AICoderEval: Improving AI Domain Code Generation of Large Language Models
2406.04712
0
0
Abstract
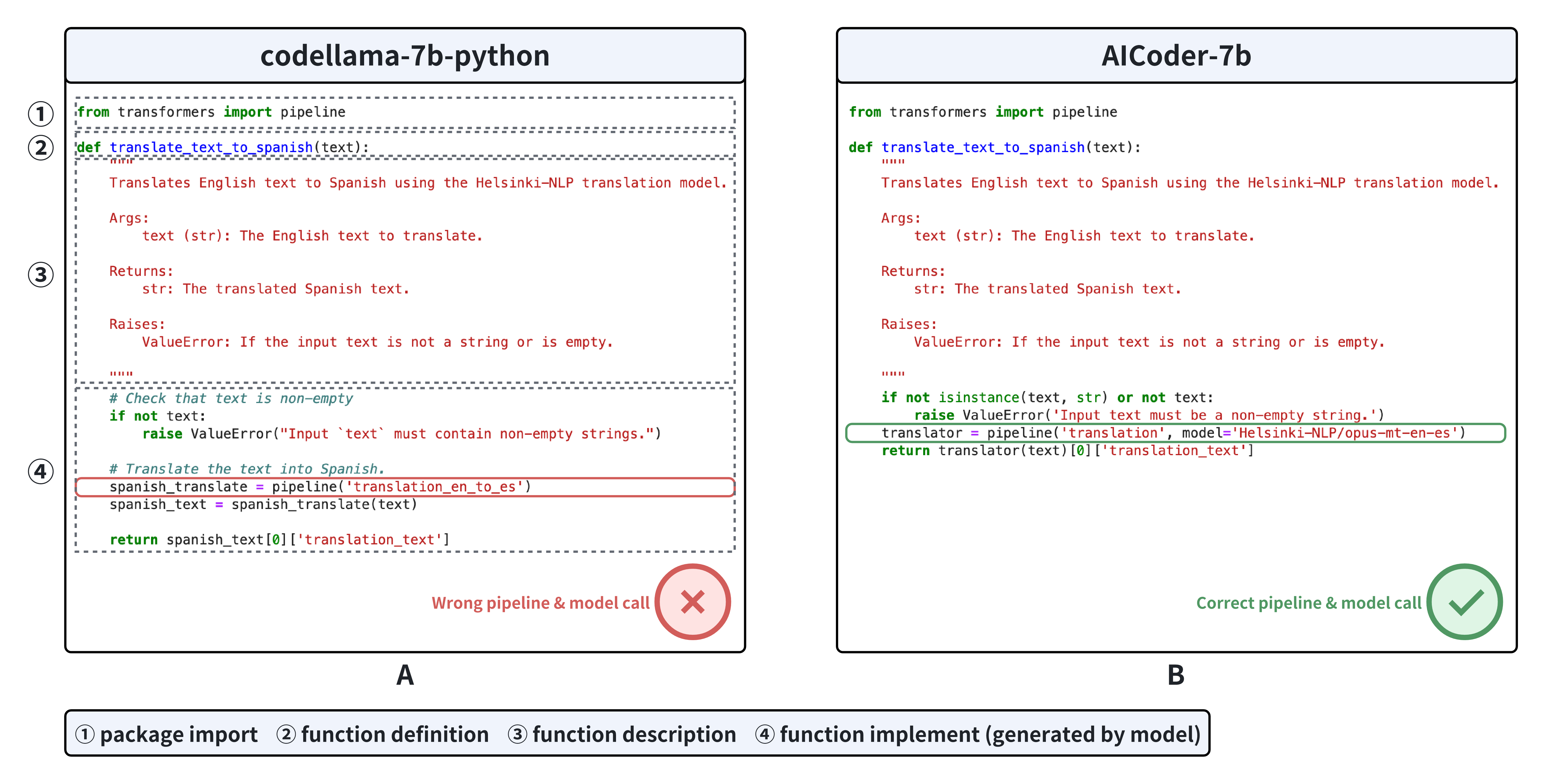
Automated code generation is a pivotal capability of large language models (LLMs). However, assessing this capability in real-world scenarios remains challenging. Previous methods focus more on low-level code generation, such as model loading, instead of generating high-level codes catering for real-world tasks, such as image-to-text, text classification, in various domains. Therefore, we construct AICoderEval, a dataset focused on real-world tasks in various domains based on HuggingFace, PyTorch, and TensorFlow, along with comprehensive metrics for evaluation and enhancing LLMs' task-specific code generation capability. AICoderEval contains test cases and complete programs for automated evaluation of these tasks, covering domains such as natural language processing, computer vision, and multimodal learning. To facilitate research in this area, we open-source the AICoderEval dataset at url{https://huggingface.co/datasets/vixuowis/AICoderEval}. After that, we propose CoderGen, an agent-based framework, to help LLMs generate codes related to real-world tasks on the constructed AICoderEval. Moreover, we train a more powerful task-specific code generation model, named AICoder, which is refined on llama-3 based on AICoderEval. Our experiments demonstrate the effectiveness of CoderGen in improving LLMs' task-specific code generation capability (by 12.00% on pass@1 for original model and 9.50% on pass@1 for ReAct Agent). AICoder also outperforms current code generation LLMs, indicating the great quality of the AICoderEval benchmark.
Create account to get full access
Overview
- This paper introduces a new benchmark called AICoderEval for evaluating large language models' (LLMs) code generation capabilities in AI-related domains.
- The benchmark includes a diverse set of coding tasks across various AI subfields, designed to systematically assess the models' abilities to generate working, high-quality code.
- The authors also propose several metrics to measure different aspects of code quality, going beyond just syntactic correctness.
- Experiments on popular LLMs like GPT-3 and Codex show that there is significant room for improvement in their AI-related code generation abilities compared to human performance.
Plain English Explanation
The paper presents a new benchmark called AICoderEval that is designed to thoroughly evaluate how well large language models (LLMs) can generate code for tasks related to artificial intelligence (AI). The benchmark includes a diverse set of coding challenges covering different subfields of AI, such as machine learning, natural language processing, and computer vision.
The key idea is to go beyond just checking if the generated code is syntactically correct, and instead assess various aspects of code quality, like functionality, efficiency, and maintainability. The authors propose several metrics to measure these qualities, allowing for a more comprehensive evaluation of the models' abilities.
When they tested popular LLMs like GPT-3 and Codex, the results showed that there is still significant room for improvement in these models' AI-related code generation capabilities compared to what human programmers can achieve. This suggests that while LLMs have made impressive advances in language understanding and generation, there are still challenges in applying them effectively to the specialized domain of AI-focused software development.
Technical Explanation
The paper introduces a new benchmark called AICoderEval for evaluating the code generation abilities of large language models (LLMs) in the context of AI-related domains. The benchmark consists of a diverse set of coding tasks across various AI subfields, such as machine learning, natural language processing, and computer vision.
To assess the quality of the generated code, the authors propose several metrics that go beyond just checking for syntactic correctness. These include measures of functionality (e.g., does the code solve the intended problem?), efficiency (e.g., is the code optimized for performance?), and maintainability (e.g., is the code well-structured and documented?). By incorporating these more comprehensive evaluation criteria, the benchmark aims to provide a systematic and rigorous assessment of the models' abilities to generate high-quality, production-ready code.
The authors evaluate popular LLMs, including GPT-3 and Codex, on the AICoderEval benchmark. The results show that while these models have made significant progress in natural language understanding and generation, they still struggle to match human-level performance on the AI-focused coding tasks. This suggests that there is substantial room for improvement in applying LLMs to the specialized domain of AI software development.
Critical Analysis
The AICoderEval benchmark presented in this paper is a valuable contribution to the field of code generation and the evaluation of large language models. By focusing on AI-related coding tasks and incorporating more comprehensive quality metrics, the benchmark provides a more nuanced and practical assessment of the models' capabilities.
One potential limitation of the study is the scope of the benchmark tasks. While the authors have made efforts to cover a diverse set of AI subfields, there may still be gaps or biases in the types of problems included. Additionally, the evaluation criteria, while well-justified, could be further refined or expanded based on feedback from the broader AI and software engineering communities.
Another area for further research could be investigating the specific challenges that LLMs face when generating high-quality AI-focused code. By analyzing the models' performance on individual tasks or metrics, researchers may be able to identify the key bottlenecks and develop targeted approaches to address them, such as RealHumanEval or DevEval.
Overall, the AICoderEval benchmark represents an important step forward in evaluating the capabilities of large language models in the context of AI software development. The insights gained from this work can help guide the ongoing efforts to improve the code generation abilities of these powerful language models.
Conclusion
This paper introduces a new benchmark called AICoderEval that is designed to systematically evaluate the code generation capabilities of large language models (LLMs) in AI-related domains. The benchmark includes a diverse set of coding tasks across various AI subfields, and the authors propose several metrics to assess different aspects of code quality, going beyond just syntactic correctness.
Experiments on popular LLMs like GPT-3 and Codex show that there is significant room for improvement in their AI-focused code generation abilities compared to human performance. This suggests that while LLMs have made impressive advances in natural language understanding and generation, applying them effectively to the specialized domain of AI software development remains a significant challenge.
The AICoderEval benchmark represents an important contribution to the field, providing a more comprehensive and practical evaluation of LLMs' code generation capabilities. The insights gained from this work can help guide the ongoing efforts to improve these models' abilities to generate high-quality, production-ready code for AI-related applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

InfiCoder-Eval: Systematically Evaluating the Question-Answering Capabilities of Code Large Language Models
Linyi Li, Shijie Geng, Zhenwen Li, Yibo He, Hao Yu, Ziyue Hua, Guanghan Ning, Siwei Wang, Tao Xie, Hongxia Yang
0
0
Large Language Models for code (code LLMs) have witnessed tremendous progress in recent years. With the rapid development of code LLMs, many popular evaluation benchmarks, such as HumanEval, DS-1000, and MBPP, have emerged to measure the performance of code LLMs with a particular focus on code generation tasks. However, they are insufficient to cover the full range of expected capabilities of code LLMs, which span beyond code generation to answering diverse coding-related questions. To fill this gap, we propose InfiBench, the first large-scale freeform question-answering (QA) benchmark for code to our knowledge, comprising 234 carefully selected high-quality Stack Overflow questions that span across 15 programming languages. InfiBench uses four types of model-free automatic metrics to evaluate response correctness where domain experts carefully concretize the criterion for each question. We conduct a systematic evaluation for over 100 latest code LLMs on InfiBench, leading to a series of novel and insightful findings. Our detailed analyses showcase potential directions for further advancement of code LLMs. InfiBench is fully open source and continuously expanding to foster more scientific and systematic practices for code LLM evaluation.
6/28/2024
💬
AutoCoder: Enhancing Code Large Language Model with textsc{AIEV-Instruct}
Bin Lei, Yuchen Li, Qiuwu Chen
0
0
We introduce AutoCoder, the first Large Language Model to surpass GPT-4 Turbo (April 2024) and GPT-4o in pass@1 on the Human Eval benchmark test ($mathbf{90.9%}$ vs. $mathbf{90.2%}$). In addition, AutoCoder offers a more versatile code interpreter compared to GPT-4 Turbo and GPT-4o. It's code interpreter can install external packages instead of limiting to built-in packages. AutoCoder's training data is a multi-turn dialogue dataset created by a system combining agent interaction and external code execution verification, a method we term textbf{textsc{AIEV-Instruct}} (Instruction Tuning with Agent-Interaction and Execution-Verified). Compared to previous large-scale code dataset generation methods, textsc{AIEV-Instruct} reduces dependence on proprietary large models and provides execution-validated code dataset. The code and the demo video is available in url{https://github.com/bin123apple/AutoCoder}.
5/27/2024

What is the best model? Application-driven Evaluation for Large Language Models
Shiguo Lian, Kaikai Zhao, Xinhui Liu, Xuejiao Lei, Bikun Yang, Wenjing Zhang, Kai Wang, Zhaoxiang Liu
0
0
General large language models enhanced with supervised fine-tuning and reinforcement learning from human feedback are increasingly popular in academia and industry as they generalize foundation models to various practical tasks in a prompt manner. To assist users in selecting the best model in practical application scenarios, i.e., choosing the model that meets the application requirements while minimizing cost, we introduce A-Eval, an application-driven LLMs evaluation benchmark for general large language models. First, we categorize evaluation tasks into five main categories and 27 sub-categories from a practical application perspective. Next, we construct a dataset comprising 678 question-and-answer pairs through a process of collecting, annotating, and reviewing. Then, we design an objective and effective evaluation method and evaluate a series of LLMs of different scales on A-Eval. Finally, we reveal interesting laws regarding model scale and task difficulty level and propose a feasible method for selecting the best model. Through A-Eval, we provide clear empirical and engineer guidance for selecting the best model, reducing barriers to selecting and using LLMs and promoting their application and development. Our benchmark is publicly available at https://github.com/UnicomAI/DataSet/tree/main/TestData/GeneralAbility.
6/18/2024
The RealHumanEval: Evaluating Large Language Models' Abilities to Support Programmers
Hussein Mozannar, Valerie Chen, Mohammed Alsobay, Subhro Das, Sebastian Zhao, Dennis Wei, Manish Nagireddy, Prasanna Sattigeri, Ameet Talwalkar, David Sontag
0
0
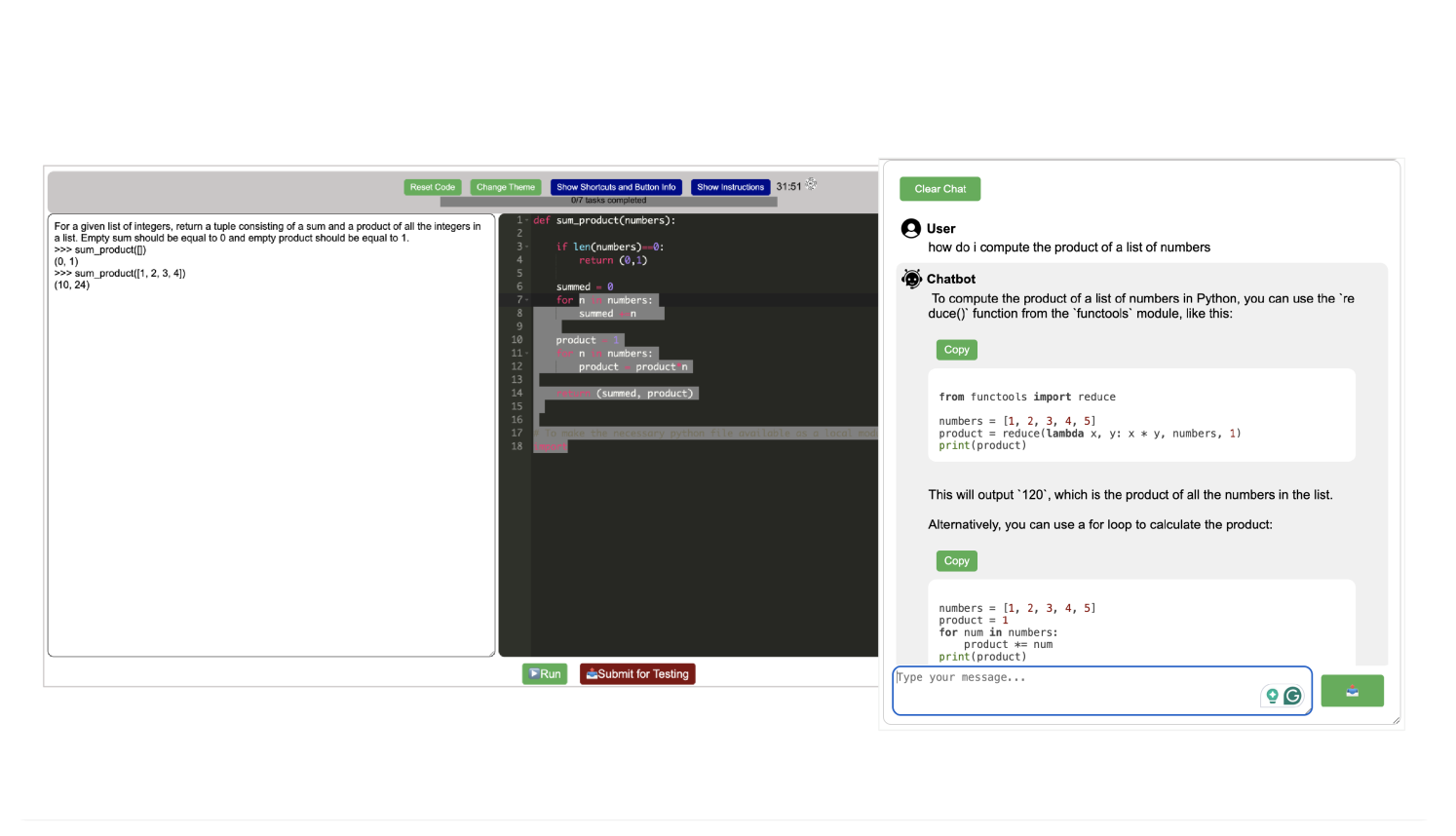
Evaluation of large language models (LLMs) for code has primarily relied on static benchmarks, including HumanEval (Chen et al., 2021), which measure the ability of LLMs to generate complete code that passes unit tests. As LLMs are increasingly used as programmer assistants, we study whether gains on existing benchmarks translate to gains in programmer productivity when coding with LLMs, including time spent coding. In addition to static benchmarks, we investigate the utility of preference metrics that might be used as proxies to measure LLM helpfulness, such as code acceptance or copy rates. To do so, we introduce RealHumanEval, a web interface to measure the ability of LLMs to assist programmers, through either autocomplete or chat support. We conducted a user study (N=213) using RealHumanEval in which users interacted with six LLMs of varying base model performance. Despite static benchmarks not incorporating humans-in-the-loop, we find that improvements in benchmark performance lead to increased programmer productivity; however gaps in benchmark versus human performance are not proportional -- a trend that holds across both forms of LLM support. In contrast, we find that programmer preferences do not correlate with their actual performance, motivating the need for better, human-centric proxy signals. We also open-source RealHumanEval to enable human-centric evaluation of new models and the study data to facilitate efforts to improve code models.
4/4/2024