Information-Theoretic Progress Measures reveal Grokking is an Emergent Phase Transition

1
Sign in to get full access
Overview
- The paper investigates the phenomenon of "grokking" - where neural networks suddenly achieve high performance on a task after a long period of slow learning.
- The authors use information-theoretic progress measures to study this behavior, and find that grokking corresponds to an emergent phase transition in the network's learning dynamics.
- The paper provides insights into the underlying mechanisms behind grokking and its implications for training and understanding deep neural networks.
Plain English Explanation
The paper examines a curious behavior observed in the training of deep neural networks, where the network suddenly starts performing very well on a task after a long period of slow progress. The authors call this phenomenon "grokking."
To understand grokking, the researchers used special measures that track the flow of information within the network during training. They found that grokking corresponds to an abrupt transition or "phase change" in the network's learning process. Before the phase change, the network is slowly accumulating information, but at a certain point, it undergoes a rapid reorganization that allows it to quickly solve the task.
The paper suggests that this phase transition is an emergent property of the network's architecture and training, rather than something that is explicitly engineered. By shedding light on the mechanisms behind grokking, the research offers insights that could help us better understand and potentially harness this phenomenon when training deep neural networks on real-world tasks.
Technical Explanation
The authors use information-theoretic progress measures to study the dynamics of grokking in deep neural networks. These measures track how quickly the network is learning and accumulating information about the task during training.
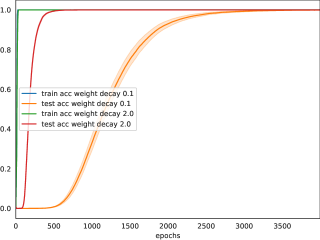
The key finding is that grokking corresponds to an abrupt phase transition in the network's learning dynamics. Prior to the phase transition, the network exhibits slow, gradual progress as it accumulates information about the task. However, at a certain point, the network undergoes a rapid reorganization that allows it to quickly solve the task - this is the "grokking" phenomenon.
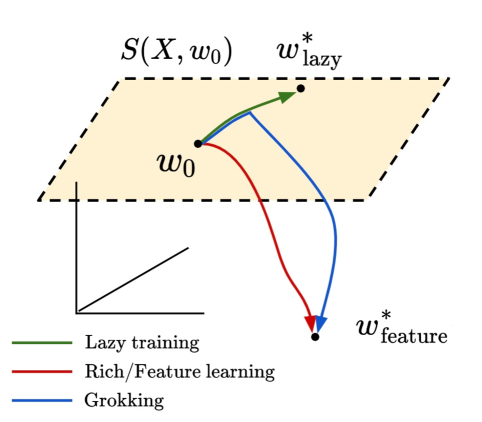
The authors demonstrate this phase transition behavior across a variety of neural network architectures and tasks, suggesting it is a general emergent property of deep learning systems. They also connect this to prior work on early vs. late phase implicit biases and lazy vs. rich training dynamics.
Critical Analysis
The paper provides a compelling information-theoretic perspective on the grokking phenomenon, but it also raises some important caveats and questions for further research.
One key limitation is that the analysis is largely correlational - the paper demonstrates the phase transition behavior, but does not directly establish the causal mechanisms behind it. Additional work may be needed to fully explain the underlying drivers of the phase transition.
The paper also does not explore how the specifics of the network architecture, training data, or optimization procedure might influence the likelihood and characteristics of the grokking transition. Investigating these factors could yield further insights.
Additionally, while the phase transition behavior appears to be a general phenomenon, the practical implications for training and deploying deep neural networks in the real world are not yet clear. More work is needed to understand how to reliably induce or control this phase transition in service of practical objectives.
Conclusion
This paper uses innovative information-theoretic progress measures to shed light on the enigmatic grokking phenomenon in deep learning. By demonstrating that grokking corresponds to an emergent phase transition in the network's learning dynamics, the work offers a new conceptual framework for understanding this behavior.
The insights from this research could ultimately help machine learning practitioners better harness the power of grokking when training deep neural networks on complex, real-world tasks. However, further work is needed to fully elucidate the causal mechanisms and practical implications of this phase transition behavior.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
1
Information-Theoretic Progress Measures reveal Grokking is an Emergent Phase Transition
Kenzo Clauw, Sebastiano Stramaglia, Daniele Marinazzo
This paper studies emergent phenomena in neural networks by focusing on grokking where models suddenly generalize after delayed memorization. To understand this phase transition, we utilize higher-order mutual information to analyze the collective behavior (synergy) and shared properties (redundancy) between neurons during training. We identify distinct phases before grokking allowing us to anticipate when it occurs. We attribute grokking to an emergent phase transition caused by the synergistic interactions between neurons as a whole. We show that weight decay and weight initialization can enhance the emergent phase.
Read more8/20/2024

0
Grokking as a First Order Phase Transition in Two Layer Networks
Noa Rubin, Inbar Seroussi, Zohar Ringel
A key property of deep neural networks (DNNs) is their ability to learn new features during training. This intriguing aspect of deep learning stands out most clearly in recently reported Grokking phenomena. While mainly reflected as a sudden increase in test accuracy, Grokking is also believed to be a beyond lazy-learning/Gaussian Process (GP) phenomenon involving feature learning. Here we apply a recent development in the theory of feature learning, the adaptive kernel approach, to two teacher-student models with cubic-polynomial and modular addition teachers. We provide analytical predictions on feature learning and Grokking properties of these models and demonstrate a mapping between Grokking and the theory of phase transitions. We show that after Grokking, the state of the DNN is analogous to the mixed phase following a first-order phase transition. In this mixed phase, the DNN generates useful internal representations of the teacher that are sharply distinct from those before the transition.
Read more5/7/2024
0
Grokking as the Transition from Lazy to Rich Training Dynamics
Tanishq Kumar, Blake Bordelon, Samuel J. Gershman, Cengiz Pehlevan
We propose that the grokking phenomenon, where the train loss of a neural network decreases much earlier than its test loss, can arise due to a neural network transitioning from lazy training dynamics to a rich, feature learning regime. To illustrate this mechanism, we study the simple setting of vanilla gradient descent on a polynomial regression problem with a two layer neural network which exhibits grokking without regularization in a way that cannot be explained by existing theories. We identify sufficient statistics for the test loss of such a network, and tracking these over training reveals that grokking arises in this setting when the network first attempts to fit a kernel regression solution with its initial features, followed by late-time feature learning where a generalizing solution is identified after train loss is already low. We find that the key determinants of grokking are the rate of feature learning -- which can be controlled precisely by parameters that scale the network output -- and the alignment of the initial features with the target function $y(x)$. We argue this delayed generalization arises when (1) the top eigenvectors of the initial neural tangent kernel and the task labels $y(x)$ are misaligned, but (2) the dataset size is large enough so that it is possible for the network to generalize eventually, but not so large that train loss perfectly tracks test loss at all epochs, and (3) the network begins training in the lazy regime so does not learn features immediately. We conclude with evidence that this transition from lazy (linear model) to rich training (feature learning) can control grokking in more general settings, like on MNIST, one-layer Transformers, and student-teacher networks.
Read more4/12/2024
🔮
0
Progress Measures for Grokking on Real-world Datasets
Satvik Golechha
Grokking, a phenomenon where machine learning models generalize long after overfitting, has been primarily observed and studied in algorithmic tasks. This paper explores grokking in real-world datasets using deep neural networks for classification under the cross-entropy loss. We challenge the prevalent hypothesis that the $L_2$ norm of weights is the primary cause of grokking by demonstrating that grokking can occur outside the expected range of weight norms. To better understand grokking, we introduce three new progress measures: activation sparsity, absolute weight entropy, and approximate local circuit complexity. These measures are conceptually related to generalization and demonstrate a stronger correlation with grokking in real-world datasets compared to weight norms. Our findings suggest that while weight norms might usually correlate with grokking and our progress measures, they are not causative, and our proposed measures provide a better understanding of the dynamics of grokking.
Read more6/21/2024