Interpretability Illusions in the Generalization of Simplified Models

0
👁️
Sign in to get full access
Overview
- Researchers investigated the limitations of using simplified model representations like dimensionality reduction to study deep learning systems.
- They found that these simplified proxies can accurately approximate the original model's behavior on the training set, but fail to capture the model's systematic generalization abilities.
- The study used controlled datasets and Transformer models to test how well simplified representations match the original model's behavior, both on in-distribution and out-of-distribution evaluations.
Plain English Explanation
When researchers want to understand how deep learning models work under the hood, they often use simplified representations of the model, such as dimensionality reduction techniques or clustering approaches. The idea is that these simplified versions can provide a clearer picture of the model's inner workings. However, this paper shows that there's an important caveat to this approach.
The researchers found that while these simplified representations can accurately mimic the original model's performance on the training data, they often fail to capture the model's ability to generalize systematically to new, out-of-distribution situations. In other words, the simplified proxies may give a misleading impression of what the full model is capable of.
To demonstrate this, the researchers trained Transformer models on specialized datasets designed to test systematic generalization, like the Dyck balanced-parenthesis language and a code completion task. They then used dimensionality reduction and clustering to create simplified versions of the models, and compared the behavior of the original and simplified models.
Surprisingly, they found cases where the original model could generalize systematically, but the simplified proxies failed to do so. Conversely, they also found cases where the simplified proxies actually generalized better than the original model. These inconsistencies raise doubts about how well the simplified representations can predict a model's behavior in novel situations, as described in this related work.
Technical Explanation
The researchers trained Transformer language models on two specialized datasets designed to test systematic generalization: the Dyck balanced-parenthesis language task, and a code completion task. These datasets have "systematic generalization splits", meaning there are clear structural differences between the training and evaluation data that the models must learn to generalize across.
After training the models, the researchers used dimensionality reduction (via Singular Value Decomposition) and clustering techniques to create simplified representations of the models' hidden states. They then compared the behavior of the original and simplified models, both on the in-distribution training data and on various out-of-distribution generalization tests.
Surprisingly, the researchers found consistent "generalization gaps" - cases where the simplified proxies were more faithful to the original model's behavior on the training data, but less faithful on the generalization tests. This included situations where the original model could generalize systematically, but the simplified proxies failed to do so, as well as the reverse - cases where the simplified proxies generalized better than the original model.
These findings challenge the assumption that simplified model representations can reliably predict the original model's behavior in novel situations. The researchers argue that mechanistic interpretations derived from tools like SVD may have important limitations when it comes to understanding a model's systematic generalization capabilities, as discussed in this related work.
Critical Analysis
The researchers provide a compelling demonstration of the limitations of using simplified model representations to study deep learning systems. Their key insight is that while these simplified proxies may accurately capture a model's performance on the training data, they can fail to reflect the model's true systematic generalization abilities.
One limitation of the study is that it focuses on a relatively narrow set of tasks and model architectures (Transformers on the Dyck and code completion datasets). It would be valuable to see if the same patterns hold for a wider range of model types and problem domains.
Additionally, the researchers do not provide a clear explanation for why the simplified proxies sometimes generalize better than the original models. This deserves further investigation, as it could shed light on the factors that influence systematic generalization in deep learning.
Overall, this paper raises important questions about the reliability of mechanistic interpretations derived from simplified model representations. It suggests that researchers should exercise caution when using these techniques and be mindful of their potential limitations, especially when it comes to understanding a model's ability to generalize in novel situations.
Conclusion
This study highlights a critical caveat in using simplified model representations to study deep learning systems. While these simplified proxies can accurately approximate a model's behavior on the training data, they may fail to capture the model's true systematic generalization capabilities.
The researchers' findings challenge the assumption that tools like dimensionality reduction and clustering can reliably predict how a model will perform in novel, out-of-distribution scenarios. This has important implications for the field of interpretable AI, as it suggests that mechanistic interpretations derived from these simplified representations may not always be faithful to the original model's behavior.
Overall, this paper serves as a cautionary tale for researchers and practitioners who rely on simplified model representations to understand and interpret deep learning systems. It underscores the need for more rigorous and comprehensive evaluation methods that can truly capture a model's generalization abilities, beyond just its performance on the training data.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
👁️
0
Interpretability Illusions in the Generalization of Simplified Models
Dan Friedman, Andrew Lampinen, Lucas Dixon, Danqi Chen, Asma Ghandeharioun
A common method to study deep learning systems is to use simplified model representations--for example, using singular value decomposition to visualize the model's hidden states in a lower dimensional space. This approach assumes that the results of these simplifications are faithful to the original model. Here, we illustrate an important caveat to this assumption: even if the simplified representations can accurately approximate the full model on the training set, they may fail to accurately capture the model's behavior out of distribution. We illustrate this by training Transformer models on controlled datasets with systematic generalization splits, including the Dyck balanced-parenthesis languages and a code completion task. We simplify these models using tools like dimensionality reduction and clustering, and then explicitly test how these simplified proxies match the behavior of the original model. We find consistent generalization gaps: cases in which the simplified proxies are more faithful to the original model on the in-distribution evaluations and less faithful on various tests of systematic generalization. This includes cases where the original model generalizes systematically but the simplified proxies fail, and cases where the simplified proxies generalize better. Together, our results raise questions about the extent to which mechanistic interpretations derived using tools like SVD can reliably predict what a model will do in novel situations.
Read more6/6/2024
0
Representations as Language: An Information-Theoretic Framework for Interpretability
Henry Conklin, Kenny Smith
Large scale neural models show impressive performance across a wide array of linguistic tasks. Despite this they remain, largely, black-boxes - inducing vector-representations of their input that prove difficult to interpret. This limits our ability to understand what they learn, and when the learn it, or describe what kinds of representations generalise well out of distribution. To address this we introduce a novel approach to interpretability that looks at the mapping a model learns from sentences to representations as a kind of language in its own right. In doing so we introduce a set of information-theoretic measures that quantify how structured a model's representations are with respect to its input, and when during training that structure arises. Our measures are fast to compute, grounded in linguistic theory, and can predict which models will generalise best based on their representations. We use these measures to describe two distinct phases of training a transformer: an initial phase of in-distribution learning which reduces task loss, then a second stage where representations becoming robust to noise. Generalisation performance begins to increase during this second phase, drawing a link between generalisation and robustness to noise. Finally we look at how model size affects the structure of the representational space, showing that larger models ultimately compress their representations more than their smaller counterparts.
Read more6/5/2024
🤔
0
It Ain't That Bad: Understanding the Mysterious Performance Drop in OOD Generalization for Generative Transformer Models
Xingcheng Xu, Zihao Pan, Haipeng Zhang, Yanqing Yang
Large language models (LLMs) have achieved remarkable proficiency on solving diverse problems. However, their generalization ability is not always satisfying and the generalization problem is common for generative transformer models in general. Researchers take basic mathematical tasks like n-digit addition or multiplication as important perspectives for investigating their generalization behaviors. It is observed that when training models on n-digit operations (e.g., additions) in which both input operands are n-digit in length, models generalize successfully on unseen n-digit inputs (in-distribution (ID) generalization), but fail miserably on longer, unseen cases (out-of-distribution (OOD) generalization). We bring this unexplained performance drop into attention and ask whether there is systematic OOD generalization. Towards understanding LLMs, we train various smaller language models which may share the same underlying mechanism. We discover that the strong ID generalization stems from structured representations, while behind the unsatisfying OOD performance, the models still exhibit clear learned algebraic structures. Specifically, these models map unseen OOD inputs to outputs with learned equivalence relations in the ID domain, which we call the equivalence generalization. These findings deepen our knowledge regarding the generalizability of generative models including LLMs, and provide insights into potential avenues for improvement.
Read more7/8/2024
0
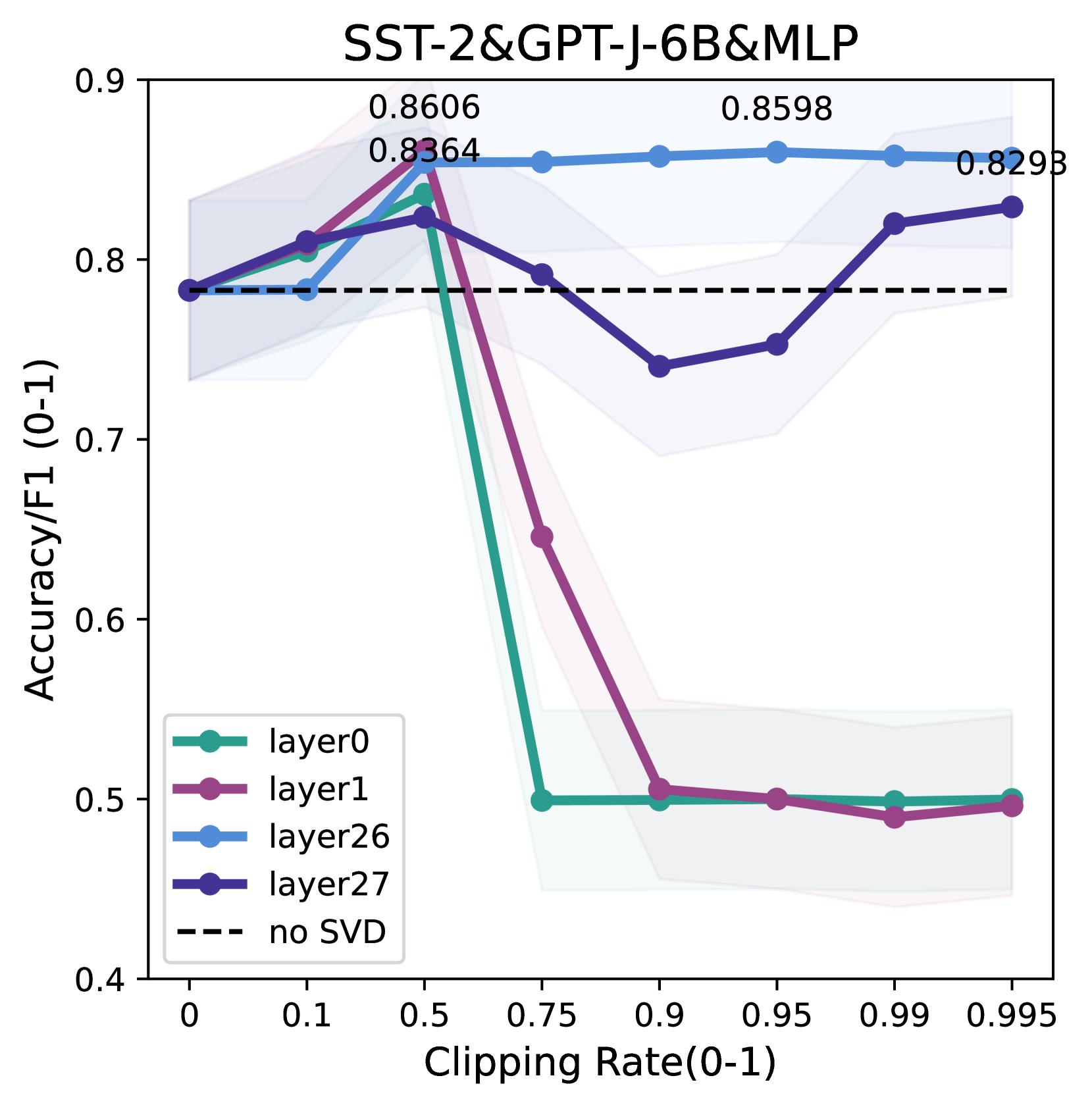
Enhancing In-Context Learning Performance with just SVD-Based Weight Pruning: A Theoretical Perspective
Xinhao Yao, Xiaolin Hu, Shenzhi Yang, Yong Liu
Pre-trained large language models (LLMs) based on Transformer have demonstrated striking in-context learning (ICL) abilities. With a few demonstration input-label pairs, they can predict the label for an unseen input without any parameter updates. In this paper, we show an exciting phenomenon that SVD-based weight pruning can enhance ICL performance, and more surprising, pruning weights in deep layers often results in more stable performance improvements in shallow layers. However, the underlying mechanism of those findings still remains an open question. To reveal those findings, we conduct an in-depth theoretical analysis by presenting the implicit gradient descent (GD) trajectories of ICL and giving the mutual information based generalization bounds of ICL via full implicit GD trajectories. This helps us reasonably explain the surprising experimental findings. Besides, based on all our experimental and theoretical insights, we intuitively propose a simple, model-compression and derivative-free algorithm for downstream tasks in enhancing ICL inference. Experiments on benchmark datasets and open source LLMs display the method effectivenessfootnote{The code is available at url{https://github.com/chen123CtrlS/EnhancingICL_SVDPruning}}.
Read more6/7/2024