(A Partial Survey of) Decentralized, Cooperative Multi-Agent Reinforcement Learning

0
🏅
Sign in to get full access
Overview
- Multi-agent reinforcement learning (MARL) has become increasingly popular in recent years
- MARL approaches can be divided into three main types: centralized training and execution (CTE), centralized training for decentralized execution (CTDE), and decentralized training and execution (DTE)
- This paper focuses on decentralized training and execution (DTE) methods for cooperative MARL
Plain English Explanation
Reinforcement learning is a type of machine learning where an agent learns by interacting with an environment and receiving rewards or penalties. In multi-agent reinforcement learning (MARL), there are multiple agents that learn and act together.
DTE methods for cooperative MARL make the fewest assumptions - each agent learns and acts independently, without any centralized coordination. This can be simpler to implement, but has pros and cons compared to more centralized approaches.
The paper first explains the cooperative MARL problem in the form of the Dec-POMDP framework. It then discusses different DTE methods, starting with simple independent Q-learning and moving on to more advanced policy gradient techniques like independent REINFORCE and PPO.
The key idea is that any single-agent reinforcement learning algorithm can be adapted to the multi-agent case by having each agent learn and act independently. This decentralized approach is necessary when there is no way for the agents to coordinate offline before learning and acting in the environment.
Technical Explanation
The paper begins by formulating the cooperative MARL problem as a Decentralized Partially Observable Markov Decision Process (Dec-POMDP). In this framework, each agent has its own local observation and must learn a policy to act based on this partial information, with the goal of maximizing the shared global reward.
Value-based DTE methods start with the simplest approach of independent Q-learning, where each agent learns a Q-function independently. The paper then discusses extensions to the deep case using DQN, and methods to address the challenges this introduces, such as PTDE.
For policy gradient DTE methods, the paper covers starting with independent REINFORCE, then moving to actor-critic approaches like independent PPO. These methods directly learn a policy rather than a value function.
Throughout, the paper highlights the pros and cons of the DTE approach compared to more centralized methods. The key advantage is the minimal assumptions required, but this can lead to challenges like coordinating exploration or credit assignment.
Critical Analysis
The paper provides a comprehensive overview of DTE methods for cooperative MARL, but acknowledges several limitations and areas for future work. For example, the independent learning approach can struggle with credit assignment and coordinating exploration, which centralized methods may handle better.
Additionally, the paper focuses solely on the cooperative case, while many real-world multi-agent scenarios involve competition or mixed cooperation-competition. Extending the DTE analysis to these more general settings would be an important next step.
Further research is also needed to better understand the theoretical properties and convergence guarantees of DTE methods, as well as develop principled techniques to address the challenges they face compared to centralized approaches.
Overall, the paper serves as a valuable introduction to DTE for MARL, but the field continues to evolve, and more work is needed to fully realize the potential of this decentralized paradigm.
Conclusion
This paper provides a thorough introduction to decentralized training and execution (DTE) methods for cooperative multi-agent reinforcement learning (MARL). DTE approaches make minimal assumptions, allowing each agent to learn and act independently, which can simplify implementation but also introduces challenges.
The paper covers the key DTE techniques, from simple independent Q-learning to more advanced policy gradient methods like independent REINFORCE and PPO. It highlights both the advantages and drawbacks of the DTE approach compared to more centralized MARL methods.
While DTE is a promising direction for MARL, particularly in settings where offline coordination is not possible, further research is needed to address the challenges it faces, such as credit assignment and exploration. Extending the analysis to competitive and mixed cooperative-competitive scenarios would also be an important next step.
Overall, this paper serves as a solid foundation for understanding the state-of-the-art in decentralized multi-agent reinforcement learning and the tradeoffs involved in this rapidly evolving field.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🏅
0
(A Partial Survey of) Decentralized, Cooperative Multi-Agent Reinforcement Learning
Christopher Amato
Multi-agent reinforcement learning (MARL) has exploded in popularity in recent years. Many approaches have been developed but they can be divided into three main types: centralized training and execution (CTE), centralized training for decentralized execution (CTDE), and Decentralized training and execution (DTE). Decentralized training and execution methods make the fewest assumptions and are often simple to implement. In fact, as I'll discuss, any single-agent RL method can be used for DTE by just letting each agent learn separately. Of course, there are pros and cons to such approaches. It is worth noting that DTE is required if no offline coordination is available. That is, if all agents must learn during online interactions without prior coordination, learning and execution must both be decentralized. DTE methods can be applied in cooperative, competitive, or mixed cases but this text will focus on the cooperative MARL case. This text is an introduction to the field of decentralized, cooperative MARL. As such, I will first give a brief description of the cooperative MARL problem in the form of the Dec-POMDP. Then, I will discuss value-based DTE methods starting with independent Q-learning and its extensions and then discuss the extension to the deep case with DQN, the additional complications this causes, and methods that have been developed to (attempt to) address these issues. Next, I will discuss policy gradient DTE methods starting with independent REINFORCE (i.e., vanilla policy gradient), and then extending to the actor-critic case and deep variants (such as independent PPO). Finally, I will discuss some general topics related to DTE and future directions.
Read more8/21/2024
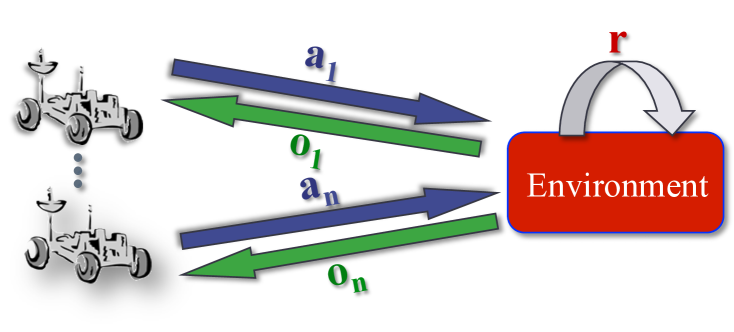
0
An Introduction to Centralized Training for Decentralized Execution in Cooperative Multi-Agent Reinforcement Learning
Christopher Amato
Multi-agent reinforcement learning (MARL) has exploded in popularity in recent years. Many approaches have been developed but they can be divided into three main types: centralized training and execution (CTE), centralized training for decentralized execution (CTDE), and Decentralized training and execution (DTE). CTDE methods are the most common as they can use centralized information during training but execute in a decentralized manner -- using only information available to that agent during execution. CTDE is the only paradigm that requires a separate training phase where any available information (e.g., other agent policies, underlying states) can be used. As a result, they can be more scalable than CTE methods, do not require communication during execution, and can often perform well. CTDE fits most naturally with the cooperative case, but can be potentially applied in competitive or mixed settings depending on what information is assumed to be observed. This text is an introduction to CTDE in cooperative MARL. It is meant to explain the setting, basic concepts, and common methods. It does not cover all work in CTDE MARL as the subarea is quite extensive. I have included work that I believe is important for understanding the main concepts in the subarea and apologize to those that I have omitted.
Read more9/6/2024

0
Hierarchical Consensus-Based Multi-Agent Reinforcement Learning for Multi-Robot Cooperation Tasks
Pu Feng, Junkang Liang, Size Wang, Xin Yu, Xin Ji, Yiting Chen, Kui Zhang, Rongye Shi, Wenjun Wu
In multi-agent reinforcement learning (MARL), the Centralized Training with Decentralized Execution (CTDE) framework is pivotal but struggles due to a gap: global state guidance in training versus reliance on local observations in execution, lacking global signals. Inspired by human societal consensus mechanisms, we introduce the Hierarchical Consensus-based Multi-Agent Reinforcement Learning (HC-MARL) framework to address this limitation. HC-MARL employs contrastive learning to foster a global consensus among agents, enabling cooperative behavior without direct communication. This approach enables agents to form a global consensus from local observations, using it as an additional piece of information to guide collaborative actions during execution. To cater to the dynamic requirements of various tasks, consensus is divided into multiple layers, encompassing both short-term and long-term considerations. Short-term observations prompt the creation of an immediate, low-layer consensus, while long-term observations contribute to the formation of a strategic, high-layer consensus. This process is further refined through an adaptive attention mechanism that dynamically adjusts the influence of each consensus layer. This mechanism optimizes the balance between immediate reactions and strategic planning, tailoring it to the specific demands of the task at hand. Extensive experiments and real-world applications in multi-robot systems showcase our framework's superior performance, marking significant advancements over baselines.
Read more8/26/2024

0
Centralized vs. Decentralized Multi-Agent Reinforcement Learning for Enhanced Control of Electric Vehicle Charging Networks
Amin Shojaeighadikolaei, Zsolt Talata, Morteza Hashemi
The widespread adoption of electric vehicles (EVs) poses several challenges to power distribution networks and smart grid infrastructure due to the possibility of significantly increasing electricity demands, especially during peak hours. Furthermore, when EVs participate in demand-side management programs, charging expenses can be reduced by using optimal charging control policies that fully utilize real-time pricing schemes. However, devising optimal charging methods and control strategies for EVs is challenging due to various stochastic and uncertain environmental factors. Currently, most EV charging controllers operate based on a centralized model. In this paper, we introduce a novel approach for distributed and cooperative charging strategy using a Multi-Agent Reinforcement Learning (MARL) framework. Our method is built upon the Deep Deterministic Policy Gradient (DDPG) algorithm for a group of EVs in a residential community, where all EVs are connected to a shared transformer. This method, referred to as CTDE-DDPG, adopts a Centralized Training Decentralized Execution (CTDE) approach to establish cooperation between agents during the training phase, while ensuring a distributed and privacy-preserving operation during execution. We theoretically examine the performance of centralized and decentralized critics for the DDPG-based MARL implementation and demonstrate their trade-offs. Furthermore, we numerically explore the efficiency, scalability, and performance of centralized and decentralized critics. Our theoretical and numerical results indicate that, despite higher policy gradient variances and training complexity, the CTDE-DDPG framework significantly improves charging efficiency by reducing total variation by approximately %36 and charging cost by around %9.1 on average...
Read more4/22/2024