Inf-MLLM: Efficient Streaming Inference of Multimodal Large Language Models on a Single GPU

0

Sign in to get full access
Overview
- Efficient streaming inference of multimodal large language models (LLMs) on a single GPU
- Addresses challenges of deploying LLMs in real-world applications
- Proposes an architecture and techniques to enable fast and memory-efficient inference
Plain English Explanation
The paper presents a system called Inf-MLLM that enables efficient streaming inference of multimodal large language models (LLMs) on a single GPU. LLMs, such as GPT-3 and DALL-E, have advanced natural language and image generation capabilities, but deploying them in real-world applications poses challenges.
Inf-MLLM addresses these challenges by introducing an architecture and techniques to enable fast and memory-efficient inference of multimodal LLMs. This allows LLMs to be used in applications that require low latency and limited GPU resources, such as interactive chatbots or content generation tools.
The key ideas behind Inf-MLLM include:
- Efficient streaming inference: processing inputs in a continuous stream rather than as a single batch, to reduce memory usage and latency
- Attention offloading: storing attention maps separately from the model, to reduce memory requirements
- Live prefetching: preloading and preprocessing inputs to reduce latency during inference
By incorporating these techniques, Inf-MLLM can perform efficient multimodal inference on a single GPU, enabling the deployment of LLMs in a wider range of real-world applications.
Technical Explanation
The paper introduces Inf-MLLM, a system for efficient streaming inference of multimodal large language models (LLMs) on a single GPU. The authors address the challenges of deploying LLMs in real-world applications, which often require low latency and limited GPU resources.
Inf-MLLM's architecture consists of several key components:
- Streaming inference: The system processes inputs in a continuous stream rather than as a single batch, reducing memory usage and latency.
- Attention offloading: Attention maps are stored separately from the model, further reducing memory requirements.
- Live prefetching: Inputs are preloaded and preprocessed to reduce latency during inference.
The authors evaluate Inf-MLLM on several multimodal benchmarks, including text-to-image generation and visual question answering. The results demonstrate that Inf-MLLM can achieve high inference throughput and low latency on a single GPU, outperforming traditional batch-based inference approaches.
Critical Analysis
The paper presents a well-designed and comprehensive solution to the challenges of deploying multimodal LLMs in real-world applications. The authors have carefully considered the key bottlenecks and developed a suite of techniques to address them.
One potential limitation of the work is that it focuses primarily on the inference stage and does not discuss the training or fine-tuning of the LLMs. In practical applications, the ability to efficiently fine-tune or adapt the models to specific domains or tasks may be equally important.
Additionally, the paper does not provide detailed comparisons to other state-of-the-art approaches for efficient LLM inference, such as Efficient LLM Inference Solution for Intel GPU or LiveMind: Low-Latency Large Language Models for Simultaneous Interaction. A more comprehensive benchmark against these related methods would help to better situate the contributions of Inf-MLLM.
Overall, the Inf-MLLM system represents a significant advancement in enabling the practical deployment of multimodal LLMs, and the techniques introduced in this paper are likely to be of interest to researchers and practitioners working on real-world LLM applications.
Conclusion
The Inf-MLLM paper presents an efficient system for streaming inference of multimodal large language models on a single GPU. By addressing key challenges such as memory usage and latency, the authors have developed a solution that enables the deployment of LLMs in a wider range of real-world applications, including interactive chatbots and content generation tools.
The techniques introduced in Inf-MLLM, such as streaming inference, attention offloading, and live prefetching, represent important advancements in the field of efficient LLM inference. These innovations can potentially be applied to other types of large-scale AI models and deployed in a variety of domains, further expanding the practical impact of these powerful language understanding and generation capabilities.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
New!Inf-MLLM: Efficient Streaming Inference of Multimodal Large Language Models on a Single GPU
Zhenyu Ning, Jieru Zhao, Qihao Jin, Wenchao Ding, Minyi Guo
Multimodal Large Language Models (MLLMs) are distinguished by their multimodal comprehensive ability and widely used in many real-world applications including GPT-4o, autonomous driving and robotics. Despite their impressive performance, the multimodal inputs always incur long context. The inference under long context requires caching massive Key and Value states (KV cache) of previous tokens, which introduces high latency and excessive memory consumption. Due to this reason, it is challenging to deploy streaming inference of MLLMs on edge devices, which largely constrains the power and usage of MLLMs in real-world applications. In this paper, we introduce Inf-MLLM, an efficient inference framework for MLLMs, which enable streaming inference of MLLM on a single GPU with infinite context. Inf-MLLM is based on our key observation of the attention pattern in both LLMs and MLLMs called attention saddles. Thanks to the newly discovered attention pattern, Inf-MLLM maintains a size-constrained KV cache by dynamically caching recent tokens and relevant tokens. Furthermore, Inf-MLLM proposes attention bias, a novel approach to enable MLLMs to capture long-term dependency. We show that Inf-MLLM enables multiple LLMs and MLLMs to achieve stable performance over 4M-token long texts and multi-round conversations with 1-hour-long videos on a single GPU. In addition, Inf-MLLM exhibits superior streaming reasoning quality than existing methods such as StreamingLLM and 2x speedup than H2O.
Read more9/17/2024

0
Infinite-LLM: Efficient LLM Service for Long Context with DistAttention and Distributed KVCache
Bin Lin, Chen Zhang, Tao Peng, Hanyu Zhao, Wencong Xiao, Minmin Sun, Anmin Liu, Zhipeng Zhang, Lanbo Li, Xiafei Qiu, Shen Li, Zhigang Ji, Tao Xie, Yong Li, Wei Lin
Large Language Models (LLMs) demonstrate substantial potential across a diverse array of domains via request serving. However, as trends continue to push for expanding context sizes, the autoregressive nature of LLMs results in highly dynamic behavior of the attention layers, showcasing significant differences in computational characteristics and memory requirements from the non-attention layers. This presents substantial challenges for resource management and performance optimization in service systems. Existing static model parallelism and resource allocation strategies fall short when dealing with this dynamicity. To address the issue, we propose Infinite-LLM, a novel LLM serving system designed to effectively handle dynamic context lengths. Infinite-LLM disaggregates attention layers from an LLM's inference process, facilitating flexible and independent resource scheduling that optimizes computational performance and enhances memory utilization jointly. By leveraging a pooled GPU memory strategy across a cluster, Infinite-LLM not only significantly boosts system throughput but also supports extensive context lengths. Evaluated on a dataset with context lengths ranging from a few to 2000K tokens across a cluster with 32 A100 GPUs, Infinite-LLM demonstrates throughput improvement of 1.35-3.4x compared to state-of-the-art methods, enabling efficient and elastic LLM deployment.
Read more7/8/2024
🤯
72
Efficient LLM inference solution on Intel GPU
Hui Wu, Yi Gan, Feng Yuan, Jing Ma, Wei Zhu, Yutao Xu, Hong Zhu, Yuhua Zhu, Xiaoli Liu, Jinghui Gu, Peng Zhao
Transformer based Large Language Models (LLMs) have been widely used in many fields, and the efficiency of LLM inference becomes hot topic in real applications. However, LLMs are usually complicatedly designed in model structure with massive operations and perform inference in the auto-regressive mode, making it a challenging task to design a system with high efficiency. In this paper, we propose an efficient LLM inference solution with low latency and high throughput. Firstly, we simplify the LLM decoder layer by fusing data movement and element-wise operations to reduce the memory access frequency and lower system latency. We also propose a segment KV cache policy to keep key/value of the request and response tokens in separate physical memory for effective device memory management, helping enlarge the runtime batch size and improve system throughput. A customized Scaled-Dot-Product-Attention kernel is designed to match our fusion policy based on the segment KV cache solution. We implement our LLM inference solution on Intel GPU and publish it publicly. Compared with the standard HuggingFace implementation, the proposed solution achieves up to 7x lower token latency and 27x higher throughput for some popular LLMs on Intel GPU.
Read more6/26/2024
0
LiveMind: Low-latency Large Language Models with Simultaneous Inference
Chuangtao Chen, Grace Li Zhang, Xunzhao Yin, Cheng Zhuo, Ulf Schlichtmann, Bing Li
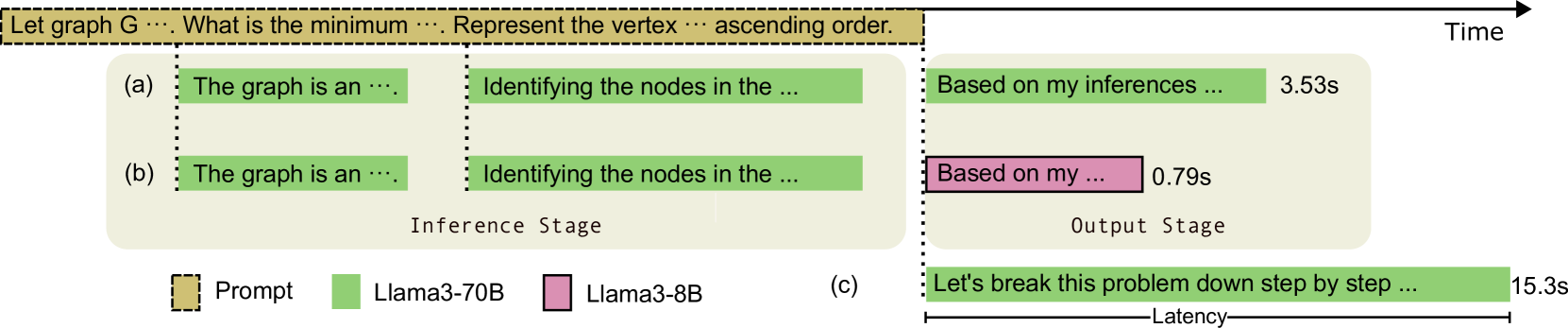
In this paper, we introduce a novel low-latency inference framework for large language models (LLMs) inference which enables LLMs to perform inferences with incomplete prompts. By reallocating computational processes to prompt input phase, we achieve a substantial reduction in latency, thereby significantly enhancing the interactive experience for users of LLMs. The framework adeptly manages the visibility of the streaming prompt to the model, allowing it to infer from incomplete prompts or await additional prompts. Compared with traditional inference methods that utilize complete prompts, our approach demonstrates an average reduction of 59% in response latency on the MMLU-Pro dataset, while maintaining comparable accuracy. Additionally, our framework facilitates collaborative inference and output across different models. By employing an LLM for inference and a small language model (SLM) for output, we achieve an average 68% reduction in response latency, alongside a 5.5% improvement in accuracy on the MMLU-Pro dataset compared with the SLM baseline. For long prompts exceeding 20 sentences, the response latency can be reduced by up to 93%.
Read more6/21/2024