On the Semantics of LM Latent Space: A Vocabulary-defined Approach
2401.16184
0
0
🔄
Abstract
Understanding the latent space of language models (LMs) is important for improving the performance and interpretability of LMs. Existing analyses often fail to provide insights that take advantage of the semantic properties of language models and often overlook crucial aspects of language model adaptation. In response, we introduce a pioneering approach called vocabulary-defined semantics, which establishes a reference frame grounded in LM vocabulary within the LM latent space. We propose a novel technique to compute disentangled logits and gradients in latent space, not entangled ones on vocabulary. Further, we perform semantical clustering on data representations as a novel way of LM adaptation. Through extensive experiments across diverse text understanding datasets, our approach outperforms state-of-the-art methods of retrieval-augmented generation and parameter-efficient finetuning, showcasing its effectiveness and efficiency.
Create account to get full access
Overview
- Understanding the inner workings of language models (LMs) is crucial for improving their performance and interpretability.
- Existing analyses often fail to provide disentangled, model-centric insights into LM semantics, and neglect important aspects of LM adaptation.
- The paper introduces a novel method called "vocabulary-defined semantics" to address these shortcomings, establishing a reference frame within the LM latent space for disentangled semantic analysis.
- The approach also proposes a new technique for computing logits, emphasizing differentiability and local isotropy, and introduces a neural clustering module for semantically calibrating data representations during LM adaptation.
- The paper's findings shed light on LM mechanics and offer practical solutions to enhance LM performance and interpretability.
Plain English Explanation
Language models (LMs) are powerful AI systems that can generate human-like text, understand and respond to questions, and assist with a variety of language-related tasks. However, understanding how these models work under the hood is crucial for improving their performance and making them more interpretable.
The paper introduces a new method called "vocabulary-defined semantics" to better understand the inner workings of LMs. Previous analyses often struggled to provide clear, disentangled insights into how LMs understand and represent language semantics. This new approach establishes a reference frame within the LM's latent space, which is the hidden layer of the model where it represents and processes language, to enable a more focused and disentangled analysis.
The paper also proposes a novel technique for computing the model's output logits, which are the raw scores the model uses to make its predictions. This new method emphasizes properties like differentiability and local isotropy, which can improve the model's overall performance and behavior.
Additionally, the researchers introduce a neural clustering module that can be used to semantically calibrate the data representations during the process of fine-tuning, or adapting, the LM to a specific task or domain. This can help the model better understand and adapt to the nuances of the data it's working with.
Through extensive experiments, the researchers show that their approach outperforms state-of-the-art methods in various text understanding tasks, demonstrating its effectiveness and broad applicability. The findings not only shed light on the inner workings of LMs, but also provide practical solutions for enhancing their performance and interpretability.
Technical Explanation
The paper introduces a pioneering method called vocabulary-defined semantics, which establishes a reference frame within the LM latent space to enable disentangled semantic analysis. This approach transcends prior entangled analyses by leveraging the LM's own vocabulary as the basis for understanding its semantic representations.
Furthermore, the researchers propose a novel technique for computing logits, emphasizing differentiability and local isotropy. This method aims to improve the model's overall behavior and performance, complementing the vocabulary-defined semantics approach.
The paper also introduces a neural clustering module that can be used to semantically calibrate data representations during LM adaptation. This module helps the model better understand and adapt to the nuances of the data it's working with, potentially enhancing its performance on specific tasks or domains.
Through extensive experiments across diverse text understanding datasets, the researchers demonstrate that their approach outperforms state-of-the-art methods in both retrieval-augmented generation and parameter-efficient fine-tuning. This showcases the efficacy and broad applicability of the proposed techniques.
Critical Analysis
The paper presents a compelling and well-designed approach to understanding the latent space of language models. The authors' focus on disentangled, model-centric insights is a valuable contribution, as it can lead to a deeper understanding of how LMs represent and process language semantics.
However, the paper does not extensively discuss the potential limitations of the vocabulary-defined semantics approach. For example, it's unclear how well the method would scale to larger, more complex LMs, or how it might perform in domains with more specialized or technical vocabulary.
Additionally, while the neural clustering module seems promising, the paper does not provide a detailed analysis of its inner workings or the specific mechanisms by which it improves LM adaptation. Further research may be needed to fully understand the module's strengths and weaknesses.
The paper also does not address potential privacy or ethical concerns that may arise from techniques that delve deeper into the inner workings of language models. As these models become more ubiquitous and influential, it's important to consider the societal implications of advances in LM analysis and interpretation.
Overall, the paper makes a significant contribution to the field of LM interpretation and presents a compelling approach that merits further investigation and refinement.
Conclusion
The paper introduces a novel method called "vocabulary-defined semantics" that establishes a reference frame within the LM latent space to enable disentangled, model-centric analysis of language model semantics. The researchers also propose a new technique for computing logits and a neural clustering module for semantically calibrating data representations during LM adaptation.
Through extensive experiments, the paper demonstrates the efficacy and broad applicability of the proposed approaches, outperforming state-of-the-art methods in various text understanding tasks. The findings not only shed light on the inner workings of language models, but also offer practical solutions to enhance their performance and interpretability.
This research represents an important step forward in our understanding of language models and paves the way for further advancements in LM interpretation and adaptation. As language models become increasingly integral to our daily lives, such insights will be crucial for ensuring their reliability, transparency, and responsible development.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🤖
Contextual Categorization Enhancement through LLMs Latent-Space
Zineddine Bettouche, Anas Safi, Andreas Fischer
0
0
Managing the semantic quality of the categorization in large textual datasets, such as Wikipedia, presents significant challenges in terms of complexity and cost. In this paper, we propose leveraging transformer models to distill semantic information from texts in the Wikipedia dataset and its associated categories into a latent space. We then explore different approaches based on these encodings to assess and enhance the semantic identity of the categories. Our graphical approach is powered by Convex Hull, while we utilize Hierarchical Navigable Small Worlds (HNSWs) for the hierarchical approach. As a solution to the information loss caused by the dimensionality reduction, we modulate the following mathematical solution: an exponential decay function driven by the Euclidean distances between the high-dimensional encodings of the textual categories. This function represents a filter built around a contextual category and retrieves items with a certain Reconsideration Probability (RP). Retrieving high-RP items serves as a tool for database administrators to improve data groupings by providing recommendations and identifying outliers within a contextual framework.
4/26/2024
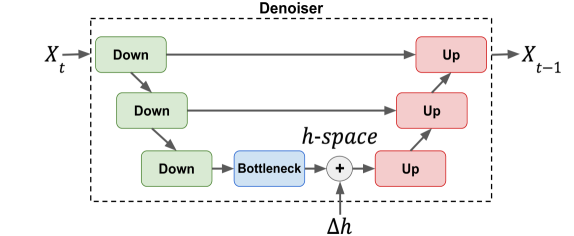
On the Semantic Latent Space of Diffusion-Based Text-to-Speech Models
Miri Varshavsky-Hassid, Roy Hirsch, Regev Cohen, Tomer Golany, Daniel Freedman, Ehud Rivlin
0
0
The incorporation of Denoising Diffusion Models (DDMs) in the Text-to-Speech (TTS) domain is rising, providing great value in synthesizing high quality speech. Although they exhibit impressive audio quality, the extent of their semantic capabilities is unknown, and controlling their synthesized speech's vocal properties remains a challenge. Inspired by recent advances in image synthesis, we explore the latent space of frozen TTS models, which is composed of the latent bottleneck activations of the DDM's denoiser. We identify that this space contains rich semantic information, and outline several novel methods for finding semantic directions within it, both supervised and unsupervised. We then demonstrate how these enable off-the-shelf audio editing, without any further training, architectural changes or data requirements. We present evidence of the semantic and acoustic qualities of the edited audio, and provide supplemental samples: https://latent-analysis-grad-tts.github.io/speech-samples/.
6/5/2024
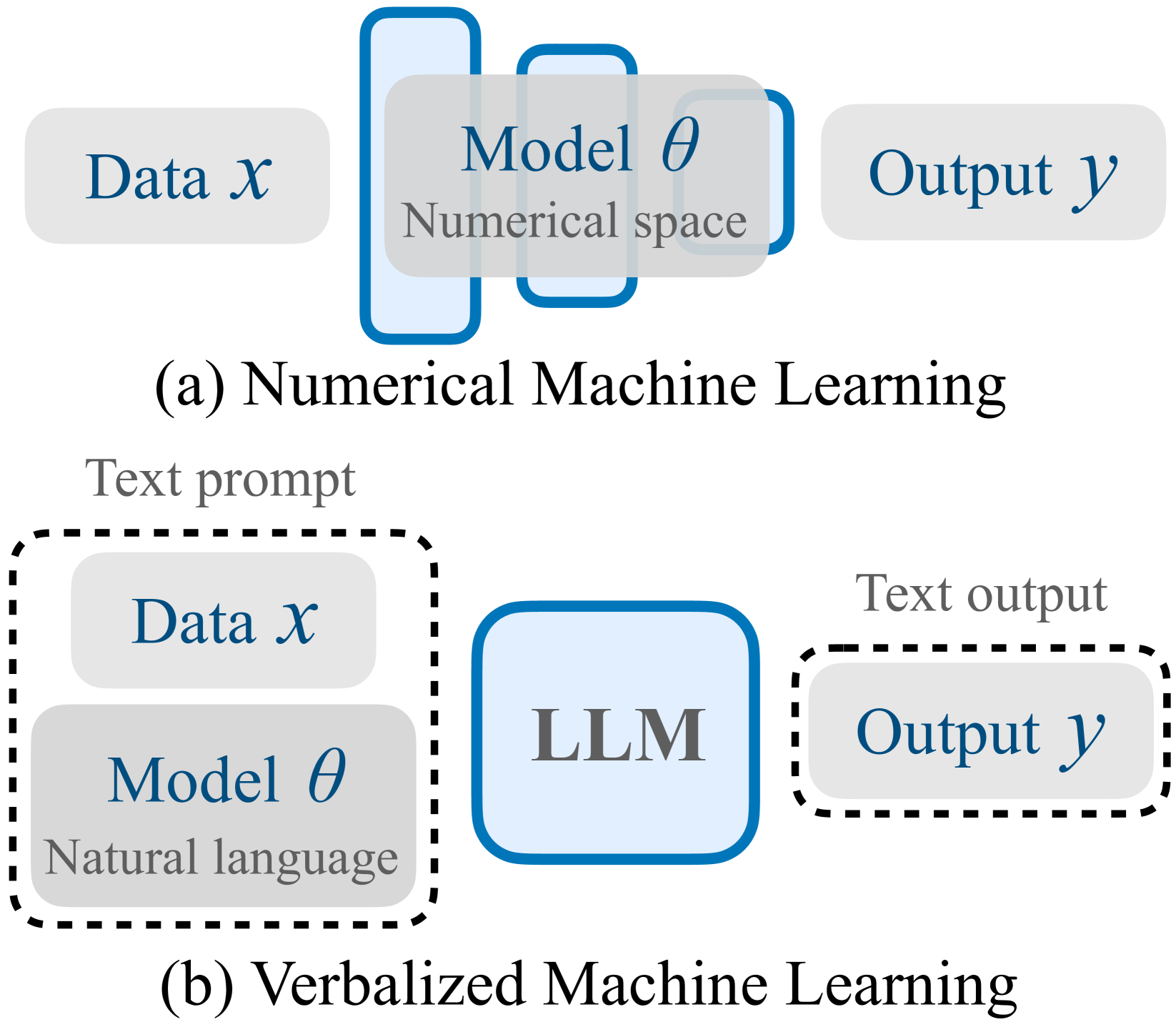
Verbalized Machine Learning: Revisiting Machine Learning with Language Models
Tim Z. Xiao, Robert Bamler, Bernhard Scholkopf, Weiyang Liu
0
0
Motivated by the large progress made by large language models (LLMs), we introduce the framework of verbalized machine learning (VML). In contrast to conventional machine learning models that are typically optimized over a continuous parameter space, VML constrains the parameter space to be human-interpretable natural language. Such a constraint leads to a new perspective of function approximation, where an LLM with a text prompt can be viewed as a function parameterized by the text prompt. Guided by this perspective, we revisit classical machine learning problems, such as regression and classification, and find that these problems can be solved by an LLM-parameterized learner and optimizer. The major advantages of VML include (1) easy encoding of inductive bias: prior knowledge about the problem and hypothesis class can be encoded in natural language and fed into the LLM-parameterized learner; (2) automatic model class selection: the optimizer can automatically select a concrete model class based on data and verbalized prior knowledge, and it can update the model class during training; and (3) interpretable learner updates: the LLM-parameterized optimizer can provide explanations for why each learner update is performed. We conduct several studies to empirically evaluate the effectiveness of VML, and hope that VML can serve as a stepping stone to stronger interpretability and trustworthiness in ML.
6/7/2024
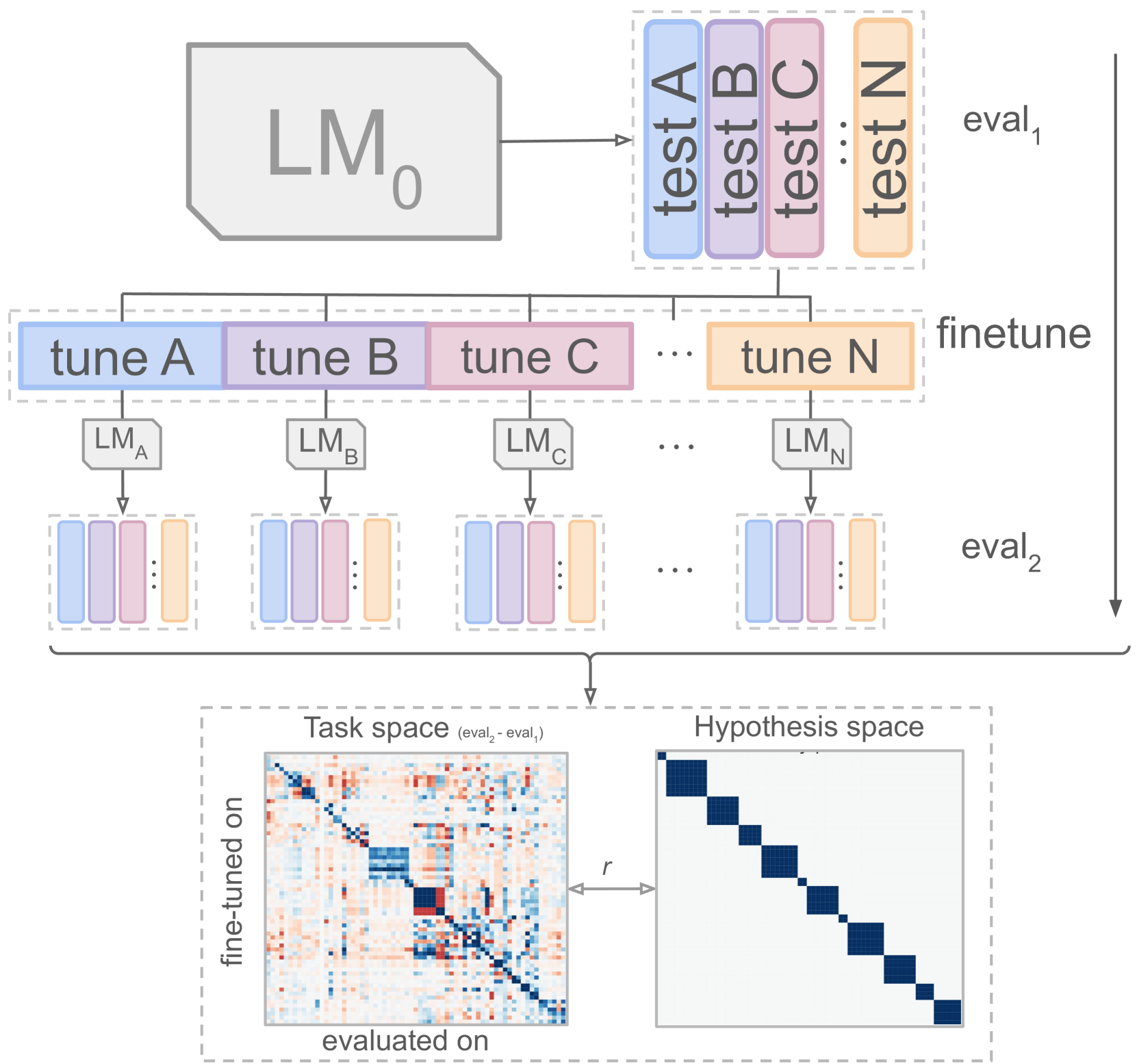
Interpretability of Language Models via Task Spaces
Lucas Weber, Jaap Jumelet, Elia Bruni, Dieuwke Hupkes
0
0
The usual way to interpret language models (LMs) is to test their performance on different benchmarks and subsequently infer their internal processes. In this paper, we present an alternative approach, concentrating on the quality of LM processing, with a focus on their language abilities. To this end, we construct 'linguistic task spaces' -- representations of an LM's language conceptualisation -- that shed light on the connections LMs draw between language phenomena. Task spaces are based on the interactions of the learning signals from different linguistic phenomena, which we assess via a method we call 'similarity probing'. To disentangle the learning signals of linguistic phenomena, we further introduce a method called 'fine-tuning via gradient differentials' (FTGD). We apply our methods to language models of three different scales and find that larger models generalise better to overarching general concepts for linguistic tasks, making better use of their shared structure. Further, the distributedness of linguistic processing increases with pre-training through increased parameter sharing between related linguistic tasks. The overall generalisation patterns are mostly stable throughout training and not marked by incisive stages, potentially explaining the lack of successful curriculum strategies for LMs.
6/11/2024