Instances and Labels: Hierarchy-aware Joint Supervised Contrastive Learning for Hierarchical Multi-Label Text Classification

0
👨🏫
Sign in to get full access
Overview
- This paper proposes a new method called HJCL (Hierarchy-aware Joint Supervised Contrastive Learning) for hierarchical multi-label text classification (HMTC).
- HMTC aims to utilize the label hierarchy in multi-label classification tasks.
- Recent approaches to HMTC have used contrastive learning on generated samples to bring text and label embeddings closer, but this can introduce noise by ignoring the correlation between similar samples.
- HJCL addresses this challenge by employing both instance-wise and label-wise contrastive learning techniques, and carefully constructing batches to fulfill the contrastive learning objective.
Plain English Explanation
Imagine you have a large collection of documents, each of which can be assigned to multiple categories in a hierarchical structure. For example, a document about "Artificial Intelligence" could be classified under the broader category of "Computer Science," which is itself a subcategory of "Technology." Hierarchical multi-label text classification is the task of accurately assigning these hierarchical labels to documents.
Recent approaches have tried to improve this task by using a technique called "contrastive learning." This involves generating new samples and using them to bring the text and label embeddings (mathematical representations) closer together. However, this generation process can sometimes introduce unwanted "noise" by not considering the relationships between similar samples.
To address this, the researchers propose a new method called HJCL. Instead of just generating new samples, HJCL uses two different contrastive learning techniques - one that focuses on the individual documents, and one that focuses on the hierarchical labels. By carefully constructing the batches of data used for training, HJCL is able to effectively learn the connections between the text and the hierarchical label structure.
Technical Explanation
The key innovation of the HJCL method is its use of both instance-wise and label-wise contrastive learning techniques. In instance-wise contrastive learning, the model learns to bring text embeddings of similar documents closer together, while pushing apart embeddings of dissimilar documents. This helps the model capture the relationships between the text content.
In label-wise contrastive learning, the model learns to bring the text embeddings closer to the embeddings of their correct hierarchical labels, while pushing them away from incorrect labels. This directly addresses the challenge of utilizing the label hierarchy in HMTC.
To ensure the contrastive learning objective is fulfilled, the researchers carefully construct the training batches. Each batch contains a mix of similar and dissimilar document-label pairs, allowing the model to learn the desired contrasts.
The researchers evaluate HJCL on four HMTC datasets and show that it outperforms previous state-of-the-art methods. This demonstrates the effectiveness of the hierarchical contrastive learning approach for this task.
Critical Analysis
One potential limitation of the HJCL method is that it relies on carefully designed batch construction to achieve good performance. This may make it more challenging to scale to very large datasets or real-world production scenarios. The authors mention this as an area for future research, exploring ways to make the batch construction process more efficient or automated.
Additionally, while the results on the evaluated datasets are promising, it would be valuable to see how HJCL performs on a wider range of HMTC tasks and domains. The researchers mention that the effectiveness of contrastive learning on HMTC is an underexplored area, so further research and validation across diverse settings would help solidify the conclusions.
It would also be interesting to see a comparison of HJCL to other recent approaches that aim to leverage the label hierarchy, such as those using adversarial training or hybrid techniques. This could provide additional insights into the strengths and limitations of the contrastive learning approach for HMTC.
Conclusion
The HJCL method proposed in this paper represents a novel and promising approach to hierarchical multi-label text classification. By combining instance-wise and label-wise contrastive learning techniques, HJCL is able to effectively capture the relationships between text content and hierarchical label structure. The empirical results demonstrate the effectiveness of this approach, though further research is needed to address potential scaling challenges and compare HJCL to other state-of-the-art HMTC methods. Overall, this work contributes valuable insights to the ongoing effort to improve the performance of HMTC systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
👨🏫
0
Instances and Labels: Hierarchy-aware Joint Supervised Contrastive Learning for Hierarchical Multi-Label Text Classification
Simon Yu, Jie He, V'ictor Guti'errez-Basulto, Jeff Z. Pan
Hierarchical multi-label text classification (HMTC) aims at utilizing a label hierarchy in multi-label classification. Recent approaches to HMTC deal with the problem of imposing an over-constrained premise on the output space by using contrastive learning on generated samples in a semi-supervised manner to bring text and label embeddings closer. However, the generation of samples tends to introduce noise as it ignores the correlation between similar samples in the same batch. One solution to this issue is supervised contrastive learning, but it remains an underexplored topic in HMTC due to its complex structured labels. To overcome this challenge, we propose $textbf{HJCL}$, a $textbf{H}$ierarchy-aware $textbf{J}$oint Supervised $textbf{C}$ontrastive $textbf{L}$earning method that bridges the gap between supervised contrastive learning and HMTC. Specifically, we employ both instance-wise and label-wise contrastive learning techniques and carefully construct batches to fulfill the contrastive learning objective. Extensive experiments on four multi-path HMTC datasets demonstrate that HJCL achieves promising results and the effectiveness of Contrastive Learning on HMTC.
Read more6/21/2024
0
HiLight: A Hierarchy-aware Light Global Model with Hierarchical Local ConTrastive Learning
Zhijian Chen, Zhonghua Li, Jianxin Yang, Ye Qi
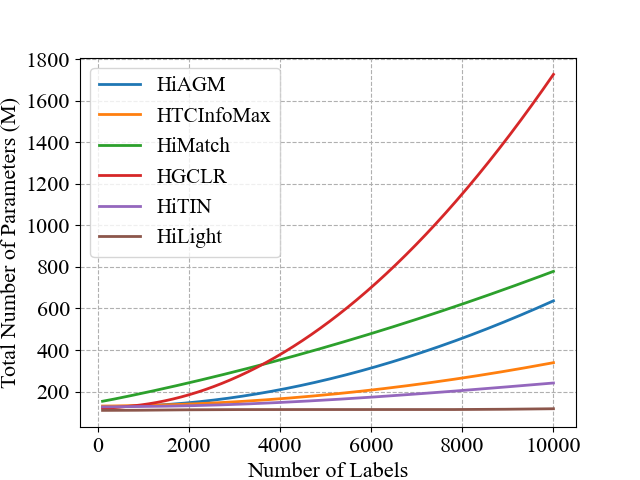
Hierarchical text classification (HTC) is a special sub-task of multi-label classification (MLC) whose taxonomy is constructed as a tree and each sample is assigned with at least one path in the tree. Latest HTC models contain three modules: a text encoder, a structure encoder and a multi-label classification head. Specially, the structure encoder is designed to encode the hierarchy of taxonomy. However, the structure encoder has scale problem. As the taxonomy size increases, the learnable parameters of recent HTC works grow rapidly. Recursive regularization is another widely-used method to introduce hierarchical information but it has collapse problem and generally relaxed by assigning with a small weight (ie. 1e-6). In this paper, we propose a Hierarchy-aware Light Global model with Hierarchical local conTrastive learning (HiLight), a lightweight and efficient global model only consisting of a text encoder and a multi-label classification head. We propose a new learning task to introduce the hierarchical information, called Hierarchical Local Contrastive Learning (HiLCL). Extensive experiments are conducted on two benchmark datasets to demonstrate the effectiveness of our model.
Read more8/13/2024

0
Retrieval-style In-Context Learning for Few-shot Hierarchical Text Classification
Huiyao Chen, Yu Zhao, Zulong Chen, Mengjia Wang, Liangyue Li, Meishan Zhang, Min Zhang
Hierarchical text classification (HTC) is an important task with broad applications, while few-shot HTC has gained increasing interest recently. While in-context learning (ICL) with large language models (LLMs) has achieved significant success in few-shot learning, it is not as effective for HTC because of the expansive hierarchical label sets and extremely-ambiguous labels. In this work, we introduce the first ICL-based framework with LLM for few-shot HTC. We exploit a retrieval database to identify relevant demonstrations, and an iterative policy to manage multi-layer hierarchical labels. Particularly, we equip the retrieval database with HTC label-aware representations for the input texts, which is achieved by continual training on a pretrained language model with masked language modeling (MLM), layer-wise classification (CLS, specifically for HTC), and a novel divergent contrastive learning (DCL, mainly for adjacent semantically-similar labels) objective. Experimental results on three benchmark datasets demonstrate superior performance of our method, and we can achieve state-of-the-art results in few-shot HTC.
Read more7/2/2024
0
Modeling Text-Label Alignment for Hierarchical Text Classification
Ashish Kumar, Durga Toshniwal
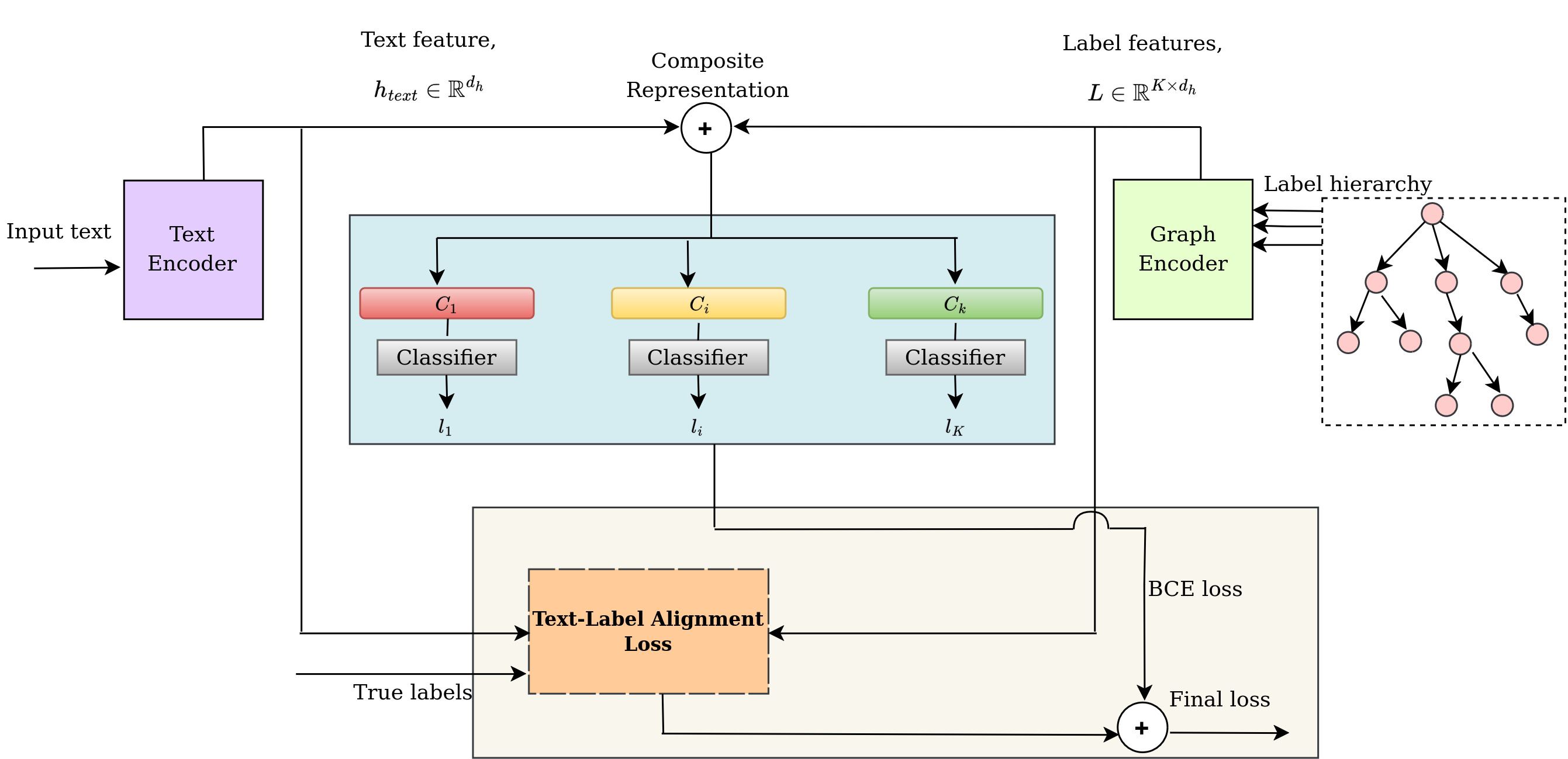
Hierarchical Text Classification (HTC) aims to categorize text data based on a structured label hierarchy, resulting in predicted labels forming a sub-hierarchy tree. The semantics of the text should align with the semantics of the labels in this sub-hierarchy. With the sub-hierarchy changing for each sample, the dynamic nature of text-label alignment poses challenges for existing methods, which typically process text and labels independently. To overcome this limitation, we propose a Text-Label Alignment (TLA) loss specifically designed to model the alignment between text and labels. We obtain a set of negative labels for a given text and its positive label set. By leveraging contrastive learning, the TLA loss pulls the text closer to its positive label and pushes it away from its negative label in the embedding space. This process aligns text representations with related labels while distancing them from unrelated ones. Building upon this framework, we introduce the Hierarchical Text-Label Alignment (HTLA) model, which leverages BERT as the text encoder and GPTrans as the graph encoder and integrates text-label embeddings to generate hierarchy-aware representations. Experimental results on benchmark datasets and comparison with existing baselines demonstrate the effectiveness of HTLA for HTC.
Read more9/4/2024