Towards Top-Down Reasoning: An Explainable Multi-Agent Approach for Visual Question Answering
2311.17331
0
0
Abstract
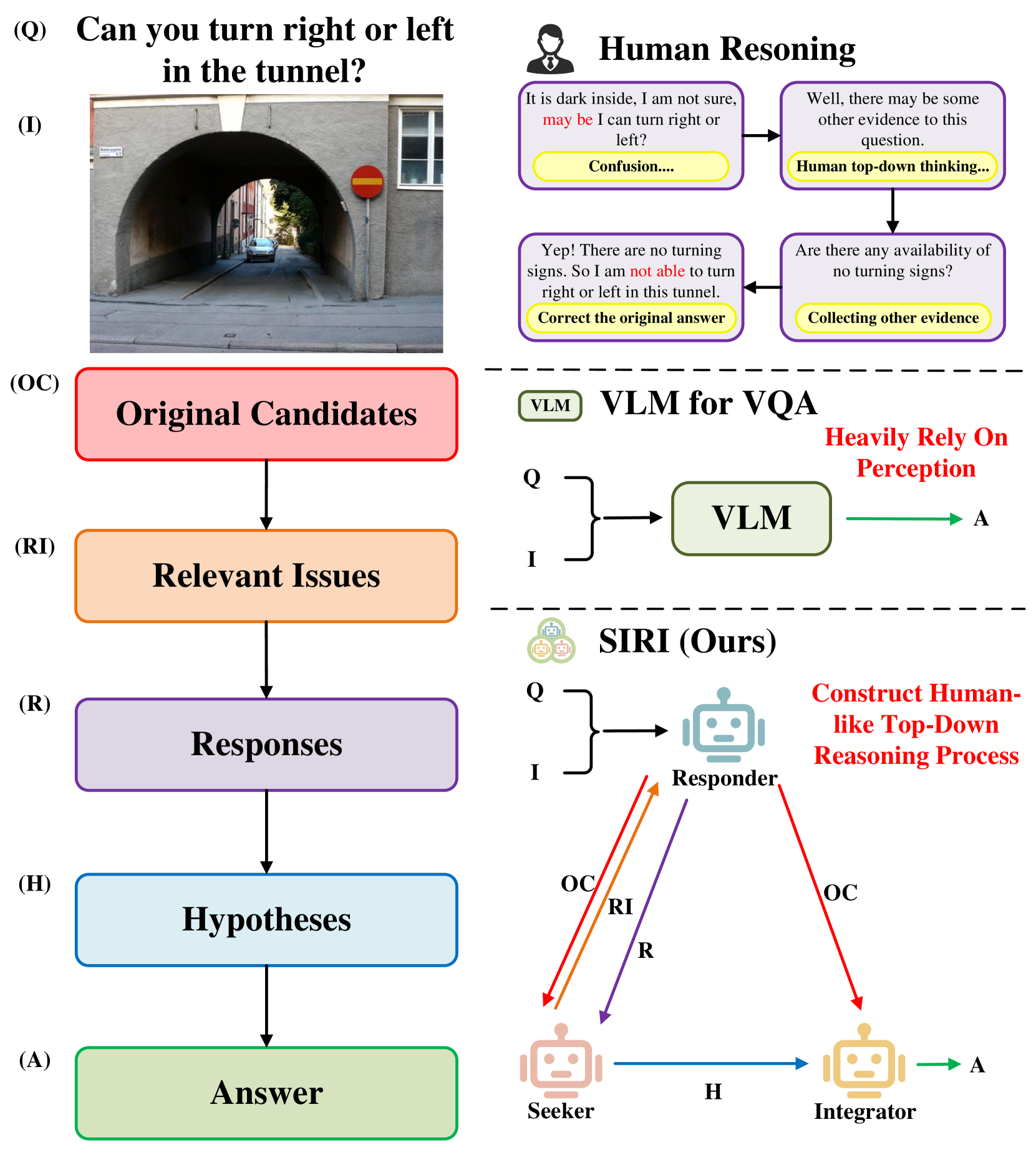
Recently, several methods have been proposed to augment large Vision Language Models (VLMs) for Visual Question Answering (VQA) simplicity by incorporating external knowledge from knowledge bases or visual clues derived from question decomposition. Although having achieved promising results, these methods still suffer from the challenge that VLMs cannot inherently understand the incorporated knowledge and might fail to generate the optimal answers. Contrarily, human cognition engages visual questions through a top-down reasoning process, systematically exploring relevant issues to derive a comprehensive answer. This not only facilitates an accurate answer but also provides a transparent rationale for the decision-making pathway. Motivated by this cognitive mechanism, we introduce a novel, explainable multi-agent collaboration framework designed to imitate human-like top-down reasoning by leveraging the expansive knowledge of Large Language Models (LLMs). Our framework comprises three agents, i.e., Responder, Seeker, and Integrator, each contributing uniquely to the top-down reasoning process. The VLM-based Responder generates the answer candidates for the question and gives responses to other issues. The Seeker, primarily based on LLM, identifies relevant issues related to the question to inform the Responder and constructs a Multi-View Knowledge Base (MVKB) for the given visual scene by leveraging the understanding capabilities of LLM. The Integrator agent combines information from the Seeker and the Responder to produce the final VQA answer. Through this collaboration mechanism, our framework explicitly constructs an MVKB for a specific visual scene and reasons answers in a top-down reasoning process. Extensive and comprehensive evaluations on diverse VQA datasets and VLMs demonstrate the superior applicability and interpretability of our framework over the existing compared methods.
Create account to get full access
Overview
- This paper proposes a multi-agent approach for visual question answering (VQA) that aims to provide more explainable reasoning.
- The key idea is to break down the VQA task into a sequence of sub-tasks, each handled by a specialized agent, to mimic human top-down reasoning.
- The agents collaborate to arrive at the final answer, and their individual reasoning steps are made transparent to enhance the overall explainability of the system.
Plain English Explanation
The paper introduces a new way to approach the task of visual question answering (VQA), which is about answering questions about images. The traditional approach to VQA often uses a single, complex model that tries to do everything at once.
Instead, the researchers propose breaking down the VQA task into a series of smaller, more specialized sub-tasks, each handled by its own "agent." These agents work together in a coordinated way to arrive at the final answer. The key advantage of this approach is that it makes the reasoning process more explainable - you can see how each agent contributed to the final result, rather than just getting a black-box answer.
The idea is to mimic how humans might approach a VQA problem - we tend to break it down into a sequence of steps, using different kinds of knowledge and reasoning at each stage. The paper's multi-agent system aims to capture this top-down, step-by-step reasoning process in a way that is more transparent and understandable.
Technical Explanation
The paper introduces a multi-agent approach for visual question answering that aims to provide more explainable reasoning. The key idea is to break down the VQA task into a sequence of sub-tasks, each handled by a specialized agent, in order to mimic human top-down reasoning.
The architecture consists of multiple agents, each responsible for a specific sub-task, such as question understanding, visual reasoning, and answer generation. These agents collaborate to arrive at the final answer, and their individual reasoning steps are made transparent to enhance the overall explainability of the system.
The paper evaluates this approach on standard VQA datasets and shows that it outperforms traditional end-to-end VQA models in terms of both accuracy and explainability. The modular design allows the system to better handle complex questions that require a sequence of reasoning steps, and the transparency of the agents' reasoning makes it easier for users to understand how the final answer was derived.
Critical Analysis
The paper presents a promising approach to improving the explainability of visual question answering systems, but it also raises some potential concerns and areas for further research:
-
The modular design introduces additional complexity, as the coordination and communication between agents needs to be carefully managed. The paper does not provide a detailed analysis of how this inter-agent collaboration works in practice.
-
The evaluation is limited to standard VQA datasets, which may not fully capture the kinds of real-world, open-ended questions that users would ask. Further testing on more diverse and challenging datasets would be valuable.
-
The paper does not address the issue of agent bias or failure - what happens if one of the specialized agents makes an incorrect inference or decision? The overall system's robustness to such failure modes should be considered.
-
While the transparency of the agents' reasoning is a key advantage, the paper does not explore whether users find this explanation format truly intuitive and easy to understand. User studies could provide valuable insights in this regard.
Conclusion
This paper presents an innovative multi-agent approach to visual question answering that aims to provide more explainable reasoning by breaking down the task into a sequence of specialized sub-tasks. The modular design and transparent agent-based reasoning offer promising avenues for improving the interpretability of VQA systems, which could have important implications for their real-world adoption and trustworthiness.
However, the approach also raises some technical and practical challenges that warrant further investigation. Exploring the system's robustness, scalability, and user-friendliness will be crucial next steps in advancing this line of research and bringing it closer to practical application.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Disentangling Knowledge-based and Visual Reasoning by Question Decomposition in KB-VQA
Elham J. Barezi, Parisa Kordjamshidi
0
0
We study the Knowledge-Based visual question-answering problem, for which given a question, the models need to ground it into the visual modality to find the answer. Although many recent works use question-dependent captioners to verbalize the given image and use Large Language Models to solve the VQA problem, the research results show they are not reasonably performing for multi-hop questions. Our study shows that replacing a complex question with several simpler questions helps to extract more relevant information from the image and provide a stronger comprehension of it. Moreover, we analyze the decomposed questions to find out the modality of the information that is required to answer them and use a captioner for the visual questions and LLMs as a general knowledge source for the non-visual KB-based questions. Our results demonstrate the positive impact of using simple questions before retrieving visual or non-visual information. We have provided results and analysis on three well-known VQA datasets including OKVQA, A-OKVQA, and KRVQA, and achieved up to 2% improvement in accuracy.
6/28/2024
Find The Gap: Knowledge Base Reasoning For Visual Question Answering
Elham J. Barezi, Parisa Kordjamshidi
0
0
We analyze knowledge-based visual question answering, for which given a question, the models need to ground it into the visual modality and retrieve the relevant knowledge from a given large knowledge base (KB) to be able to answer. Our analysis has two folds, one based on designing neural architectures and training them from scratch, and another based on large pre-trained language models (LLMs). Our research questions are: 1) Can we effectively augment models by explicit supervised retrieval of the relevant KB information to solve the KB-VQA problem? 2) How do task-specific and LLM-based models perform in the integration of visual and external knowledge, and multi-hop reasoning over both sources of information? 3) Is the implicit knowledge of LLMs sufficient for KB-VQA and to what extent it can replace the explicit KB? Our results demonstrate the positive impact of empowering task-specific and LLM models with supervised external and visual knowledge retrieval models. Our findings show that though LLMs are stronger in 1-hop reasoning, they suffer in 2-hop reasoning in comparison with our fine-tuned NN model even if the relevant information from both modalities is available to the model. Moreover, we observed that LLM models outperform the NN model for KB-related questions which confirms the effectiveness of implicit knowledge in LLMs however, they do not alleviate the need for external KB.
4/17/2024

InsightSee: Advancing Multi-agent Vision-Language Models for Enhanced Visual Understanding
Huaxiang Zhang, Yaojia Mu, Guo-Niu Zhu, Zhongxue Gan
0
0
Accurate visual understanding is imperative for advancing autonomous systems and intelligent robots. Despite the powerful capabilities of vision-language models (VLMs) in processing complex visual scenes, precisely recognizing obscured or ambiguously presented visual elements remains challenging. To tackle such issues, this paper proposes InsightSee, a multi-agent framework to enhance VLMs' interpretative capabilities in handling complex visual understanding scenarios. The framework comprises a description agent, two reasoning agents, and a decision agent, which are integrated to refine the process of visual information interpretation. The design of these agents and the mechanisms by which they can be enhanced in visual information processing are presented. Experimental results demonstrate that the InsightSee framework not only boosts performance on specific visual tasks but also retains the original models' strength. The proposed framework outperforms state-of-the-art algorithms in 6 out of 9 benchmark tests, with a substantial advancement in multimodal understanding.
6/3/2024

Precision Empowers, Excess Distracts: Visual Question Answering With Dynamically Infused Knowledge In Language Models
Manas Jhalani, Annervaz K M, Pushpak Bhattacharyya
0
0
In the realm of multimodal tasks, Visual Question Answering (VQA) plays a crucial role by addressing natural language questions grounded in visual content. Knowledge-Based Visual Question Answering (KBVQA) advances this concept by adding external knowledge along with images to respond to questions. We introduce an approach for KBVQA, augmenting the existing vision-language transformer encoder-decoder (OFA) model. Our main contribution involves enhancing questions by incorporating relevant external knowledge extracted from knowledge graphs, using a dynamic triple extraction method. We supply a flexible number of triples from the knowledge graph as context, tailored to meet the requirements for answering the question. Our model, enriched with knowledge, demonstrates an average improvement of 4.75% in Exact Match Score over the state-of-the-art on three different KBVQA datasets. Through experiments and analysis, we demonstrate that furnishing variable triples for each question improves the reasoning capabilities of the language model in contrast to supplying a fixed number of triples. This is illustrated even for recent large language models. Additionally, we highlight the model's generalization capability by showcasing its SOTA-beating performance on a small dataset, achieved through straightforward fine-tuning.
6/17/2024