Invariance of deep image quality metrics to affine transformations

0

Sign in to get full access
Overview
- Examines the invariance of deep image quality metrics to affine transformations
- Proposes a methodology to measure perceptual thresholds and sensitivities to affine transformations
- Evaluates the performance of several popular image quality metrics on this task
Plain English Explanation
Researchers in this paper investigate how well different algorithms that measure image quality hold up when the images are transformed in certain ways. These transformations, called "affine transformations," include things like rotating, scaling, or shearing the image.
The key idea is to understand how sensitive these image quality metrics are to these types of changes. For example, a good metric should give similar scores for an image and its transformed version, as long as the changes are not too extreme and the overall visual quality is still comparable.
The researchers develop a methodology to measure the "thresholds" at which these affine transformations start to significantly impact the quality scores. They also look at the "sensitivities" - how quickly the scores change as the transformations get more extreme.
By evaluating several popular image quality metrics using this approach, the paper provides insights into which ones are more robust and invariant to common image transformations. This is an important consideration when using these metrics for tasks like image compression, enhancement, or generation.
Technical Explanation
The paper proposes a methodology to quantify the invariance of deep image quality metrics to affine transformations. Affine transformations include operations like rotation, scaling, shearing, and translation that preserve parallel lines.
The key steps are:
- Define a set of affine transformations with varying degrees of intensity.
- Apply these transformations to a large dataset of reference images.
- Compute quality scores using the metrics under test for the original and transformed images.
- Determine perceptual thresholds - the minimum transformation intensity at which the quality score changes significantly.
- Compute sensitivities - the rate of quality score change as transformation intensity increases.
The authors evaluate several popular deep image quality metrics, including SSIM, MS-SSIM, GMSD, VSI, and LPIPS, on this task. Their results show substantial differences in the robustness and invariance properties of these metrics to affine transformations.
The insights from this analysis can inform the selection and application of image quality metrics in various computer vision and image processing tasks, where transformation invariance is an important consideration.
Critical Analysis
The paper provides a thorough and principled methodology for quantifying the invariance properties of image quality metrics. However, a few potential limitations and areas for future research are worth noting:
-
The study is limited to affine transformations, whereas real-world applications may involve a wider range of geometric and photometric distortions. Expanding the analysis to a more comprehensive set of transformations could yield additional insights.
-
The evaluation is conducted on a fixed dataset of reference images. Assessing the generalization of these findings to more diverse image domains would strengthen the conclusions.
-
The paper does not explore the implications of transformation invariance for specific applications, such as image compression or enhancement. Bridging the gap between metric properties and practical performance could provide more actionable guidance for practitioners.
Overall, the paper makes a valuable contribution by introducing a rigorous methodology for evaluating the invariance of image quality metrics. Further research along these lines could lead to more robust and versatile perceptual evaluation tools for a wide range of computer vision and imaging tasks.
Conclusion
This paper presents a novel approach to quantifying the invariance of deep image quality metrics to affine transformations. By defining perceptual thresholds and sensitivities, the researchers provide a principled way to assess the robustness of these metrics to common geometric distortions.
The findings reveal substantial differences in the transformation invariance properties of popular image quality metrics, such as SSIM, MS-SSIM, and LPIPS. This information can guide the selection and application of these metrics in various computer vision and imaging applications, where transformation invariance is a critical consideration.
Overall, this work contributes to the ongoing effort to develop more robust and versatile perceptual evaluation tools for image-related tasks, with potential implications for areas like medical image translation, data-scarce scientific imaging, and beyond.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Invariance of deep image quality metrics to affine transformations
Nuria Alabau-Bosque, Paula Daud'en-Oliver, Jorge Vila-Tom'as, Valero Laparra, Jes'us Malo
Deep architectures are the current state-of-the-art in predicting subjective image quality. Usually, these models are evaluated according to their ability to correlate with human opinion in databases with a range of distortions that may appear in digital media. However, these oversee affine transformations which may represent better the changes in the images actually happening in natural conditions. Humans can be particularly invariant to these natural transformations, as opposed to the digital ones. In this work, we evaluate state-of-the-art deep image quality metrics by assessing their invariance to affine transformations, specifically: rotation, translation, scaling, and changes in spectral illumination. Here invariance of a metric refers to the fact that certain distances should be neglected (considered to be zero) if their values are below a threshold. This is what we call invisibility threshold of a metric. We propose a methodology to assign such invisibility thresholds for any perceptual metric. This methodology involves transformations to a distance space common to any metric, and psychophysical measurements of thresholds in this common space. By doing so, we allow the analyzed metrics to be directly comparable with actual human thresholds. We find that none of the state-of-the-art metrics shows human-like results under this strong test based on invisibility thresholds. This means that tuning the models exclusively to predict the visibility of generic distortions may disregard other properties of human vision as for instance invariances or invisibility thresholds.
Read more7/30/2024

0
Lost in Translation: Modern Neural Networks Still Struggle With Small Realistic Image Transformations
Ofir Shifman, Yair Weiss
Deep neural networks that achieve remarkable performance in image classification have previously been shown to be easily fooled by tiny transformations such as a one pixel translation of the input image. In order to address this problem, two approaches have been proposed in recent years. The first approach suggests using huge datasets together with data augmentation in the hope that a highly varied training set will teach the network to learn to be invariant. The second approach suggests using architectural modifications based on sampling theory to deal explicitly with image translations. In this paper, we show that these approaches still fall short in robustly handling 'natural' image translations that simulate a subtle change in camera orientation. Our findings reveal that a mere one-pixel translation can result in a significant change in the predicted image representation for approximately 40% of the test images in state-of-the-art models (e.g. open-CLIP trained on LAION-2B or DINO-v2) , while models that are explicitly constructed to be robust to cyclic translations can still be fooled with 1 pixel realistic (non-cyclic) translations 11% of the time. We present Robust Inference by Crop Selection: a simple method that can be proven to achieve any desired level of consistency, although with a modest tradeoff with the model's accuracy. Importantly, we demonstrate how employing this method reduces the ability to fool state-of-the-art models with a 1 pixel translation to less than 5% while suffering from only a 1% drop in classification accuracy. Additionally, we show that our method can be easy adjusted to deal with circular shifts as well. In such case we achieve 100% robustness to integer shifts with state-of-the-art accuracy, and with no need for any further training.
Read more4/11/2024
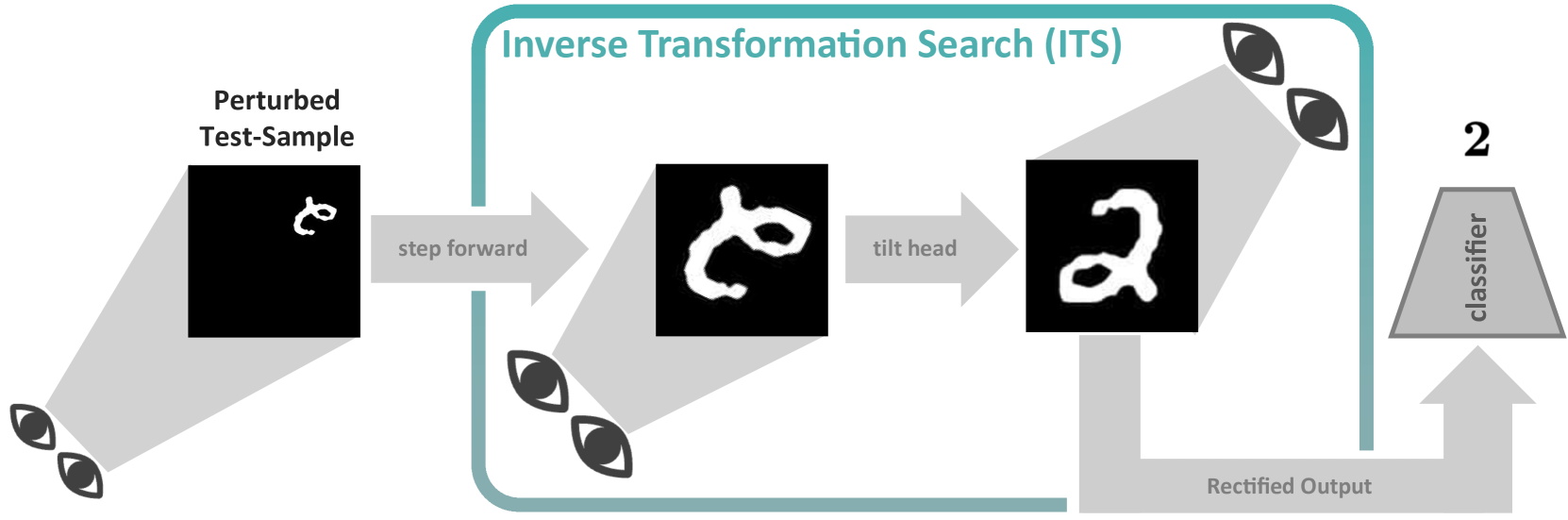
0
Tilt your Head: Activating the Hidden Spatial-Invariance of Classifiers
Johann Schmidt, Sebastian Stober
Deep neural networks are applied in more and more areas of everyday life. However, they still lack essential abilities, such as robustly dealing with spatially transformed input signals. Approaches to mitigate this severe robustness issue are limited to two pathways: Either models are implicitly regularised by increased sample variability (data augmentation) or explicitly constrained by hard-coded inductive biases. The limiting factor of the former is the size of the data space, which renders sufficient sample coverage intractable. The latter is limited by the engineering effort required to develop such inductive biases for every possible scenario. Instead, we take inspiration from human behaviour, where percepts are modified by mental or physical actions during inference. We propose a novel technique to emulate such an inference process for neural nets. This is achieved by traversing a sparsified inverse transformation tree during inference using parallel energy-based evaluations. Our proposed inference algorithm, called Inverse Transformation Search (ITS), is model-agnostic and equips the model with zero-shot pseudo-invariance to spatially transformed inputs. We evaluated our method on several benchmark datasets, including a synthesised ImageNet test set. ITS outperforms the utilised baselines on all zero-shot test scenarios.
Read more5/28/2024
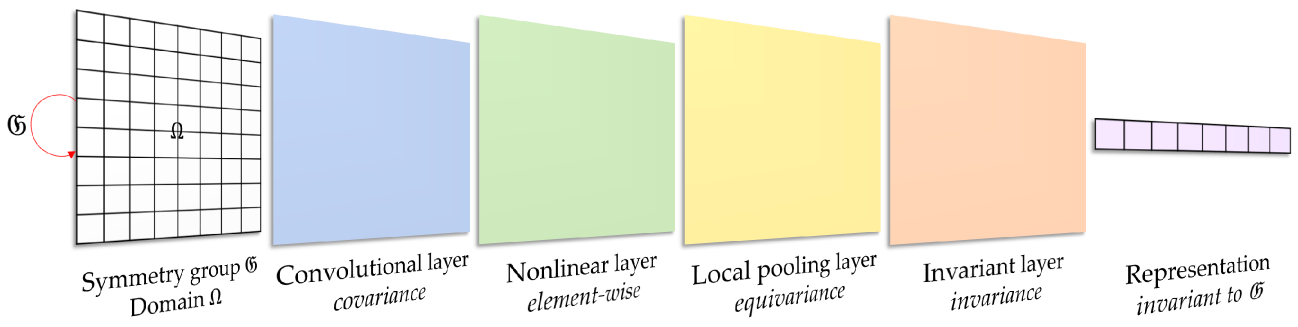
0
Hierarchical Invariance for Robust and Interpretable Vision Tasks at Larger Scales
Shuren Qi, Yushu Zhang, Chao Wang, Zhihua Xia, Xiaochun Cao, Jian Weng
Developing robust and interpretable vision systems is a crucial step towards trustworthy artificial intelligence. In this regard, a promising paradigm considers embedding task-required invariant structures, e.g., geometric invariance, in the fundamental image representation. However, such invariant representations typically exhibit limited discriminability, limiting their applications in larger-scale trustworthy vision tasks. For this open problem, we conduct a systematic investigation of hierarchical invariance, exploring this topic from theoretical, practical, and application perspectives. At the theoretical level, we show how to construct over-complete invariants with a Convolutional Neural Networks (CNN)-like hierarchical architecture yet in a fully interpretable manner. The general blueprint, specific definitions, invariant properties, and numerical implementations are provided. At the practical level, we discuss how to customize this theoretical framework into a given task. With the over-completeness, discriminative features w.r.t. the task can be adaptively formed in a Neural Architecture Search (NAS)-like manner. We demonstrate the above arguments with accuracy, invariance, and efficiency results on texture, digit, and parasite classification experiments. Furthermore, at the application level, our representations are explored in real-world forensics tasks on adversarial perturbations and Artificial Intelligence Generated Content (AIGC). Such applications reveal that the proposed strategy not only realizes the theoretically promised invariance, but also exhibits competitive discriminability even in the era of deep learning. For robust and interpretable vision tasks at larger scales, hierarchical invariant representation can be considered as an effective alternative to traditional CNN and invariants.
Read more4/12/2024