Integrating Explanations in Learning LTL Specifications from Demonstrations

0

Sign in to get full access
Overview
- This paper proposes a novel approach for learning Linear Temporal Logic (LTL) specifications from demonstrations, with the key innovation of integrating explanations from the user.
- LTL specifications are a way to formally describe desired behaviors of a system over time, which is useful for tasks like robot control and program synthesis.
- The authors develop a framework that allows a user to provide natural language explanations alongside demonstrations, which helps the model learn more accurate and interpretable LTL specifications.
- The paper demonstrates the effectiveness of this approach through experiments on several benchmark tasks.
Plain English Explanation
The paper tackles the problem of learning formal rules, called LTL specifications, that describe how a system should behave over time. This is an important task for applications like controlling robots or automatically generating computer programs.
Traditionally, learning these rules just from observing example behaviors can be challenging, as the system has to infer the underlying logic from limited data. The key innovation in this work is allowing the user to provide natural language explanations alongside the demonstration examples.
Imagine you're teaching a robot how to navigate a house. You could show it examples of moving from the living room to the kitchen, but also explain in words the rules you want it to follow, like "always go through the hallway" or "never enter the bathroom unless the bedroom door is closed." By incorporating these verbal explanations, the learning model can better understand the intended behavior and generate more accurate and interpretable rules.
The paper demonstrates that this approach leads to LTL specifications that are more aligned with human intent, compared to learning just from demonstrations alone. This could make it easier to deploy autonomous systems that reliably behave as desired.
Technical Explanation
The paper presents a framework for learning LTL specifications from a combination of demonstrations and natural language explanations provided by a human user. The authors formulate this as a structured prediction task, where the goal is to generate an LTL formula that best explains the given demonstration traces and textual descriptions.
The core of their approach is a neural network architecture that takes in the demonstrations, the corresponding explanations, and background knowledge about the environment, and outputs an LTL formula. This architecture includes components for encoding the demonstrations, processing the natural language explanations, and then jointly reasoning about the two inputs to produce the final LTL specification.
The authors evaluate their method on several benchmark tasks, including a simulated robot navigation domain and a program synthesis domain. They show that incorporating the user explanations leads to more accurate and interpretable LTL specifications, compared to learning from demonstrations alone or using alternative techniques for combining demonstrations and language.
Critical Analysis
The paper makes a compelling case for the value of integrating natural language explanations into the process of learning formal behavioral rules from demonstrations. The experimental results demonstrate clear performance improvements, suggesting this is a promising direction for making autonomous systems more aligned with human intent.
That said, the paper does acknowledge some limitations of the current approach. For example, the natural language processing component relies on relatively simple techniques, and may struggle with more complex or ambiguous explanations. Additionally, the experiments are conducted in relatively constrained domains, and it's unclear how well the approach would scale to more open-ended, real-world settings.
Further research could explore ways to make the language understanding more robust, potentially by leveraging large language models or interactive clarification. There may also be opportunities to extend the framework to handle more nuanced forms of feedback and guidance from users.
Overall, this work represents an important step towards developing autonomous systems that can fluidly interact with humans and reliably behave in accordance with their high-level objectives. Continuing to bridge the gap between formal specifications and natural language promises to be a fruitful area of study.
Conclusion
This paper presents a novel approach for learning LTL specifications from a combination of demonstrations and natural language explanations provided by a human user. By allowing the user to supply verbal guidance alongside the example behaviors, the learning model can generate more accurate and interpretable formal rules that better capture the intended system behavior.
The experimental results demonstrate the effectiveness of this approach, suggesting it could be a valuable tool for deploying autonomous systems that reliably act in accordance with human objectives. While the current framework has some limitations, this work represents an important step towards bridging the gap between formal specifications and natural language interaction, with promising implications for a wide range of applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Integrating Explanations in Learning LTL Specifications from Demonstrations
Ashutosh Gupta, John Komp, Abhay Singh Rajput, Krishna Shankaranarayanan, Ashutosh Trivedi, Namrita Varshney
This paper investigates whether recent advances in Large Language Models (LLMs) can assist in translating human explanations into a format that can robustly support learning Linear Temporal Logic (LTL) from demonstrations. Both LLMs and optimization-based methods can extract LTL specifications from demonstrations; however, they have distinct limitations. LLMs can quickly generate solutions and incorporate human explanations, but their lack of consistency and reliability hampers their applicability in safety-critical domains. On the other hand, optimization-based methods do provide formal guarantees but cannot process natural language explanations and face scalability challenges. We present a principled approach to combining LLMs and optimization-based methods to faithfully translate human explanations and demonstrations into LTL specifications. We have implemented a tool called Janaka based on our approach. Our experiments demonstrate the effectiveness of combining explanations with demonstrations in learning LTL specifications through several case studies.
Read more4/4/2024
🌿
0
Verification and Refinement of Natural Language Explanations through LLM-Symbolic Theorem Proving
Xin Quan, Marco Valentino, Louise A. Dennis, Andr'e Freitas
Natural language explanations have become a proxy for evaluating explainable and multi-step Natural Language Inference (NLI) models. However, assessing the validity of explanations for NLI is challenging as it typically involves the crowd-sourcing of apposite datasets, a process that is time-consuming and prone to logical errors. To address existing limitations, this paper investigates the verification and refinement of natural language explanations through the integration of Large Language Models (LLMs) and Theorem Provers (TPs). Specifically, we present a neuro-symbolic framework, named Explanation-Refiner, that augments a TP with LLMs to generate and formalise explanatory sentences and suggest potential inference strategies for NLI. In turn, the TP is employed to provide formal guarantees on the logical validity of the explanations and to generate feedback for subsequent improvements. We demonstrate how Explanation-Refiner can be jointly used to evaluate explanatory reasoning, autoformalisation, and error correction mechanisms of state-of-the-art LLMs as well as to automatically enhance the quality of human-annotated explanations of variable complexity in different domains.
Read more5/9/2024
🔄
0
LLMs for XAI: Future Directions for Explaining Explanations
Alexandra Zytek, Sara Pid`o, Kalyan Veeramachaneni
In response to the demand for Explainable Artificial Intelligence (XAI), we investigate the use of Large Language Models (LLMs) to transform ML explanations into natural, human-readable narratives. Rather than directly explaining ML models using LLMs, we focus on refining explanations computed using existing XAI algorithms. We outline several research directions, including defining evaluation metrics, prompt design, comparing LLM models, exploring further training methods, and integrating external data. Initial experiments and user study suggest that LLMs offer a promising way to enhance the interpretability and usability of XAI.
Read more5/13/2024
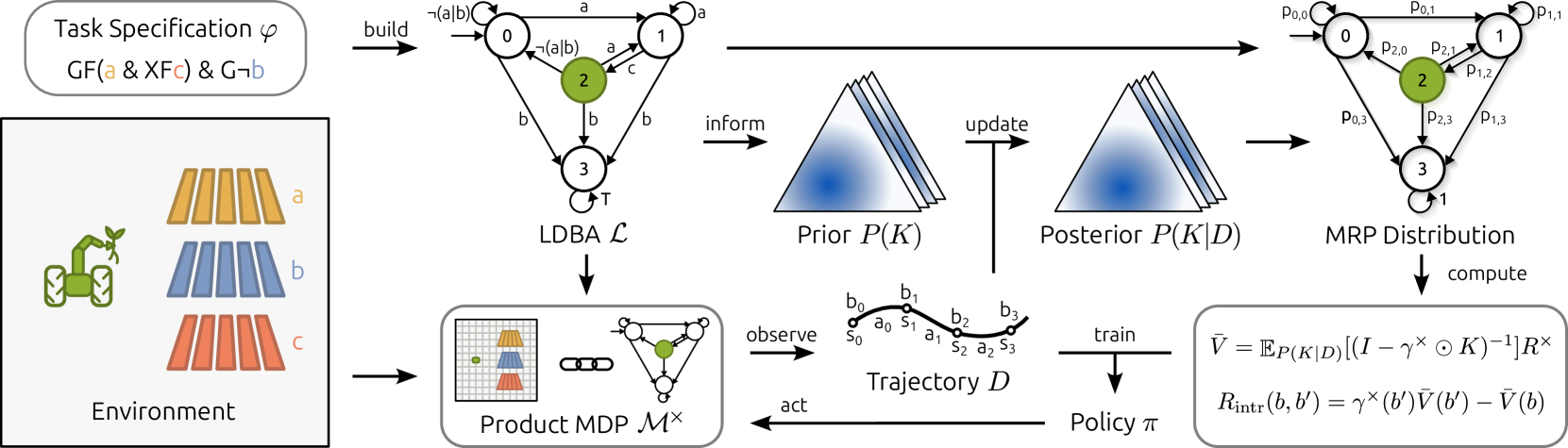
0
Directed Exploration in Reinforcement Learning from Linear Temporal Logic
Marco Bagatella, Andreas Krause, Georg Martius
Linear temporal logic (LTL) is a powerful language for task specification in reinforcement learning, as it allows describing objectives beyond the expressivity of conventional discounted return formulations. Nonetheless, recent works have shown that LTL formulas can be translated into a variable rewarding and discounting scheme, whose optimization produces a policy maximizing a lower bound on the probability of formula satisfaction. However, the synthesized reward signal remains fundamentally sparse, making exploration challenging. We aim to overcome this limitation, which can prevent current algorithms from scaling beyond low-dimensional, short-horizon problems. We show how better exploration can be achieved by further leveraging the LTL specification and casting its corresponding Limit Deterministic Buchi Automaton (LDBA) as a Markov reward process, thus enabling a form of high-level value estimation. By taking a Bayesian perspective over LDBA dynamics and proposing a suitable prior distribution, we show that the values estimated through this procedure can be treated as a shaping potential and mapped to informative intrinsic rewards. Empirically, we demonstrate applications of our method from tabular settings to high-dimensional continuous systems, which have so far represented a significant challenge for LTL-based reinforcement learning algorithms.
Read more8/20/2024