Initialization is Critical to Whether Transformers Fit Composite Functions by Inference or Memorizing

0
Sign in to get full access
Overview
- This paper investigates how the initial parameters ("initialization") of Transformer models can impact whether they fit a given composite function by inference or by memorization.
- The authors conduct experiments to understand how initialization affects the Transformer's ability to generalize and compose functions.
- They find that the Transformer's behavior critically depends on its initialization, with some initializations leading to inference-based generalization and others leading to memorization.
Plain English Explanation
The paper looks at how the starting point, or "initialization", of a Transformer machine learning model can affect whether the model tries to
The key idea is that the initialization of the model's parameters (the starting numbers used before training) can lead the model down different paths - one where it tries to figure out the general rules and patterns in the data, versus one where it just remembers the specific examples it has seen. This has important implications for how well the model can generalize to new situations it hasn't seen before.
The researchers ran experiments to explore this phenomenon in more depth. They found that Transformers' behavior can indeed critically depend on their initialization - some initializations lead to inference-based generalization, while others lead to mere memorization. This helps explain why Transformers can sometimes struggle to compose or generalize functions, and shows the importance of carefully choosing the initialization when training these models.
Technical Explanation
The paper investigates how the initialization of Transformer models affects their ability to fit a given composite function, either through
The authors design experiments where Transformers are trained to fit a composite function f(g(x)), where f and g are simple functions. They explore how the Transformer's behavior changes based on the initialization of its parameters.
The key finding is that the Transformer's approach - either inference or memorization - is highly sensitive to the initialization. Some initializations lead the Transformer to discover the underlying f and g functions and generalize to new compositions. Other initializations cause the Transformer to simply memorize the training examples, failing to generalize.
This suggests that the inductive biases encoded in the Transformer's initialization play a critical role in whether it can learn to compose functions. Initializations that preserve the modular structure of the problem seem to facilitate inference-based generalization, while other initializations lead to memorization.
The paper provides important insights into the factors that impact the Transformer's ability to learn and compose functions, with implications for designing more compositional and generalizable language models.
Critical Analysis
The paper provides a detailed and thoughtful investigation into an important issue with Transformer models - their tendency to memorize rather than truly understand and generalize composite functions. The authors' experimental setup and analysis are rigorous, and their findings have clear relevance for the development of more compositional and generalizable language models.
That said, the paper does not delve into some potential limitations or caveats. For example, it's unclear how these results would scale to more complex, realistic composite functions beyond the simple examples used in the experiments. Additionally, the authors don't explore the precise mechanisms by which different initializations lead to memorization versus inference-based generalization.
Further research could investigate these issues in more depth, as well as explore techniques for encouraging Transformers to adopt more inference-based approaches by design, perhaps through specialized architectures or training regimes. Exploring methods like iterated learning or activating hidden spatial invariance may help address the memorization tendencies highlighted in this paper.
Conclusion
This paper makes an important contribution by demonstrating the critical role that initialization plays in whether Transformer models fit a composite function through inference or memorization. The authors' experimental findings reveal fundamental limitations in the Transformer's ability to compose functions, with significant implications for the development of more compositional and generalizable language models.
While the paper does not explore all possible angles, it provides a solid foundation for future research into techniques that can encourage Transformers to adopt more inference-based approaches. Addressing the memorization tendencies highlighted in this work could unlock substantial advances in the field of compositional machine learning.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Initialization is Critical to Whether Transformers Fit Composite Functions by Inference or Memorizing
Zhongwang Zhang, Pengxiao Lin, Zhiwei Wang, Yaoyu Zhang, Zhi-Qin John Xu
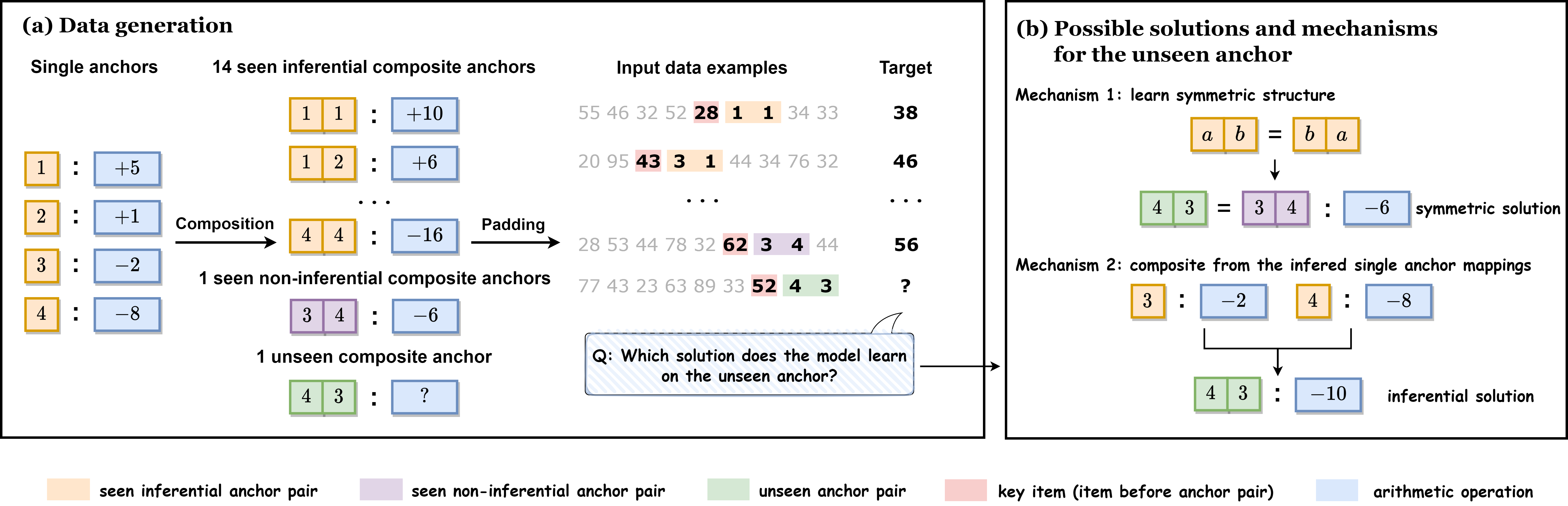
Transformers have shown impressive capabilities across various tasks, but their performance on compositional problems remains a topic of debate. In this work, we investigate the mechanisms of how transformers behave on unseen compositional tasks. We discover that the parameter initialization scale plays a critical role in determining whether the model learns inferential solutions, which capture the underlying compositional primitives, or symmetric solutions, which simply memorize mappings without understanding the compositional structure. By analyzing the information flow and vector representations within the model, we reveal the distinct mechanisms underlying these solution types. We further find that inferential solutions exhibit low complexity bias, which we hypothesize is a key factor enabling them to learn individual mappings for single anchors. Building upon the understanding of these mechanisms, we can predict the learning behavior of models with different initialization scales when faced with data of varying complexity. Our findings provide valuable insights into the role of initialization scale in shaping the type of solution learned by transformers and their ability to learn and generalize compositional tasks.
Read more5/27/2024
🖼️
0
Attention as a Hypernetwork
Simon Schug, Seijin Kobayashi, Yassir Akram, Jo~ao Sacramento, Razvan Pascanu
Transformers can under some circumstances generalize to novel problem instances whose constituent parts might have been encountered during training but whose compositions have not. What mechanisms underlie this ability for compositional generalization? By reformulating multi-head attention as a hypernetwork, we reveal that a low-dimensional latent code specifies key-query specific operations. We find empirically that this latent code is highly structured, capturing information about the subtasks performed by the network. Using the framework of attention as a hypernetwork we further propose a simple modification of multi-head linear attention that strengthens the ability for compositional generalization on a range of abstract reasoning tasks. In particular, we introduce a symbolic version of the Raven Progressive Matrices human intelligence test on which we demonstrate how scaling model size and data enables compositional generalization and gives rise to a functionally structured latent code in the transformer.
Read more6/24/2024
✨
0
When can transformers compositionally generalize in-context?
Seijin Kobayashi, Simon Schug, Yassir Akram, Florian Redhardt, Johannes von Oswald, Razvan Pascanu, Guillaume Lajoie, Jo~ao Sacramento
Many tasks can be composed from a few independent components. This gives rise to a combinatorial explosion of possible tasks, only some of which might be encountered during training. Under what circumstances can transformers compositionally generalize from a subset of tasks to all possible combinations of tasks that share similar components? Here we study a modular multitask setting that allows us to precisely control compositional structure in the data generation process. We present evidence that transformers learning in-context struggle to generalize compositionally on this task despite being in principle expressive enough to do so. Compositional generalization becomes possible only when introducing a bottleneck that enforces an explicit separation between task inference and task execution.
Read more7/18/2024
🏷️
0
Local to Global: Learning Dynamics and Effect of Initialization for Transformers
Ashok Vardhan Makkuva, Marco Bondaschi, Chanakya Ekbote, Adway Girish, Alliot Nagle, Hyeji Kim, Michael Gastpar
In recent years, transformer-based models have revolutionized deep learning, particularly in sequence modeling. To better understand this phenomenon, there is a growing interest in using Markov input processes to study transformers. However, our current understanding in this regard remains limited with many fundamental questions about how transformers learn Markov chains still unanswered. In this paper, we address this by focusing on first-order Markov chains and single-layer transformers, providing a comprehensive characterization of the learning dynamics in this context. Specifically, we prove that transformer parameters trained on next-token prediction loss can either converge to global or local minima, contingent on the initialization and the Markovian data properties, and we characterize the precise conditions under which this occurs. To the best of our knowledge, this is the first result of its kind highlighting the role of initialization. We further demonstrate that our theoretical findings are corroborated by empirical evidence. Based on these insights, we provide guidelines for the initialization of transformer parameters and demonstrate their effectiveness. Finally, we outline several open problems in this arena. Code is available at: https://github.com/Bond1995/Markov.
Read more6/28/2024