Joint Data Inpainting and Graph Learning via Unrolled Neural Networks

0

Sign in to get full access
Overview
- This paper presents a method for jointly performing data inpainting (filling in missing values) and learning the underlying graph structure of the data.
- The approach uses an unrolled neural network architecture, which allows for efficient optimization and interpretability.
- The technique can be applied to various types of graph-structured data, including spatial, temporal, and spatio-temporal data.
Plain English Explanation
In many real-world applications, such as social network analysis, sensor networks, and traffic forecasting, we often encounter datasets with missing values. This can make it challenging to draw insights from the data. Additionally, the underlying graph structure that connects the data points may not be known, which can further complicate the analysis.
The researchers in this paper propose a method that can simultaneously fill in the missing values in the data and learn the underlying graph structure. They use an unrolled neural network architecture, which means the network is designed to mimic the steps of an optimization algorithm. This allows the model to be more efficient and interpretable compared to a traditional neural network.
The key idea is to treat the data inpainting and graph learning as a joint optimization problem, where the model learns to fill in the missing values while also discovering the connections between the data points. This approach can be applied to a variety of graph-structured data, including spatial, temporal, and spatio-temporal data.
Technical Explanation
The paper presents a method called "Joint Data Inpainting and Graph Learning via Unrolled Neural Networks" (JDIGNL), which aims to solve the problem of data inpainting and graph structure learning simultaneously.
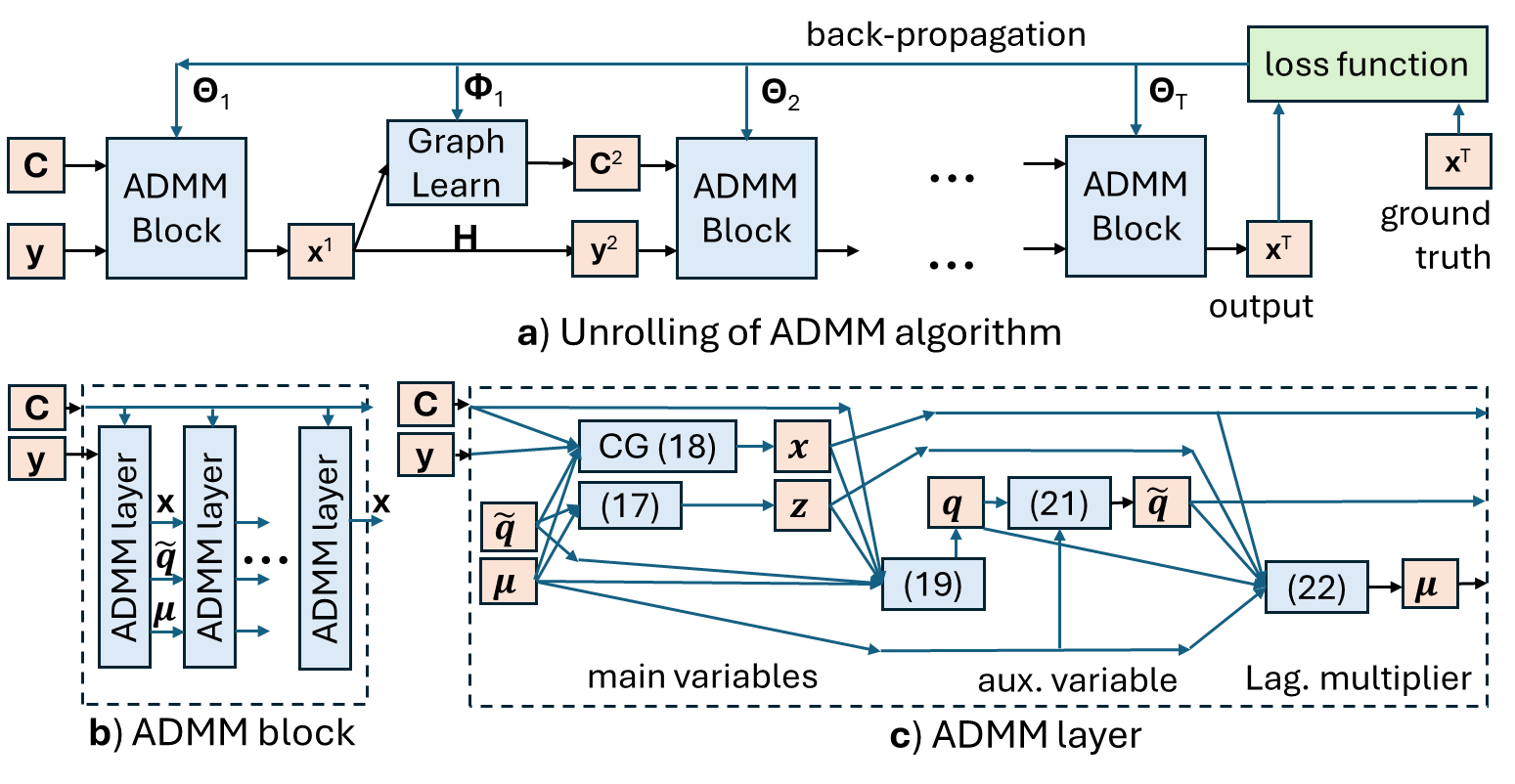
The authors formulate the problem as a joint optimization task, where the objective is to recover the missing data values and learn the underlying graph structure that best represents the relationships between the data points. To solve this problem, they propose an unrolled neural network architecture, which mimics the steps of an iterative optimization algorithm.
The key components of the JDIGNL model are:
- Graph learning module: This module learns the graph structure from the available data, using techniques such as Interpretable Lightweight Transformer via Unrolling and Unrolling Plug-and-Play Gradient Graph Laplacian Regularizer.
- Data inpainting module: This module uses the learned graph structure to fill in the missing data values, leveraging the relationships between the data points.
- Unrolled neural network architecture: The model is designed as an unrolled neural network, where each layer of the network represents a step in the optimization algorithm. This allows for efficient optimization and interpretability of the model.
The authors evaluate the performance of JDIGNL on various datasets, including spatial, temporal, and spatio-temporal data. The results show that the proposed method outperforms existing approaches in terms of both data inpainting accuracy and graph structure learning.
Critical Analysis
The paper presents a novel and promising approach for joint data inpainting and graph learning. The use of an unrolled neural network architecture is a key strength, as it allows for efficient optimization and interpretability of the model. Additionally, the ability to handle different types of graph-structured data, such as spatial, temporal, and spatio-temporal, is a versatile feature of the method.
However, the paper does not discuss the scalability of the proposed approach, particularly for large-scale datasets or graphs. The computational complexity of the unrolled neural network architecture may become a bottleneck as the size of the problem increases. Additionally, the paper does not explore the robustness of the method to noise or outliers in the data, which could be an important consideration in real-world applications.
Further research could investigate ways to improve the scalability and robustness of the JDIGNL model, such as exploring alternative optimization techniques or incorporating additional regularization strategies. Additionally, it would be valuable to see more extensive validation of the method on a wider range of real-world datasets and applications.
Conclusion
The "Joint Data Inpainting and Graph Learning via Unrolled Neural Networks" paper presents a promising approach for simultaneously recovering missing data values and learning the underlying graph structure of the data. The use of an unrolled neural network architecture allows for efficient optimization and interpretability of the model, which is a key strength of the proposed method.
The ability to handle diverse types of graph-structured data, including spatial, temporal, and spatio-temporal, makes the JDIGNL model a versatile tool for a wide range of applications, such as social network analysis, sensor network monitoring, and traffic forecasting. While the paper highlights the potential of the method, further research is needed to address scalability and robustness concerns, ultimately paving the way for more widespread adoption of this approach in real-world applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Joint Data Inpainting and Graph Learning via Unrolled Neural Networks
Subbareddy Batreddy, Pushkal Mishra, Yaswanth Kakarla, Aditya Siripuram
Given partial measurements of a time-varying graph signal, we propose an algorithm to simultaneously estimate both the underlying graph topology and the missing measurements. The proposed algorithm operates by training an interpretable neural network, designed from the unrolling framework. The proposed technique can be used both as a graph learning and a graph signal reconstruction algorithm. This work enhances prior work in graph signal reconstruction by allowing the underlying graph to be unknown; and also builds on prior work in graph learning by tailoring the learned graph to the signal reconstruction task.
Read more7/17/2024
0
Interpretable Lightweight Transformer via Unrolling of Learned Graph Smoothness Priors
Tam Thuc Do, Parham Eftekhar, Seyed Alireza Hosseini, Gene Cheung, Philip Chou
We build interpretable and lightweight transformer-like neural networks by unrolling iterative optimization algorithms that minimize graph smoothness priors -- the quadratic graph Laplacian regularizer (GLR) and the $ell_1$-norm graph total variation (GTV) -- subject to an interpolation constraint. The crucial insight is that a normalized signal-dependent graph learning module amounts to a variant of the basic self-attention mechanism in conventional transformers. Unlike black-box transformers that require learning of large key, query and value matrices to compute scaled dot products as affinities and subsequent output embeddings, resulting in huge parameter sets, our unrolled networks employ shallow CNNs to learn low-dimensional features per node to establish pairwise Mahalanobis distances and construct sparse similarity graphs. At each layer, given a learned graph, the target interpolated signal is simply a low-pass filtered output derived from the minimization of an assumed graph smoothness prior, leading to a dramatic reduction in parameter count. Experiments for two image interpolation applications verify the restoration performance, parameter efficiency and robustness to covariate shift of our graph-based unrolled networks compared to conventional transformers.
Read more6/7/2024
🌐
0
New!Online Network Inference from Graph-Stationary Signals with Hidden Nodes
Andrei Buciulea, Madeline Navarro, Samuel Rey, Santiago Segarra, Antonio G. Marques
Graph learning is the fundamental task of estimating unknown graph connectivity from available data. Typical approaches assume that not only is all information available simultaneously but also that all nodes can be observed. However, in many real-world scenarios, data can neither be known completely nor obtained all at once. We present a novel method for online graph estimation that accounts for the presence of hidden nodes. We consider signals that are stationary on the underlying graph, which provides a model for the unknown connections to hidden nodes. We then formulate a convex optimization problem for graph learning from streaming, incomplete graph signals. We solve the proposed problem through an efficient proximal gradient algorithm that can run in real-time as data arrives sequentially. Additionally, we provide theoretical conditions under which our online algorithm is similar to batch-wise solutions. Through experimental results on synthetic and real-world data, we demonstrate the viability of our approach for online graph learning in the presence of missing observations.
Read more9/16/2024
🐍
0
New!Online Learning Of Expanding Graphs
Samuel Rey, Bishwadeep Das, Elvin Isufi
This paper addresses the problem of online network topology inference for expanding graphs from a stream of spatiotemporal signals. Online algorithms for dynamic graph learning are crucial in delay-sensitive applications or when changes in topology occur rapidly. While existing works focus on inferring the connectivity within a fixed set of nodes, in practice, the graph can grow as new nodes join the network. This poses additional challenges like modeling temporal dynamics involving signals and graphs of different sizes. This growth also increases the computational complexity of the learning process, which may become prohibitive. To the best of our knowledge, this is the first work to tackle this setting. We propose a general online algorithm based on projected proximal gradient descent that accounts for the increasing graph size at each iteration. Recursively updating the sample covariance matrix is a key aspect of our approach. We introduce a strategy that enables different types of updates for nodes that just joined the network and for previously existing nodes. To provide further insights into the proposed method, we specialize it in Gaussian Markov random field settings, where we analyze the computational complexity and characterize the dynamic cumulative regret. Finally, we demonstrate the effectiveness of the proposed approach using both controlled experiments and real-world datasets from epidemic and financial networks.
Read more9/16/2024