Instant 3D Human Avatar Generation using Image Diffusion Models
2406.07516
0
0

Abstract
We present AvatarPopUp, a method for fast, high quality 3D human avatar generation from different input modalities, such as images and text prompts and with control over the generated pose and shape. The common theme is the use of diffusion-based image generation networks that are specialized for each particular task, followed by a 3D lifting network. We purposefully decouple the generation from the 3D modeling which allow us to leverage powerful image synthesis priors, trained on billions of text-image pairs. We fine-tune latent diffusion networks with additional image conditioning to solve tasks such as image generation and back-view prediction, and to support qualitatively different multiple 3D hypotheses. Our partial fine-tuning approach allows to adapt the networks for each task without inducing catastrophic forgetting. In our experiments, we demonstrate that our method produces accurate, high-quality 3D avatars with diverse appearance that respect the multimodal text, image, and body control signals. Our approach can produce a 3D model in as few as 2 seconds, a four orders of magnitude speedup w.r.t. the vast majority of existing methods, most of which solve only a subset of our tasks, and with fewer controls, thus enabling applications that require the controlled 3D generation of human avatars at scale. The project website can be found at https://www.nikoskolot.com/avatarpopup/.
Create account to get full access
Overview
- This paper presents a novel method for generating 3D human avatars from a single input image using diffusion models.
- The proposed approach, called Instant 3D Human Avatar Generation (I3DAG), can create high-quality 3D avatars in real-time, without requiring complex 3D reconstruction or rigging.
- The method leverages the powerful image-to-image translation capabilities of diffusion models, which have shown impressive results in tasks like text-to-image and image-to-image translation.
Plain English Explanation
Creating 3D human avatars, or digital representations of people, is a challenging task that typically requires complex 3D modeling and animation techniques. This paper introduces a new method that simplifies the process by using a type of AI model called a diffusion model.
Diffusion models are a powerful type of machine learning algorithm that have been used to generate realistic images from text descriptions. In this case, the researchers have adapted diffusion models to generate 3D human avatars directly from a single 2D photograph.
The key idea is that the diffusion model can learn to translate the 2D image into a 3D representation of the person, including their shape, pose, and even facial features. This happens in an "instant" - the avatar is generated in real-time, without the need for laborious 3D modeling or rigging.
The resulting avatars are highly realistic and can be used for a variety of applications, such as virtual reality, video games, and even online communication. This technology has the potential to make 3D avatar creation much more accessible and widespread.
Technical Explanation
The I3DAG method takes a single 2D input image and generates a 3D human avatar in real-time. It does this by leveraging the power of diffusion models, a type of generative AI that has shown impressive results in tasks like text-to-image and image-to-image translation.
The key technical insights are:
-
Diffusion-based 3D Generation: The researchers adapted the diffusion model architecture to generate 3D data directly, rather than just 2D images. This allows the model to learn the mapping from 2D images to 3D avatar representations.
-
Iterative Reconstruction: The 3D avatar is generated through an iterative reconstruction process, where the model progressively refines the 3D shape, pose, and appearance of the avatar over multiple steps.
-
Robust Conditioning: The model is carefully conditioned on various input modalities, including the 2D image, 2D keypoints, and other auxiliary information, to ensure the generated avatars are high-quality and faithful to the input.
The researchers evaluated their method on several benchmarks and showed that I3DAG can generate avatars that are more realistic and accurate compared to previous state-of-the-art approaches. The real-time performance and single-image input also make this a highly practical and accessible solution for 3D avatar creation.
Critical Analysis
The I3DAG method represents an impressive advancement in the field of 3D human avatar generation. By leveraging the power of diffusion models, the researchers have addressed several key challenges, such as the need for complex 3D modeling and the requirement for multiple input images.
However, the paper does acknowledge several limitations and areas for future work:
-
Pose and Occlusion Handling: While the method can handle a variety of poses, it may struggle with more challenging cases, such as significant occlusions or extreme angles. Further research is needed to improve the model's robustness in these scenarios.
-
Texture and Material Modeling: The current focus is on generating the 3D shape and pose of the avatar, but the texture and material properties are relatively simple. Improving the realism of the avatar's appearance is an important next step.
-
Scalability and Personalization: The paper demonstrates the ability to generate avatars for individual users, but scaling this to larger populations and allowing for more personalization may require additional research and development.
Additionally, while the real-time performance and single-image input are significant advantages, there may be concerns about the ethical implications of such technology, such as potential misuse or privacy issues. Careful consideration of these concerns will be important as the technology advances.
Conclusion
The Instant 3D Human Avatar Generation (I3DAG) method presented in this paper represents a significant advancement in the field of 3D human avatar generation. By leveraging the power of diffusion models, the researchers have developed a practical and accessible solution for creating realistic, personalized 3D avatars from a single input image.
This technology has the potential to revolutionize numerous applications, including virtual reality, video games, and online communication. By making 3D avatar creation more accessible and efficient, I3DAG could pave the way for more immersive and engaging digital experiences.
While the method has some limitations and areas for further research, the core innovation and promising results demonstrate the potential of diffusion models for 3D content generation. As the field continues to evolve, it will be exciting to see how this technology is applied and expanded in the future.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🤿
Morphable Diffusion: 3D-Consistent Diffusion for Single-image Avatar Creation
Xiyi Chen, Marko Mihajlovic, Shaofei Wang, Sergey Prokudin, Siyu Tang
0
0
Recent advances in generative diffusion models have enabled the previously unfeasible capability of generating 3D assets from a single input image or a text prompt. In this work, we aim to enhance the quality and functionality of these models for the task of creating controllable, photorealistic human avatars. We achieve this by integrating a 3D morphable model into the state-of-the-art multi-view-consistent diffusion approach. We demonstrate that accurate conditioning of a generative pipeline on the articulated 3D model enhances the baseline model performance on the task of novel view synthesis from a single image. More importantly, this integration facilitates a seamless and accurate incorporation of facial expression and body pose control into the generation process. To the best of our knowledge, our proposed framework is the first diffusion model to enable the creation of fully 3D-consistent, animatable, and photorealistic human avatars from a single image of an unseen subject; extensive quantitative and qualitative evaluations demonstrate the advantages of our approach over existing state-of-the-art avatar creation models on both novel view and novel expression synthesis tasks. The code for our project is publicly available.
4/3/2024

Human 3Diffusion: Realistic Avatar Creation via Explicit 3D Consistent Diffusion Models
Yuxuan Xue, Xianghui Xie, Riccardo Marin, Gerard Pons-Moll
0
0
Creating realistic avatars from a single RGB image is an attractive yet challenging problem. Due to its ill-posed nature, recent works leverage powerful prior from 2D diffusion models pretrained on large datasets. Although 2D diffusion models demonstrate strong generalization capability, they cannot provide multi-view shape priors with guaranteed 3D consistency. We propose Human 3Diffusion: Realistic Avatar Creation via Explicit 3D Consistent Diffusion. Our key insight is that 2D multi-view diffusion and 3D reconstruction models provide complementary information for each other, and by coupling them in a tight manner, we can fully leverage the potential of both models. We introduce a novel image-conditioned generative 3D Gaussian Splats reconstruction model that leverages the priors from 2D multi-view diffusion models, and provides an explicit 3D representation, which further guides the 2D reverse sampling process to have better 3D consistency. Experiments show that our proposed framework outperforms state-of-the-art methods and enables the creation of realistic avatars from a single RGB image, achieving high-fidelity in both geometry and appearance. Extensive ablations also validate the efficacy of our design, (1) multi-view 2D priors conditioning in generative 3D reconstruction and (2) consistency refinement of sampling trajectory via the explicit 3D representation. Our code and models will be released on https://yuxuan-xue.com/human-3diffusion.
6/13/2024
✨
FitDiff: Robust monocular 3D facial shape and reflectance estimation using Diffusion Models
Stathis Galanakis, Alexandros Lattas, Stylianos Moschoglou, Stefanos Zafeiriou
0
0
The remarkable progress in 3D face reconstruction has resulted in high-detail and photorealistic facial representations. Recently, Diffusion Models have revolutionized the capabilities of generative methods by surpassing the performance of GANs. In this work, we present FitDiff, a diffusion-based 3D facial avatar generative model. Leveraging diffusion principles, our model accurately generates relightable facial avatars, utilizing an identity embedding extracted from an in-the-wild 2D facial image. The introduced multi-modal diffusion model is the first to concurrently output facial reflectance maps (diffuse and specular albedo and normals) and shapes, showcasing great generalization capabilities. It is solely trained on an annotated subset of a public facial dataset, paired with 3D reconstructions. We revisit the typical 3D facial fitting approach by guiding a reverse diffusion process using perceptual and face recognition losses. Being the first 3D LDM conditioned on face recognition embeddings, FitDiff reconstructs relightable human avatars, that can be used as-is in common rendering engines, starting only from an unconstrained facial image, and achieving state-of-the-art performance.
6/5/2024
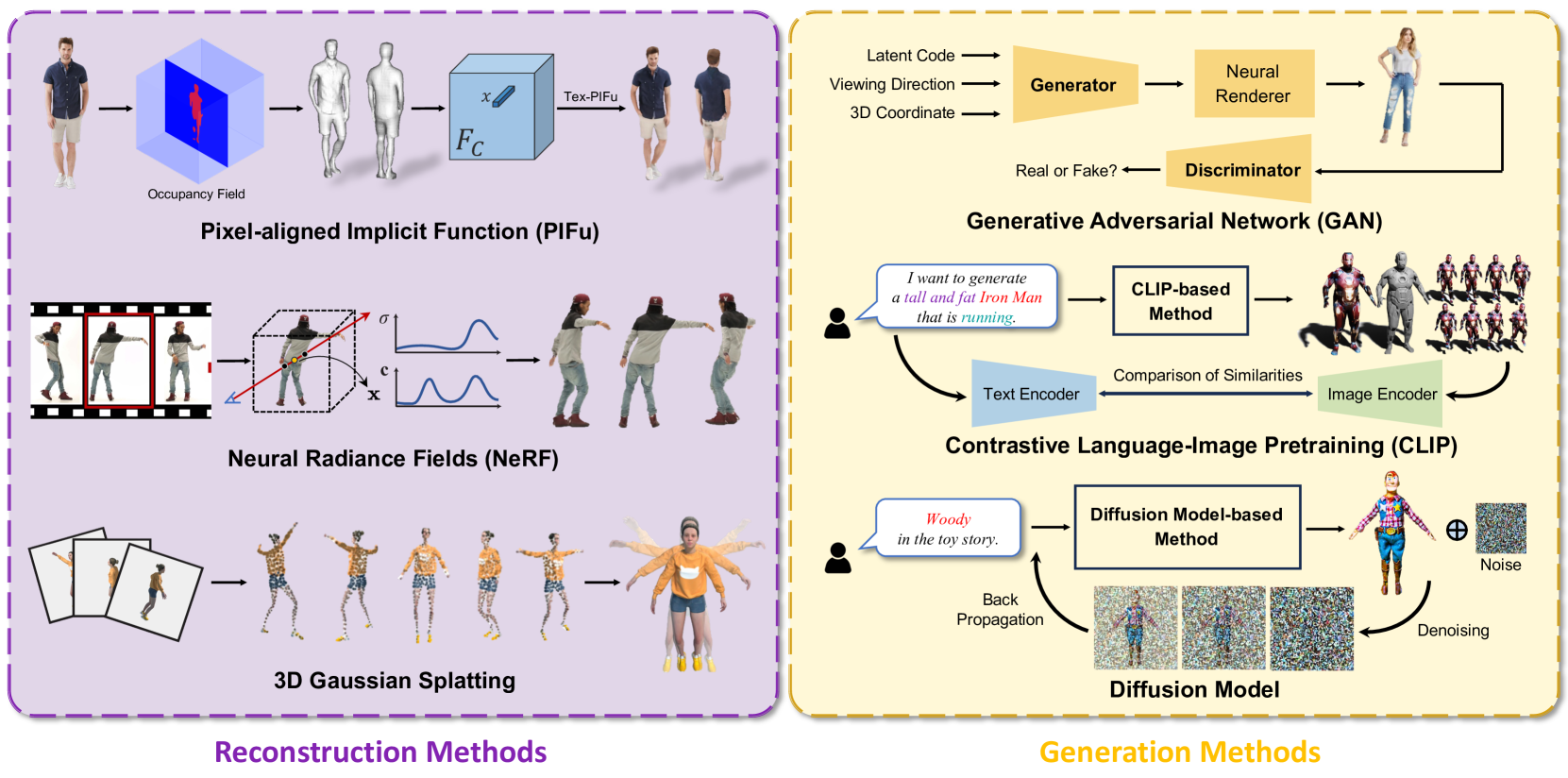
A Survey on 3D Human Avatar Modeling -- From Reconstruction to Generation
Ruihe Wang, Yukang Cao, Kai Han, Kwan-Yee K. Wong
0
0
3D modeling has long been an important area in computer vision and computer graphics. Recently, thanks to the breakthroughs in neural representations and generative models, we witnessed a rapid development of 3D modeling. 3D human modeling, lying at the core of many real-world applications, such as gaming and animation, has attracted significant attention. Over the past few years, a large body of work on creating 3D human avatars has been introduced, forming a new and abundant knowledge base for 3D human modeling. The scale of the literature makes it difficult for individuals to keep track of all the works. This survey aims to provide a comprehensive overview of these emerging techniques for 3D human avatar modeling, from both reconstruction and generation perspectives. Firstly, we review representative methods for 3D human reconstruction, including methods based on pixel-aligned implicit function, neural radiance field, and 3D Gaussian Splatting, etc. We then summarize representative methods for 3D human generation, especially those using large language models like CLIP, diffusion models, and various 3D representations, which demonstrate state-of-the-art performance. Finally, we discuss our reflection on existing methods and open challenges for 3D human avatar modeling, shedding light on future research.
6/7/2024