Progress Measures for Grokking on Real-world Datasets

0
🔮
Sign in to get full access
Overview
- This paper explores the phenomenon of "grokking" in deep neural networks for real-world classification tasks.
- Grokking refers to when machine learning models can generalize long after they have stopped overfitting.
- The researchers challenge the idea that the L2 norm of weights is the primary cause of grokking, and instead propose three new progress measures that better correlate with grokking.
Plain English Explanation
Deep neural networks are a type of machine learning model that can be trained to perform a variety of tasks, such as image classification or language understanding. When training these models, there is often a period where the model starts to "overfit" to the training data, meaning it performs very well on the data it was trained on but struggles to generalize to new, unseen data.
However, Grokking as Transition from Lazy to Rich is a phenomenon where, even after a model has overfit, it can continue to improve its ability to generalize to new data. This has been observed in algorithmic tasks, but the researchers in this paper wanted to explore whether grokking also occurs in real-world datasets when using deep neural networks for classification.
The researchers challenged the idea that the L2 norm of the model's weights (a measure of how large the numbers in the model are) is the primary driver of this grokking behavior. Instead, they proposed three new progress measures that they believe better capture the dynamics of grokking:
- Activation Sparsity: How sparse (or concentrated) the activations are in the neural network.
- Absolute Weight Entropy: A measure of the "complexity" or "richness" of the weights in the neural network.
- Approximate Local Circuit Complexity: A way to measure the "complexity" of the computational circuits within the neural network.
The researchers found that these new progress measures showed a stronger correlation with grokking in their experiments on real-world datasets, suggesting that while weight norms may often be related to grokking, they are not the fundamental cause. The new measures provide a better understanding of the underlying dynamics at play.
Technical Explanation
The researchers conducted experiments using deep neural networks trained on real-world classification datasets, such as CIFAR-10 and ImageNet. They trained the models using the standard cross-entropy loss function and observed the phenomenon of grokking, where the models continued to improve their generalization performance long after they had stopped overfitting to the training data.
To better understand this grokking behavior, the researchers introduced three new progress measures:
-
Activation Sparsity: This measures how sparse (or concentrated) the activations are in the neural network. The researchers found that as grokking occurred, the activations became more sparse, suggesting that the model was learning to use a smaller set of "features" to make its predictions.
-
Absolute Weight Entropy: This measures the "complexity" or "richness" of the weights in the neural network. The researchers found that as grokking occurred, the absolute weight entropy increased, indicating that the model was learning more complex representations.
-
Approximate Local Circuit Complexity: This is a way to measure the "complexity" of the computational circuits within the neural network. The researchers found that as grokking occurred, the local circuit complexity increased, suggesting that the model was learning more complex computational structures.
The researchers compared these new progress measures to the commonly used L2 norm of the weights and found that the new measures showed a stronger correlation with the grokking behavior observed in the experiments. This challenges the prevalent hypothesis that the L2 norm of the weights is the primary cause of grokking, and suggests that the new measures provide a better understanding of the underlying dynamics of this phenomenon.
Critical Analysis
The researchers provide a valuable contribution by exploring grokking in the context of real-world datasets and deep neural networks, rather than just algorithmic tasks. This helps to broaden our understanding of this phenomenon and its potential implications for practical applications of machine learning.
One potential limitation of the study is that it focuses only on classification tasks using the cross-entropy loss function. It would be interesting to see if the researchers' findings hold true for other types of machine learning problems and loss functions.
Additionally, while the researchers propose three new progress measures, it's not entirely clear how these measures relate to the underlying mechanisms driving grokking. Further research may be needed to fully elucidate the connections between these measures and the fundamental principles behind grokking.
It's also worth noting that the paper does not explore the potential implications of grokking for the robustness or reliability of machine learning models. As the field continues to advance, understanding how and why grokking occurs could have important practical consequences for the deployment of these models in real-world applications.
Conclusion
This paper provides valuable insights into the phenomenon of grokking in deep neural networks trained on real-world datasets. By introducing three new progress measures that better correlate with grokking than the commonly used L2 norm of weights, the researchers challenge the prevailing hypothesis and offer a more nuanced understanding of the underlying dynamics at play.
The findings have the potential to inform future research on generalization in machine learning, as well as the development of more robust and reliable neural network architectures. As the field of deep learning continues to evolve, studies like this can help us better understand the complex and often counterintuitive behaviors of these powerful models.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🔮
0
Progress Measures for Grokking on Real-world Datasets
Satvik Golechha
Grokking, a phenomenon where machine learning models generalize long after overfitting, has been primarily observed and studied in algorithmic tasks. This paper explores grokking in real-world datasets using deep neural networks for classification under the cross-entropy loss. We challenge the prevalent hypothesis that the $L_2$ norm of weights is the primary cause of grokking by demonstrating that grokking can occur outside the expected range of weight norms. To better understand grokking, we introduce three new progress measures: activation sparsity, absolute weight entropy, and approximate local circuit complexity. These measures are conceptually related to generalization and demonstrate a stronger correlation with grokking in real-world datasets compared to weight norms. Our findings suggest that while weight norms might usually correlate with grokking and our progress measures, they are not causative, and our proposed measures provide a better understanding of the dynamics of grokking.
Read more6/21/2024
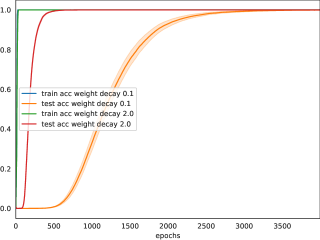
1
Information-Theoretic Progress Measures reveal Grokking is an Emergent Phase Transition
Kenzo Clauw, Sebastiano Stramaglia, Daniele Marinazzo
This paper studies emergent phenomena in neural networks by focusing on grokking where models suddenly generalize after delayed memorization. To understand this phase transition, we utilize higher-order mutual information to analyze the collective behavior (synergy) and shared properties (redundancy) between neurons during training. We identify distinct phases before grokking allowing us to anticipate when it occurs. We attribute grokking to an emergent phase transition caused by the synergistic interactions between neurons as a whole. We show that weight decay and weight initialization can enhance the emergent phase.
Read more8/20/2024
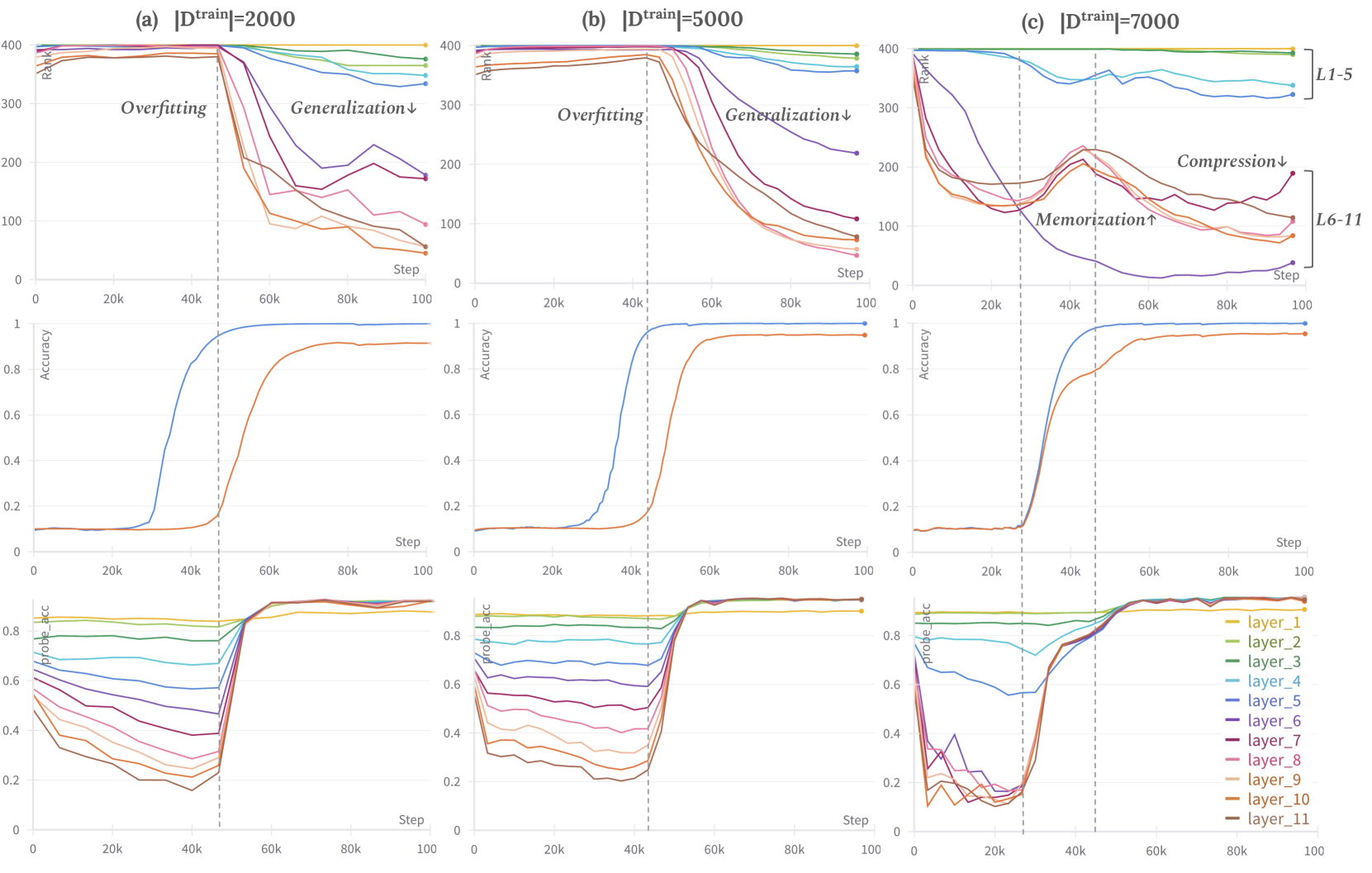
0
Deep Grokking: Would Deep Neural Networks Generalize Better?
Simin Fan, Razvan Pascanu, Martin Jaggi
Recent research on the grokking phenomenon has illuminated the intricacies of neural networks' training dynamics and their generalization behaviors. Grokking refers to a sharp rise of the network's generalization accuracy on the test set, which occurs long after an extended overfitting phase, during which the network perfectly fits the training set. While the existing research primarily focus on shallow networks such as 2-layer MLP and 1-layer Transformer, we explore grokking on deep networks (e.g. 12-layer MLP). We empirically replicate the phenomenon and find that deep neural networks can be more susceptible to grokking than its shallower counterparts. Meanwhile, we observe an intriguing multi-stage generalization phenomenon when increase the depth of the MLP model where the test accuracy exhibits a secondary surge, which is scarcely seen on shallow models. We further uncover compelling correspondences between the decreasing of feature ranks and the phase transition from overfitting to the generalization stage during grokking. Additionally, we find that the multi-stage generalization phenomenon often aligns with a double-descent pattern in feature ranks. These observations suggest that internal feature rank could serve as a more promising indicator of the model's generalization behavior compared to the weight-norm. We believe our work is the first one to dive into grokking in deep neural networks, and investigate the relationship of feature rank and generalization performance.
Read more5/31/2024
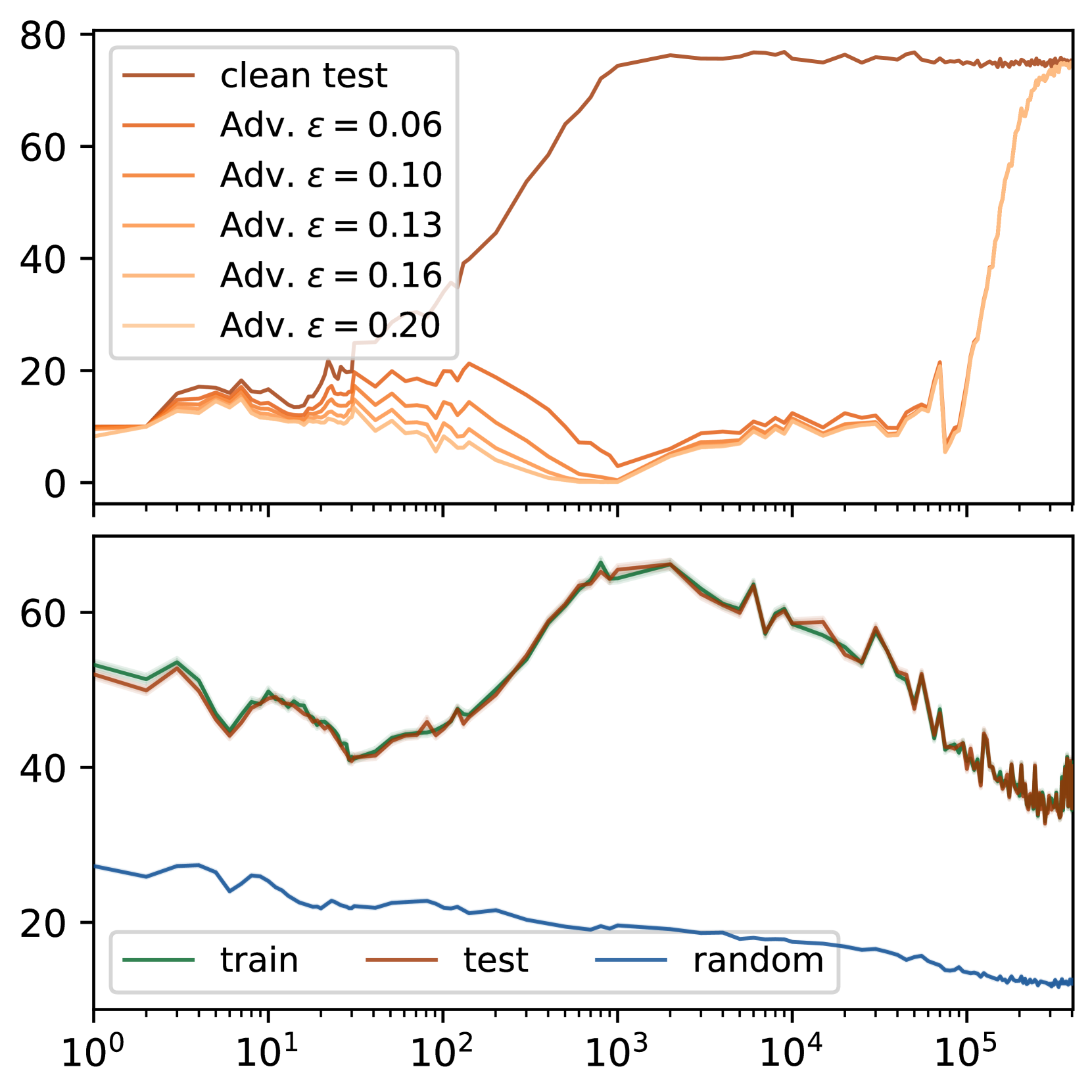
0
Deep Networks Always Grok and Here is Why
Ahmed Imtiaz Humayun, Randall Balestriero, Richard Baraniuk
Grokking, or delayed generalization, is a phenomenon where generalization in a deep neural network (DNN) occurs long after achieving near zero training error. Previous studies have reported the occurrence of grokking in specific controlled settings, such as DNNs initialized with large-norm parameters or transformers trained on algorithmic datasets. We demonstrate that grokking is actually much more widespread and materializes in a wide range of practical settings, such as training of a convolutional neural network (CNN) on CIFAR10 or a Resnet on Imagenette. We introduce the new concept of delayed robustness, whereby a DNN groks adversarial examples and becomes robust, long after interpolation and/or generalization. We develop an analytical explanation for the emergence of both delayed generalization and delayed robustness based on the local complexity of a DNN's input-output mapping. Our local complexity measures the density of so-called linear regions (aka, spline partition regions) that tile the DNN input space and serves as a utile progress measure for training. We provide the first evidence that, for classification problems, the linear regions undergo a phase transition during training whereafter they migrate away from the training samples (making the DNN mapping smoother there) and towards the decision boundary (making the DNN mapping less smooth there). Grokking occurs post phase transition as a robust partition of the input space thanks to the linearization of the DNN mapping around the training points. Website: https://bit.ly/grok-adversarial
Read more6/10/2024