LocInv: Localization-aware Inversion for Text-Guided Image Editing
2405.01496
0
1

Abstract
Large-scale Text-to-Image (T2I) diffusion models demonstrate significant generation capabilities based on textual prompts. Based on the T2I diffusion models, text-guided image editing research aims to empower users to manipulate generated images by altering the text prompts. However, existing image editing techniques are prone to editing over unintentional regions that are beyond the intended target area, primarily due to inaccuracies in cross-attention maps. To address this problem, we propose Localization-aware Inversion (LocInv), which exploits segmentation maps or bounding boxes as extra localization priors to refine the cross-attention maps in the denoising phases of the diffusion process. Through the dynamic updating of tokens corresponding to noun words in the textual input, we are compelling the cross-attention maps to closely align with the correct noun and adjective words in the text prompt. Based on this technique, we achieve fine-grained image editing over particular objects while preventing undesired changes to other regions. Our method LocInv, based on the publicly available Stable Diffusion, is extensively evaluated on a subset of the COCO dataset, and consistently obtains superior results both quantitatively and qualitatively.The code will be released at https://github.com/wangkai930418/DPL
Create account to get full access
Overview
- This paper introduces "LocInv", a method for localization-aware inversion of text-guided image editing models.
- LocInv allows users to edit specific regions of an image by providing text prompts, without having to segment the image or provide additional inputs.
- The method leverages the text-image alignment learned by diffusion models to identify the relevant regions in the image to be edited.
- LocInv can be used with various text-to-image and image-to-image models, making it a versatile tool for text-guided image editing.
Plain English Explanation
The paper presents a new technique called "LocInv" that makes it easier to edit specific parts of an image using text prompts. Typically, when you want to edit an image based on a text description, you need to first identify the relevant regions in the image that the text is referring to. This can be a complex and time-consuming process.
With LocInv, the system automatically figures out which parts of the image the text prompt is referring to, without requiring you to explicitly segment the image or provide any additional inputs. It does this by leveraging the text-image alignment learned by diffusion models - a type of AI model that can generate images from text descriptions.
The key idea behind LocInv is that it can identify the relevant regions in the image that correspond to the text prompt, and then focus the editing process on those specific areas. This makes the text-guided image editing process much more intuitive and user-friendly.
The LocInv method can be used with a variety of different text-to-image and image-to-image models, making it a versatile tool for all kinds of text-guided image editing tasks. This could be useful for applications like photo editing, product design, or even creative visual storytelling.
Technical Explanation
The paper introduces a novel technique called "LocInv" (link to IterInv) for localization-aware inversion of text-guided image editing models. LocInv allows users to edit specific regions of an image by providing text prompts, without having to segment the image or provide additional inputs.
The key innovation of LocInv is that it leverages the text-image alignment learned by diffusion models (link to Exposing T-I Inconsistency) to identify the relevant regions in the image that correspond to the text prompt. This is achieved through a novel localization module that computes feature maps that highlight the image regions most relevant to the text.
The LocInv framework can be applied to various text-to-image and image-to-image models (link to Text-Driven Image Editing, link to DM-Align, link to ZONE), making it a versatile tool for text-guided image editing. The authors demonstrate the effectiveness of LocInv through extensive experiments on various benchmarks, showing that it outperforms previous approaches in terms of editing quality and efficiency.
Critical Analysis
The paper presents a compelling approach to text-guided image editing by introducing the LocInv method. One of the key strengths of LocInv is its ability to automatically identify the relevant regions in an image that correspond to a given text prompt, without requiring any additional user inputs or segmentation.
However, the paper also acknowledges some limitations of the current LocInv implementation. For example, the method may struggle with complex scenes or images with multiple objects, as the text-image alignment learned by the diffusion model may not be precise enough to accurately localize the relevant regions. Additionally, the authors note that LocInv may be sensitive to the quality and consistency of the text prompts provided by users.
Further research could explore ways to improve the robustness and generalization of the LocInv method, such as by incorporating additional cues or constraints to refine the localization process. It would also be interesting to investigate how LocInv could be extended to support more advanced text-guided editing scenarios, such as editing multiple regions simultaneously or enabling interactive refinement of the editing results.
Overall, the LocInv approach represents an important step forward in making text-guided image editing more accessible and intuitive for users. As the field of text-to-image and image-to-image modeling continues to evolve, techniques like LocInv will likely play a crucial role in bridging the gap between language and visual content creation.
Conclusion
The LocInv method introduced in this paper offers a novel approach to text-guided image editing, allowing users to edit specific regions of an image by providing text prompts without the need for additional segmentation or inputs. By leveraging the text-image alignment learned by diffusion models, LocInv can automatically identify the relevant regions in the image to be edited, making the editing process more intuitive and user-friendly.
The versatility of LocInv, which can be applied to various text-to-image and image-to-image models, suggests that it has the potential to become a valuable tool for a wide range of visual content creation and editing tasks. As the field of text-guided image editing continues to evolve, techniques like LocInv will likely play an increasingly important role in bridging the gap between language and visual media, empowering users to express their ideas and creativity through more natural and intuitive interfaces.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🏋️
IterInv: Iterative Inversion for Pixel-Level T2I Models
Chuanming Tang, Kai Wang, Joost van de Weijer
0
0
Large-scale text-to-image diffusion models have been a ground-breaking development in generating convincing images following an input text prompt. The goal of image editing research is to give users control over the generated images by modifying the text prompt. Current image editing techniques predominantly hinge on DDIM inversion as a prevalent practice rooted in Latent Diffusion Models (LDM). However, the large pretrained T2I models working on the latent space suffer from losing details due to the first compression stage with an autoencoder mechanism. Instead, other mainstream T2I pipeline working on the pixel level, such as Imagen and DeepFloyd-IF, circumvents the above problem. They are commonly composed of multiple stages, typically starting with a text-to-image stage and followed by several super-resolution stages. In this pipeline, the DDIM inversion fails to find the initial noise and generate the original image given that the super-resolution diffusion models are not compatible with the DDIM technique. According to our experimental findings, iteratively concatenating the noisy image as the condition is the root of this problem. Based on this observation, we develop an iterative inversion (IterInv) technique for this category of T2I models and verify IterInv with the open-source DeepFloyd-IF model.Specifically, IterInv employ NTI as the inversion and reconstruction of low-resolution image generation. In stages 2 and 3, we update the latent variance at each timestep to find the deterministic inversion trace and promote the reconstruction process. By combining our method with a popular image editing method, we prove the application prospects of IterInv. The code will be released upon acceptance. The code is available at url{https://github.com/Tchuanm/IterInv.git}.
4/23/2024
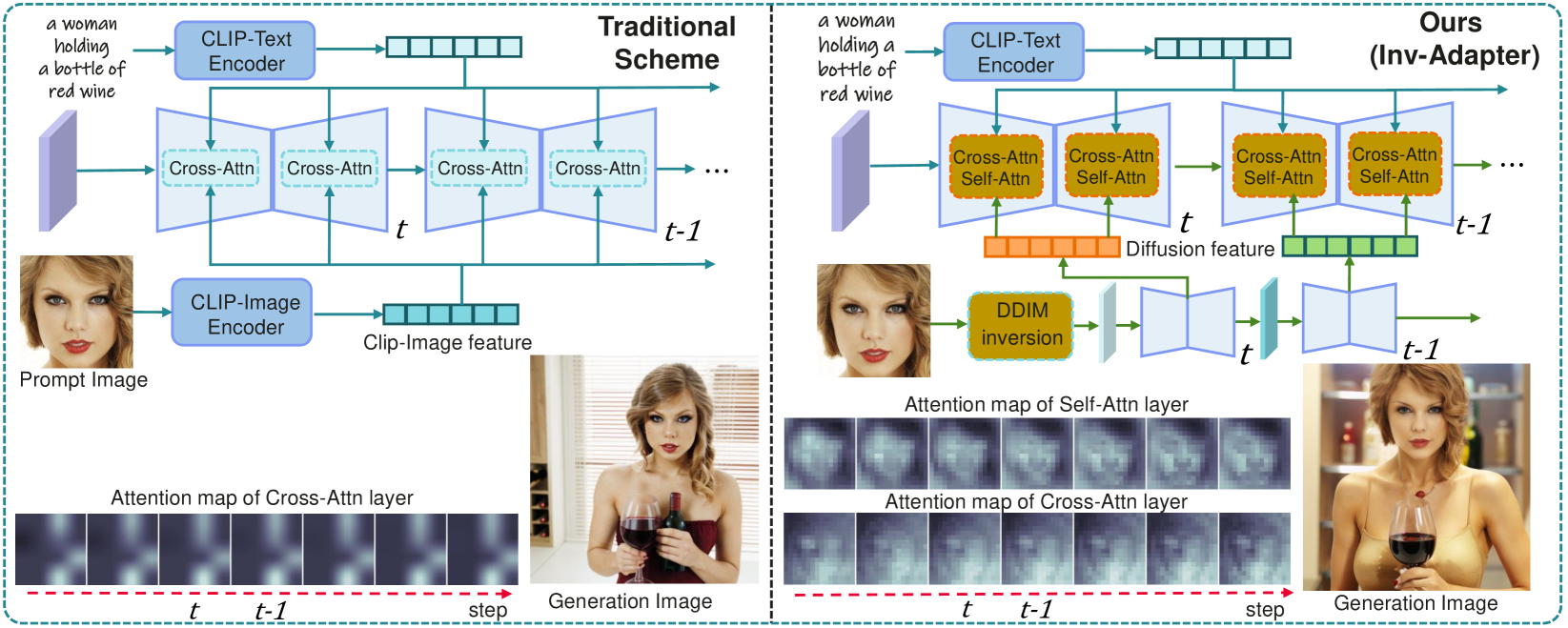
Inv-Adapter: ID Customization Generation via Image Inversion and Lightweight Adapter
Peng Xing, Ning Wang, Jianbo Ouyang, Zechao Li
0
0
The remarkable advancement in text-to-image generation models significantly boosts the research in ID customization generation. However, existing personalization methods cannot simultaneously satisfy high fidelity and high-efficiency requirements. Their main bottleneck lies in the prompt image encoder, which produces weak alignment signals with the text-to-image model and significantly increased model size. Towards this end, we propose a lightweight Inv-Adapter, which first extracts diffusion-domain representations of ID images utilizing a pre-trained text-to-image model via DDIM image inversion, without additional image encoder. Benefiting from the high alignment of the extracted ID prompt features and the intermediate features of the text-to-image model, we then embed them efficiently into the base text-to-image model by carefully designing a lightweight attention adapter. We conduct extensive experiments to assess ID fidelity, generation loyalty, speed, and training parameters, all of which show that the proposed Inv-Adapter is highly competitive in ID customization generation and model scale.
6/7/2024

Enhancing Text-to-Image Editing via Hybrid Mask-Informed Fusion
Aoxue Li, Mingyang Yi, Zhenguo Li
0
0
Recently, text-to-image (T2I) editing has been greatly pushed forward by applying diffusion models. Despite the visual promise of the generated images, inconsistencies with the expected textual prompt remain prevalent. This paper aims to systematically improve the text-guided image editing techniques based on diffusion models, by addressing their limitations. Notably, the common idea in diffusion-based editing firstly reconstructs the source image via inversion techniques e.g., DDIM Inversion. Then following a fusion process that carefully integrates the source intermediate (hidden) states (obtained by inversion) with the ones of the target image. Unfortunately, such a standard pipeline fails in many cases due to the interference of texture retention and the new characters creation in some regions. To mitigate this, we incorporate human annotation as an external knowledge to confine editing within a ``Mask-informed'' region. Then we carefully Fuse the edited image with the source image and a constructed intermediate image within the model's Self-Attention module. Extensive empirical results demonstrate the proposed ``MaSaFusion'' significantly improves the existing T2I editing techniques.
5/27/2024

Text Guided Image Editing with Automatic Concept Locating and Forgetting
Jia Li, Lijie Hu, Zhixian He, Jingfeng Zhang, Tianhang Zheng, Di Wang
0
0
With the advancement of image-to-image diffusion models guided by text, significant progress has been made in image editing. However, a persistent challenge remains in seamlessly incorporating objects into images based on textual instructions, without relying on extra user-provided guidance. Text and images are inherently distinct modalities, bringing out difficulties in fully capturing the semantic intent conveyed through language and accurately translating that into the desired visual modifications. Therefore, text-guided image editing models often produce generations with residual object attributes that do not fully align with human expectations. To address this challenge, the models should comprehend the image content effectively away from a disconnect between the provided textual editing prompts and the actual modifications made to the image. In our paper, we propose a novel method called Locate and Forget (LaF), which effectively locates potential target concepts in the image for modification by comparing the syntactic trees of the target prompt and scene descriptions in the input image, intending to forget their existence clues in the generated image. Compared to the baselines, our method demonstrates its superiority in text-guided image editing tasks both qualitatively and quantitatively.
5/31/2024