio-Visual Feature Fusion (AVFF), a two-stage cross-modal learning method that explicitly captures the correspondence between the audio and visual modalities for improved deepfake detection. The first stage pursues representation learning via self-supervision on real videos to capture the intrinsic audio-visual correspondences. To extract rich cross-modal representations, we use contrastive learning and autoencoding objectives, and introduce a novel audio-visual complementary masking and feature fusion strategy. The learned representations are tuned in the second stage, where deepfake classification is pursued via supervised learning on both real and fake videos. Extensive experiments and analysis suggest that our novel representation learning paradigm is highly discriminative in nature. We report 98.6% accuracy and 99.1% AUC on the FakeAVCeleb dataset, outperforming the current audio-visual state-of-the-art by 14.9% and 9.9%, respectively.
6/6/2024
👁️
Inconsistency-Aware Cross-Attention for Audio-Visual Fusion in Dimensional Emotion Recognition
R Gnana Praveen, Jahangir Alam
0
0
Leveraging complementary relationships across modalities has recently drawn a lot of attention in multimodal emotion recognition. Most of the existing approaches explored cross-attention to capture the complementary relationships across the modalities. However, the modalities may also exhibit weak complementary relationships, which may deteriorate the cross-attended features, resulting in poor multimodal feature representations. To address this problem, we propose Inconsistency-Aware Cross-Attention (IACA), which can adaptively select the most relevant features on-the-fly based on the strong or weak complementary relationships across audio and visual modalities. Specifically, we design a two-stage gating mechanism that can adaptively select the appropriate relevant features to deal with weak complementary relationships. Extensive experiments are conducted on the challenging Aff-Wild2 dataset to show the robustness of the proposed model.
5/22/2024
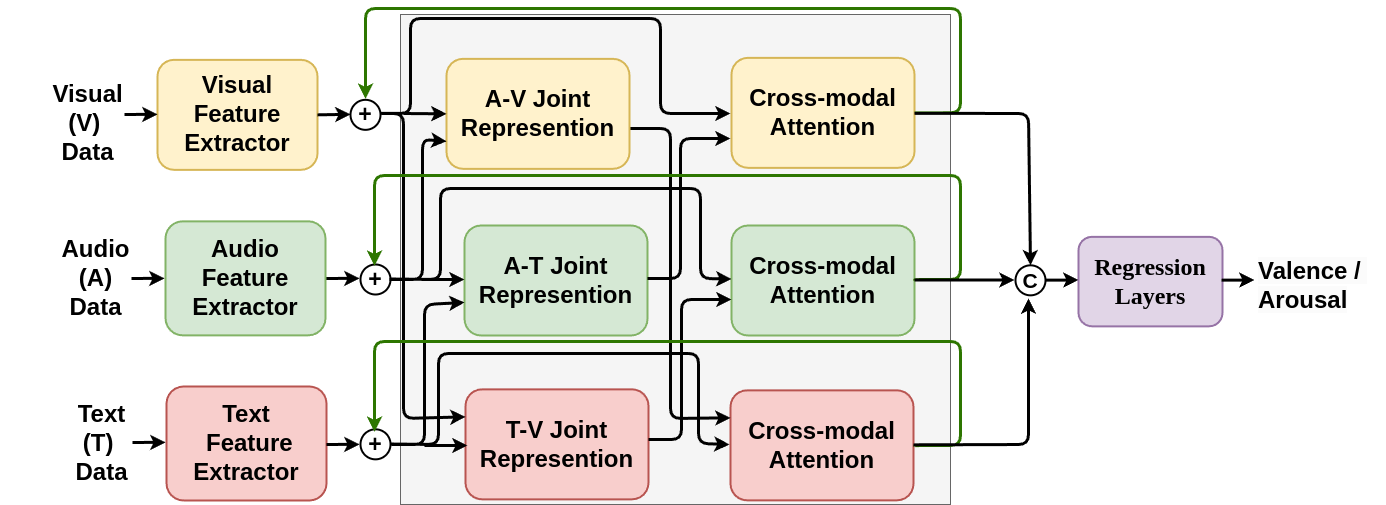
Recursive Joint Cross-Modal Attention for Multimodal Fusion in Dimensional Emotion Recognition
R. Gnana Praveen, Jahangir Alam
0
0
Though multimodal emotion recognition has achieved significant progress over recent years, the potential of rich synergic relationships across the modalities is not fully exploited. In this paper, we introduce Recursive Joint Cross-Modal Attention (RJCMA) to effectively capture both intra- and inter-modal relationships across audio, visual, and text modalities for dimensional emotion recognition. In particular, we compute the attention weights based on cross-correlation between the joint audio-visual-text feature representations and the feature representations of individual modalities to simultaneously capture intra- and intermodal relationships across the modalities. The attended features of the individual modalities are again fed as input to the fusion model in a recursive mechanism to obtain more refined feature representations. We have also explored Temporal Convolutional Networks (TCNs) to improve the temporal modeling of the feature representations of individual modalities. Extensive experiments are conducted to evaluate the performance of the proposed fusion model on the challenging Affwild2 dataset. By effectively capturing the synergic intra- and inter-modal relationships across audio, visual, and text modalities, the proposed fusion model achieves a Concordance Correlation Coefficient (CCC) of 0.585 (0.542) and 0.674 (0.619) for valence and arousal respectively on the validation set(test set). This shows a significant improvement over the baseline of 0.240 (0.211) and 0.200 (0.191) for valence and arousal, respectively, in the validation set (test set), achieving second place in the valence-arousal challenge of the 6th Affective Behavior Analysis in-the-Wild (ABAW) competition.
4/16/2024