Informed POMDP: Leveraging Additional Information in Model-Based RL

0
❗
Sign in to get full access
Overview
- This paper introduces a new learning paradigm called the "informed POMDP" that accounts for additional information available during training.
- The authors propose an objective that leverages this extra information to learn a sufficient statistic of the history for optimal control.
- They adapt this informed objective to learn a world model that can sample latent trajectories.
- Experiments show that using this informed world model leads to improved learning speed in several environments when incorporated into the Dreamer algorithm.
Plain English Explanation
The paper explores a way to improve how reinforcement learning agents learn in partially observable environments. Normally, agents only have access to limited information about their environment during execution.
However, the authors propose a new setup where additional information may be available during the training phase. They call this the "informed POMDP" - a type of partially observable Markov decision process where more data is provided upfront.
The key idea is to use this extra training information to help the agent learn a more efficient representation of the environment. This allows the agent to make better decisions and learn faster compared to the standard POMDP setup.
The authors develop a new learning objective that leverages the additional training information. They also show how to adapt this objective to train a "world model" - a machine learning model that can simulate the environment. Using this informed world model in the Dreamer algorithm leads to faster learning in several test environments.
Overall, this work highlights the value of considering any extra information that may be available when training AI agents to operate in complex, partially observed environments.
Technical Explanation
The paper introduces the "informed POMDP", a new learning paradigm that assumes the agent has access to additional information at training time beyond just the observations and actions experienced during execution.
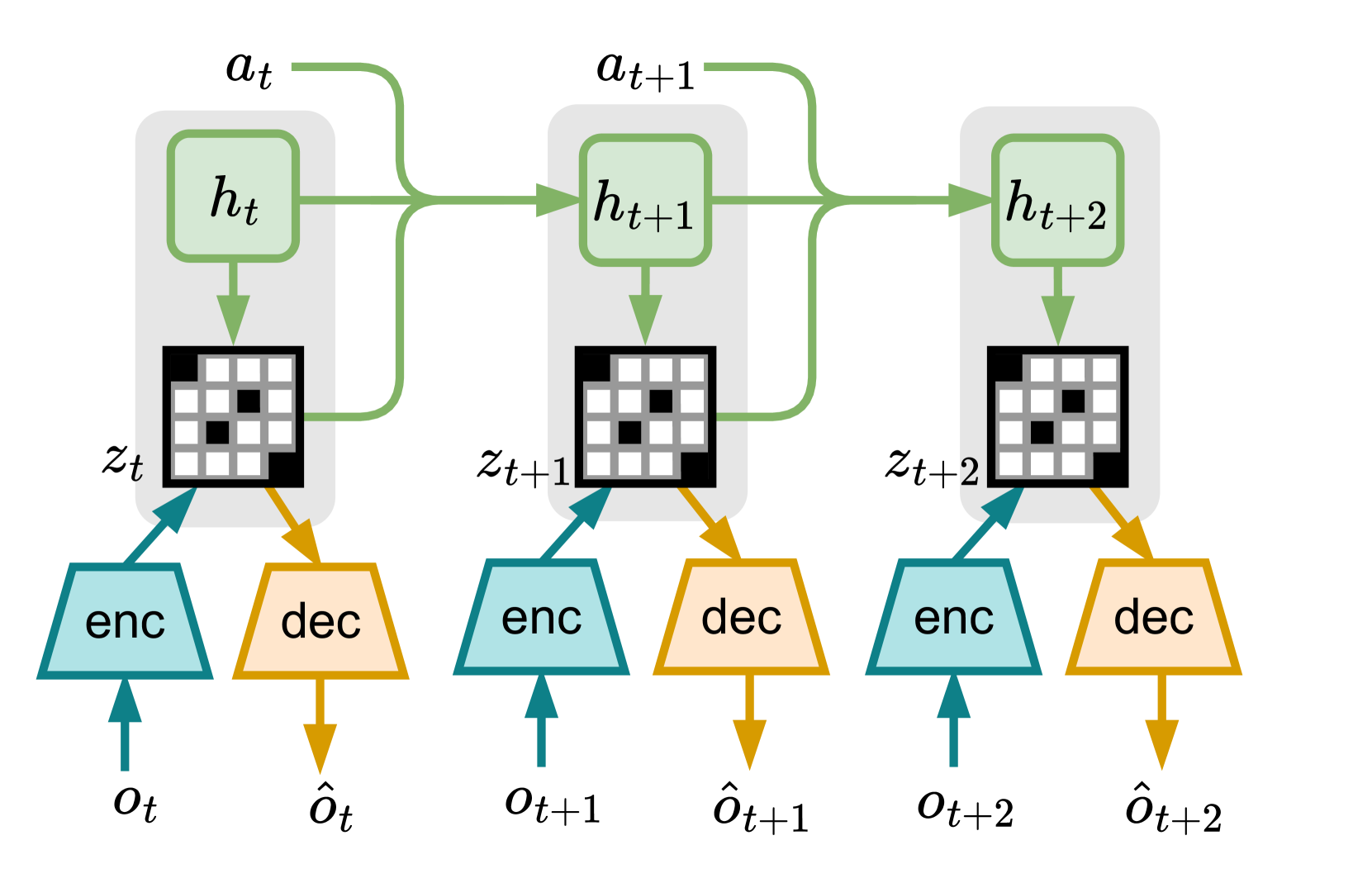
The authors propose an informed objective function that leverages this extra training information to learn a sufficient statistic of the history for optimal control. Specifically, the objective encourages the agent to learn a representation that captures all the relevant information for making optimal decisions, while discarding irrelevant details.
Next, the authors adapt this informed objective to train a world model - a neural network that can sample latent trajectories of the environment. This informed world model is then incorporated into the Dreamer algorithm, a model-based reinforcement learning method.
Experiments across several partially observable environments show that agents trained with the informed world model exhibit faster learning compared to the standard POMDP setup. The authors attribute this improvement to the agent's ability to leverage the additional training information to learn a more efficient representation of the environment.
Critical Analysis
The key innovation of this work is the introduction of the "informed POMDP" paradigm, which acknowledges that extra information may be available during training in many real-world scenarios. The authors provide a principled way to leverage this additional data through their informed objective function.
One limitation is that the nature and source of the extra training information is not specified. In practice, determining what supplementary data is available and how to best incorporate it may require domain-specific knowledge and careful design.
Additionally, the experiments are limited to simulated environments, so further research is needed to understand how the informed POMDP approach performs in more complex, real-world settings. There may be practical challenges in scaling the world model training to large, high-dimensional environments.
Overall, this work makes a compelling case for considering any available auxiliary information when learning in partially observable domains. The simplicity of the informed objective adaptation and the empirical results advocate for further exploration of this promising research direction.
Conclusion
This paper introduces the informed POMDP, a new learning paradigm that accounts for additional information available during training in partially observable environments. The authors develop an informed objective function that leverages this extra data to learn a more efficient representation of the environment.
By adapting this informed objective to train a world model, the authors demonstrate improved learning speed when incorporating the model into the Dreamer algorithm. These results highlight the value of considering any supplementary information that may be available when training AI agents to operate in complex, partially observed settings.
Further research is needed to understand the practical challenges and limitations of the informed POMDP approach, as well as to explore its potential applications in real-world domains. Nevertheless, this work represents an important step towards more sample-efficient and data-driven reinforcement learning.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
❗
0
Informed POMDP: Leveraging Additional Information in Model-Based RL
Gaspard Lambrechts, Adrien Bolland, Damien Ernst
In this work, we generalize the problem of learning through interaction in a POMDP by accounting for eventual additional information available at training time. First, we introduce the informed POMDP, a new learning paradigm offering a clear distinction between the information at training and the observation at execution. Next, we propose an objective that leverages this information for learning a sufficient statistic of the history for the optimal control. We then adapt this informed objective to learn a world model able to sample latent trajectories. Finally, we empirically show a learning speed improvement in several environments using this informed world model in the Dreamer algorithm. These results and the simplicity of the proposed adaptation advocate for a systematic consideration of eventual additional information when learning in a POMDP using model-based RL.
Read more6/13/2024
0
Reinforcement Learning from Delayed Observations via World Models
Armin Karamzade, Kyungmin Kim, Montek Kalsi, Roy Fox
In standard reinforcement learning settings, agents typically assume immediate feedback about the effects of their actions after taking them. However, in practice, this assumption may not hold true due to physical constraints and can significantly impact the performance of learning algorithms. In this paper, we address observation delays in partially observable environments. We propose leveraging world models, which have shown success in integrating past observations and learning dynamics, to handle observation delays. By reducing delayed POMDPs to delayed MDPs with world models, our methods can effectively handle partial observability, where existing approaches achieve sub-optimal performance or degrade quickly as observability decreases. Experiments suggest that one of our methods can outperform a naive model-based approach by up to 250%. Moreover, we evaluate our methods on visual delayed environments, for the first time showcasing delay-aware reinforcement learning continuous control with visual observations.
Read more6/27/2024

0
Increasing the Value of Information During Planning in Uncertain Environments
Gaurab Pokharel
Prior studies have demonstrated that for many real-world problems, POMDPs can be solved through online algorithms both quickly and with near optimality. However, on an important set of problems where there is a large time delay between when the agent can gather information and when it needs to use that information, these solutions fail to adequately consider the value of information. As a result, information gathering actions, even when they are critical in the optimal policy, will be ignored by existing solutions, leading to sub-optimal decisions by the agent. In this research, we develop a novel solution that rectifies this problem by introducing a new algorithm that improves upon state-of-the-art online planning by better reflecting on the value of actions that gather information. We do this by adding Entropy to the UCB1 heuristic in the POMCP algorithm. We test this solution on the hallway problem. Results indicate that our new algorithm performs significantly better than POMCP.
Read more9/24/2024
🏅
0
Provable Representation with Efficient Planning for Partial Observable Reinforcement Learning
Hongming Zhang, Tongzheng Ren, Chenjun Xiao, Dale Schuurmans, Bo Dai
In most real-world reinforcement learning applications, state information is only partially observable, which breaks the Markov decision process assumption and leads to inferior performance for algorithms that conflate observations with state. Partially Observable Markov Decision Processes (POMDPs), on the other hand, provide a general framework that allows for partial observability to be accounted for in learning, exploration and planning, but presents significant computational and statistical challenges. To address these difficulties, we develop a representation-based perspective that leads to a coherent framework and tractable algorithmic approach for practical reinforcement learning from partial observations. We provide a theoretical analysis for justifying the statistical efficiency of the proposed algorithm, and also empirically demonstrate the proposed algorithm can surpass state-of-the-art performance with partial observations across various benchmarks, advancing reliable reinforcement learning towards more practical applications.
Read more6/12/2024