Interventional Imbalanced Multi-Modal Representation Learning via $beta$-Generalization Front-Door Criterion

0

Sign in to get full access
Overview
- The paper proposes a new method for learning representations from imbalanced multi-modal data using a β-Generalization Front-Door Criterion.
- The method aims to address challenges in multi-modal learning, such as modal imbalance and representation biases.
- Experiments on real-world datasets demonstrate the effectiveness of the proposed approach compared to other multi-modal representation learning techniques.
Plain English Explanation
The paper introduces a new way to learn useful representations from data that comes from multiple different sources, or "modalities," when some of those modalities are much more common than others. This is a common problem in real-world datasets, where some data may be easy to collect (like text) while other data (like images or audio) is harder to obtain.
The key idea is to use a special mathematical criterion, called the "β-Generalization Front-Door Criterion," to guide the learning process and produce representations that are more balanced and fair across the different modalities. This helps overcome the tendency for the model to focus too much on the more common modalities and ignore the rarer ones.
The paper demonstrates through experiments on real-world datasets that this new method outperforms other approaches to multi-modal representation learning, especially when the dataset is highly imbalanced between the different modalities.
Technical Explanation
The paper proposes an Interventional Imbalanced Multi-Modal Representation Learning (IIMRL) framework that uses the β-Generalization Front-Door Criterion to learn balanced representations from imbalanced multi-modal data.
The key components are:
- A Multi-Modal Encoder that takes in data from multiple modalities and produces a shared latent representation.
- A Multi-Modal Discriminator that tries to predict the modality of the input, encouraging the encoder to learn balanced representations.
- The β-Generalization Front-Door Criterion that provides a principled way to trade off between representation quality and modality balance.
The authors conduct experiments on several real-world multi-modal datasets, demonstrating that IIMRL outperforms other state-of-the-art multi-modal representation learning methods, especially when the dataset is highly imbalanced across modalities.
Critical Analysis
The paper thoroughly addresses the important challenge of learning balanced representations from imbalanced multi-modal data. However, some potential limitations and areas for further research include:
- The experiments are conducted on a limited set of datasets, so the generalization of the method to a wider range of multi-modal problems is not fully established.
- The paper does not explore the sensitivity of the method to the choice of the β parameter in the β-Generalization Front-Door Criterion, which controls the trade-off between representation quality and modality balance.
- While the paper discusses the importance of learning balanced representations, it does not directly address potential fairness or ethical concerns that may arise from biases in the input data or the learned representations.
Conclusion
The proposed Interventional Imbalanced Multi-Modal Representation Learning method with the β-Generalization Front-Door Criterion offers a promising approach to addressing the challenge of learning balanced representations from imbalanced multi-modal data. The experimental results demonstrate the effectiveness of this technique, which could have significant impact on a wide range of applications involving multi-modal data, from multimedia analysis to healthcare and beyond.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Interventional Imbalanced Multi-Modal Representation Learning via $beta$-Generalization Front-Door Criterion
Yi Li, Jiangmeng Li, Fei Song, Qingmeng Zhu, Changwen Zheng, Wenwen Qiang
Multi-modal methods establish comprehensive superiority over uni-modal methods. However, the imbalanced contributions of different modalities to task-dependent predictions constantly degrade the discriminative performance of canonical multi-modal methods. Based on the contribution to task-dependent predictions, modalities can be identified as predominant and auxiliary modalities. Benchmark methods raise a tractable solution: augmenting the auxiliary modality with a minor contribution during training. However, our empirical explorations challenge the fundamental idea behind such behavior, and we further conclude that benchmark approaches suffer from certain defects: insufficient theoretical interpretability and limited exploration capability of discriminative knowledge. To this end, we revisit multi-modal representation learning from a causal perspective and build the Structural Causal Model. Following the empirical explorations, we determine to capture the true causality between the discriminative knowledge of predominant modality and predictive label while considering the auxiliary modality. Thus, we introduce the $beta$-generalization front-door criterion. Furthermore, we propose a novel network for sufficiently exploring multi-modal discriminative knowledge. Rigorous theoretical analyses and various empirical evaluations are provided to support the effectiveness of the innate mechanism behind our proposed method.
Read more6/18/2024
0
On the Limits of Multi-modal Meta-Learning with Auxiliary Task Modulation Using Conditional Batch Normalization
Jordi Armengol-Estap'e, Vincent Michalski, Ramnath Kumar, Pierre-Luc St-Charles, Doina Precup, Samira Ebrahimi Kahou
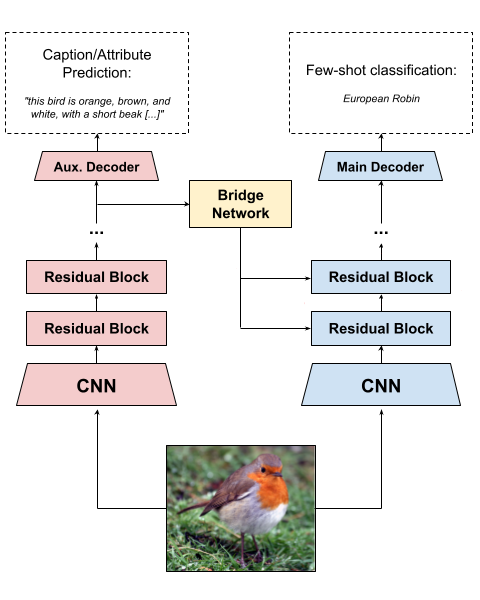
Few-shot learning aims to learn representations that can tackle novel tasks given a small number of examples. Recent studies show that cross-modal learning can improve representations for few-shot classification. More specifically, language is a rich modality that can be used to guide visual learning. In this work, we experiment with a multi-modal architecture for few-shot learning that consists of three components: a classifier, an auxiliary network, and a bridge network. While the classifier performs the main classification task, the auxiliary network learns to predict language representations from the same input, and the bridge network transforms high-level features of the auxiliary network into modulation parameters for layers of the few-shot classifier using conditional batch normalization. The bridge should encourage a form of lightweight semantic alignment between language and vision which could be useful for the classifier. However, after evaluating the proposed approach on two popular few-shot classification benchmarks we find that a) the improvements do not reproduce across benchmarks, and b) when they do, the improvements are due to the additional compute and parameters introduced by the bridge network. We contribute insights and recommendations for future work in multi-modal meta-learning, especially when using language representations.
Read more5/31/2024

0
Modality-Balanced Learning for Multimedia Recommendation
Jinghao Zhang, Guofan Liu, Qiang Liu, Shu Wu, Liang Wang
Many recommender models have been proposed to investigate how to incorporate multimodal content information into traditional collaborative filtering framework effectively. The use of multimodal information is expected to provide more comprehensive information and lead to superior performance. However, the integration of multiple modalities often encounters the modal imbalance problem: since the information in different modalities is unbalanced, optimizing the same objective across all modalities leads to the under-optimization problem of the weak modalities with a slower convergence rate or lower performance. Even worse, we find that in multimodal recommendation models, all modalities suffer from the problem of insufficient optimization. To address these issues, we propose a Counterfactual Knowledge Distillation method that could solve the imbalance problem and make the best use of all modalities. Through modality-specific knowledge distillation, it could guide the multimodal model to learn modality-specific knowledge from uni-modal teachers. We also design a novel generic-and-specific distillation loss to guide the multimodal student to learn wider-and-deeper knowledge from teachers. Additionally, to adaptively recalibrate the focus of the multimodal model towards weaker modalities during training, we estimate the causal effect of each modality on the training objective using counterfactual inference techniques, through which we could determine the weak modalities, quantify the imbalance degree and re-weight the distillation loss accordingly. Our method could serve as a plug-and-play module for both late-fusion and early-fusion backbones. Extensive experiments on six backbones show that our proposed method can improve the performance by a large margin. The source code will be released at url{https://github.com/CRIPAC-DIG/Balanced-Multimodal-Rec}
Read more8/14/2024
0
Quantifying and Enhancing Multi-modal Robustness with Modality Preference
Zequn Yang, Yake Wei, Ce Liang, Di Hu
Multi-modal models have shown a promising capability to effectively integrate information from various sources, yet meanwhile, they are found vulnerable to pervasive perturbations, such as uni-modal attacks and missing conditions. To counter these perturbations, robust multi-modal representations are highly expected, which are positioned well away from the discriminative multi-modal decision boundary. In this paper, different from conventional empirical studies, we focus on a commonly used joint multi-modal framework and theoretically discover that larger uni-modal representation margins and more reliable integration for modalities are essential components for achieving higher robustness. This discovery can further explain the limitation of multi-modal robustness and the phenomenon that multi-modal models are often vulnerable to attacks on the specific modality. Moreover, our analysis reveals how the widespread issue, that the model has different preferences for modalities, limits the multi-modal robustness by influencing the essential components and could lead to attacks on the specific modality highly effective. Inspired by our theoretical finding, we introduce a training procedure called Certifiable Robust Multi-modal Training (CRMT), which can alleviate this influence from modality preference and explicitly regulate essential components to significantly improve robustness in a certifiable manner. Our method demonstrates substantial improvements in performance and robustness compared with existing methods. Furthermore, our training procedure can be easily extended to enhance other robust training strategies, highlighting its credibility and flexibility.
Read more4/19/2024